







Reno、Cubic都是基于丢包的拥塞控制算法,Cubic适用场景是高带宽的,但现在丢包不一定是发生拥塞了,比如Bufferbloat(缓冲区膨胀),路由器的缓冲区满了的丢包。
一 基于模型的拥塞控制,分别测BltBw--瓶颈带宽、RTprop--即RTT。
图是google论文里的。
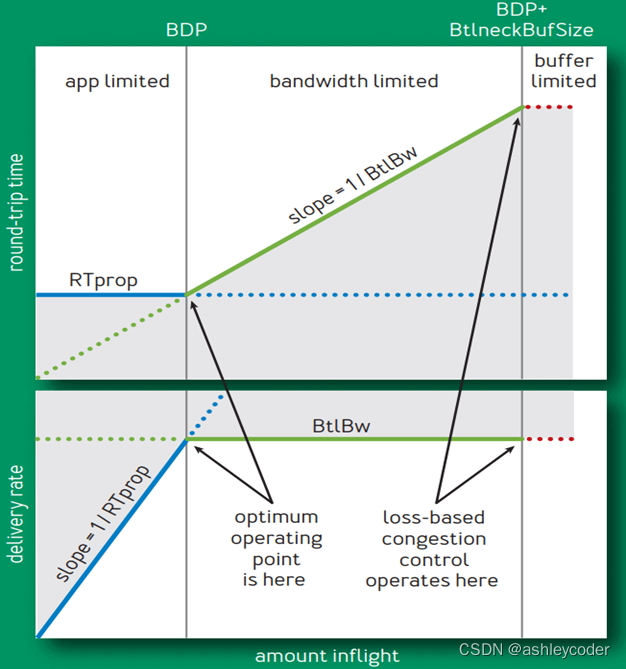
分为:应用受限--测RTT--管道没满、
带宽受限--测BltBw--管道满了,缓存没满,
缓存受限--管道满了,缓存满了。
(tcp_bbr.c的英文注释挺有帮助的。)
On each ACK, update our model of the network path:
bottleneck_bandwidth = windowed_max(delivered / elapsed, 10 round trips)
min_rtt = windowed_min(rtt, 10 seconds)
pacing_rate = pacing_gain * bottleneck_bandwidth
cwnd = max(cwnd_gain * bottleneck_bandwidth * min_rtt, 4)
//最后作用于发送拥塞窗口。
/*A BBR flow starts in STARTUP, and ramps up its sending rate quickly.
* When it estimates the pipe is full, it enters DRAIN to drain the queue.
* In steady state a BBR flow only uses PROBE_BW and PROBE_RTT.
* A long-lived BBR flow spends the vast majority of its time remaining
* (repeatedly) in PROBE_BW, fully probing and utilizing the pipe's bandwidth
* in a fair manner, with a small, bounded queue. *If* a flow has been
* continuously sending for the entire min_rtt window, and hasn't seen an RTT
* sample that matches or decreases its min_rtt estimate for 10 seconds, then
* it briefly enters PROBE_RTT to cut inflight to a minimum value to re-probe
* the path's two-way propagation delay (min_rtt). When exiting PROBE_RTT, if
* we estimated that we reached the full bw of the pipe then we enter PROBE_BW;
* otherwise we enter STARTUP to try to fill the pipe.
*/二 四种状态机:
1 Startup:快速增速,使管道充满数据。3次增速不超过25%,进入Drain。
static const u32 bbr_full_bw_thresh = BBR_UNIT * 5 / 4;
2 Drain:清空Startup阶段多余的队列数据。inflight<=BDP,进入Probe_BW。
BDP=瓶颈带宽*RTT。
3 Probe_BW:大部分处于这个稳定状态,10s,min_rtt不变,进入Probe_RTT。
4 Probe_RTT:探测带宽是最大值,回到Probe_BW。持续200ms,snd_cwnd=4。
static const u32 bbr_cwnd_min_target = 4;
static const u32 bbr_probe_rtt_mode_ms = 200;
static const u32 bbr_min_rtt_win_sec = 10;
三 调整参数
pacing_gain=2.89,这个值变化过,优化后取2,因为接收方不是一收到数据就给一个确认。
Startup:pacing_gain= cwnd_gain=2.89。
Drain:pacing_gain =0.35,cwnd_gain=2.89。
Probe_bw:pacing_gain =[1.25,0.75,1,1,1,1,1,1],cwnd_gain=2。
Probe_rtt:pacing_gain= cwnd_gain=1,cwnd固定为4。
Probe_bw如何探测?
一组8个节拍
pacing_gain=1.25,RTT没变大,BltBW更新为更大的速率。RTT变大,BltBW不变。
pacing_gain=0.75,0.75倍BDP,放空管道的buffer。
bbr_is_next_cycle_phase(struct sock *sk,
const struct rate_sample *rs)
满足条件,cycle_idx+1,bbr_check_full_bw_reached、bbr_check_drain、bbr_update_min_rtt、
bbr_update_gains。
如何pacing?
/* NOTE: BBR might be used with the fq qdisc ("man tc-fq") with pacing enabled,
* otherwise TCP stack falls back to an internal pacing using one high
* resolution timer per TCP socket and may use more resources.
*/
1 tcp主动pacing,设置为SK_PACING_NEEDED。耗cpu,默认方式。
cmpxchg(&sk->sk_pacing_status, SK_PACING_NONE, SK_PACING_NEEDED);
2 依赖tc-fq的pacing。
tc qdisc add dev xxx root fq //enable fq
四 其它
RTT状态下不参与BW最大值计算。
当监测到使用令牌桶算法时,直接使用长期采样,避免频繁采样。
函数是bbr_lt_bw_sampling。
疑问:windows端到linux服务器,这部分怎么优化?
还是网络延时主要是服务器之间传输的优化?
五 BBR2优化点
1 bbr v1和reno一起,抢占带宽太厉害了,从90%到50%。
Drain排空一次到位。
退出Startup条件:1 丢包大于1%且丢包8个,进入drain。
2 路由器标记ECN的比例超过50%。
2 cwnd=4太影响体验了,改为:inflight = 0.75 bdp,在Probe_RTT状态。
进入Probe_RTT改为:2.5秒没有探测到更小的min_rtt,原来是10s。
3 Probe_BW细分up、down、cruise—巡航、refill。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









