






不用下载资源,文章后面有完整代码
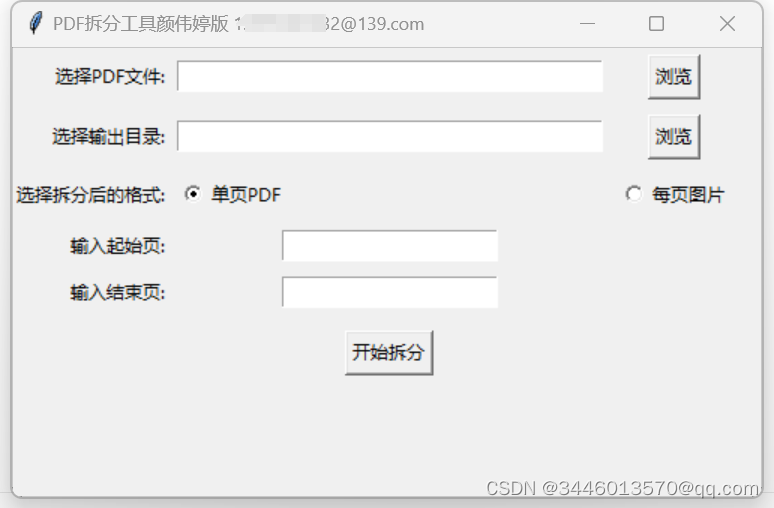
如图(起始页和结束页可以不写,默认为整个pdf):
完整代码:
from PyPDF2 import PdfReader, PdfWriter
import os
import tkinter as tk
from tkinter import filedialog, messagebox
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from PIL import Image
import fitz # PyMuPDF
class PDFSplitterApp:
def __init__(self, master):
self.master = master
self.master.title("PDF拆分工具颜伟婷版 13975335632@139.com")
self.master.minsize(500, 300) # 设置程序主页面的最小宽度和高度
# 创建主页面的 Frame
self.main_frame = tk.Frame(master)
self.main_frame.pack(expand=True, fill=tk.BOTH)
# 选择PDF文件
self.pdf_path_label = tk.Label(self.main_frame, text="选择PDF文件:")
self.pdf_path_label.grid(row=0, column=0, sticky="e")
self.pdf_path_var = tk.StringVar()
self.pdf_path_entry = tk.Entry(self.main_frame, textvariable=self.pdf_path_var, width=40)
self.pdf_path_entry.grid(row=0, column=1, padx=5, pady=5)
self.pdf_browse_button = tk.Button(self.main_frame, text="浏览", command=self.browse_pdf)
self.pdf_browse_button.grid(row=0, column=2, padx=5, pady=5)
# 选择输出目录
self.output_path_label = tk.Label(self.main_frame, text="选择输出目录:")
self.output_path_label.grid(row=1, column=0, sticky="e")
self.output_path_var = tk.StringVar()
self.output_path_entry = tk.Entry(self.main_frame, textvariable=self.output_path_var, width=40)
self.output_path_entry.grid(row=1, column=1, padx=5, pady=5)
self.output_browse_button = tk.Button(self.main_frame, text="浏览", command=self.browse_output)
self.output_browse_button.grid(row=1, column=2, padx=5, pady=5)
# 选择拆分后的格式
self.split_option_label = tk.Label(self.main_frame, text="选择拆分后的格式:")
self.split_option_label.grid(row=2, column=0, sticky="e")
self.split_option_var = tk.StringVar()
self.split_option_var.set("single") # 默认选择 'single'
self.single_button = tk.Radiobutton(self.main_frame, text="单页PDF", variable=self.split_option_var, value="single")
self.single_button.grid(row=2, column=1, padx=5, pady=5, sticky="w")
self.image_button = tk.Radiobutton(self.main_frame, text="每页图片", variable=self.split_option_var, value="image")
self.image_button.grid(row=2, column=2, padx=5, pady=5, sticky="w")
# 输入起始页
self.start_page_label = tk.Label(self.main_frame, text="输入起始页:")
self.start_page_label.grid(row=3, column=0, sticky="e")
self.start_page_var = tk.StringVar()
self.start_page_entry = tk.Entry(self.main_frame, textvariable=self.start_page_var)
self.start_page_entry.grid(row=3, column=1, padx=5, pady=5)
# 输入结束页
self.end_page_label = tk.Label(self.main_frame, text="输入结束页:")
self.end_page_label.grid(row=4, column=0, sticky="e")
self.end_page_var = tk.StringVar()
self.end_page_entry = tk.Entry(self.main_frame, textvariable=self.end_page_var)
self.end_page_entry.grid(row=4, column=1, padx=5, pady=5)
# 开始按钮
self.start_button = tk.Button(self.main_frame, text="开始拆分", command=self.start_split)
self.start_button.grid(row=5, column=1, pady=10)
def browse_pdf(self):
pdf_path = filedialog.askopenfilename(title="选择要拆分的PDF文件", filetypes=[("PDF files", "*.pdf")])
self.pdf_path_var.set(pdf_path)
def browse_output(self):
output_path = filedialog.askdirectory(title="选择输出目录")
self.output_path_var.set(output_path)
def start_split(self):
pdf_path = self.pdf_path_var.get()
output_path = self.output_path_var.get()
split_option = self.split_option_var.get()
# 将用户输入的起始页和结束页转换为整数,如果用户未输入,则为 None
start_page_str = self.start_page_var.get()
end_page_str = self.end_page_var.get()
# 在这里将用户输入的页码减1以符合程序内部的索引
start_page = int(start_page_str) - 1 if start_page_str.strip() else None
end_page = int(end_page_str) - 1 if end_page_str.strip() else None
split_pdf(pdf_path, output_path, split_option, start_page, end_page)
messagebox.showinfo("完成", "PDF拆分完成!请检查输出目录。")
def show_warning(message):
root = tk.Tk()
root.withdraw()
messagebox.showwarning("警告", message)
root.destroy()
def split_pdf(pdf_path, output_path, split_option='single', start_page=None, end_page=None):
try:
# 用户输入验证
if not os.path.isfile(pdf_path):
raise FileNotFoundError("指定的PDF文件不存在。")
if not os.path.isdir(output_path):
raise NotADirectoryError("指定的输出目录不存在。")
# 加载PDF文件
with open(pdf_path, 'rb') as file:
pdf_reader = PdfReader(file)
total_pages = len(pdf_reader.pages)
# 处理特殊情况:起始页大于或等于结束页
if start_page is not None and end_page is not None and start_page >= end_page:
show_warning("起始页不得大于或等于结束页")
return
# 处理特殊情况:只填写了起始页或结束页
start_page = start_page or 0
end_page = end_page or total_pages - 1
# 处理特殊情况:只填写了起始页,默认结束页为最后一页
if start_page is not None and end_page is None:
end_page = total_pages - 1
# 处理特殊情况:只填写了结束页,默认起始页为第一页
if start_page is None and end_page is not None:
start_page = 0
if start_page < 0 or end_page >= total_pages or start_page > end_page:
raise ValueError("指定的拆分页范围不合法。")
for page_num in range(start_page, end_page + 1):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
if split_option == 'single':
# 单页PDF拆分
output_filename = f"{output_path}/{str(page_num + 1).zfill(4)}.pdf"
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
elif split_option == 'image':
# 每页图片拆分
output_filename = f"{output_path}/{str(page_num + 1).zfill(4)}.png"
# 使用 PyMuPDF 将 PDF 页面转换为图像
pdf_document = fitz.open(pdf_path)
pdf_page = pdf_document[page_num]
pix = pdf_page.get_pixmap()
# 创建 PIL Image 对象并保存为 PNG
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
image.save(output_filename, "PNG")
pdf_document.close()
else:
raise ValueError("无效的拆分选项。")
except FileNotFoundError as e:
error_message = f"错误: {e}\n请检查文件路径是否正确。"
print(error_message)
except NotADirectoryError as e:
error_message = f"错误: {e}\n请检查输出目录路径是否正确。"
print(error_message)
except ValueError as e:
error_message = f"错误: {e}\n请检查拆分页范围是否合法。"
print(error_message)
except Exception as e:
error_message = f"发生未知错误: {e}"
print(error_message)
if __name__ == "__main__":
# 在程序开始处,注册字体
# pdfmetrics.registerFont(TTFont('Arial', 'arial.ttf'))
# pdfmetrics.registerFont(TTFont('SimSun', 'simsun.ttc'))
root = tk.Tk()
app = PDFSplitterApp(root)
root.mainloop()
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











