







文章目录
最近在网上看了不少介绍Java虚拟机(JVM)的文章,但总觉得看完之后一知半解。所以决定阅读官方文档,按照自己的理解来写几篇(可能是两篇)文章介绍JVM。首先简单介绍一下JVM,然后重点讲JVM的垃圾回收机制。
1. JVM是什么
每个Java程序员都知道字节码将由Java运行时环境即 JRE(Java Runtime Environment)来执行。但许多人不知道 JRE是 JVM的实现。JVM分析字节码,解析字节码,然后执行它。
虚拟机是物理机器的软件实现。Java是根据 WORA(Write Once Run Anywhere)原则开发的,即同一套代码可以在多种系统上运行,因为它运行在虚拟机(即JVM)上。编译器把Java文件编译成Java .class文件,然后交由JVM来加载和运行。
2. JVM架构概览
我们先上一张JVM的架构图:
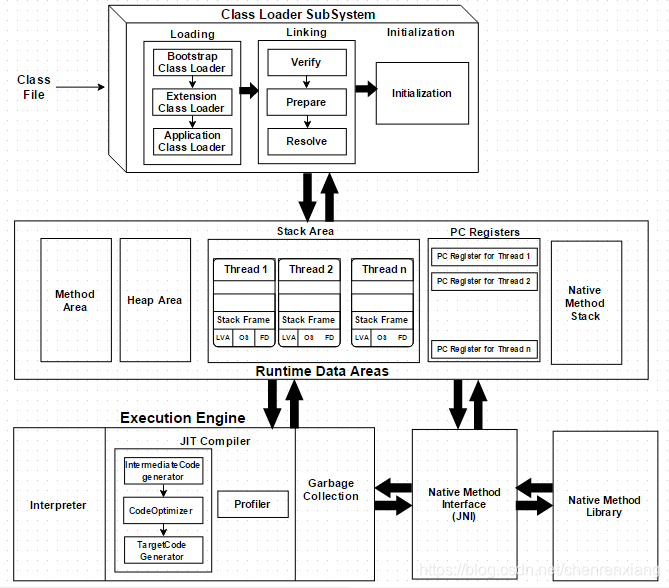
由上图可以知道,JVM主要有三个功能模块:
- 类加载子系统 (Class Loader SubSystem):负责把编译好的 .class文件加载到JVM中。
- 运行时数据区 (RuntimeData Areas):存储类、变量、方法等各种信息和代码执行过程中产生的数据。
- 执行引擎 (Execution Engine):读取并执行字节代码。
下面我们将分别介绍这三个模块。
3. 类加载子系统 (ClassLoader Subsystem)
Java的动态类加载功能是由类加载子系统来处理的。在运行时(不是编译时),当首次引用一个类时,类加载子系统将 加载(loading)、连接(linking)、初始化(initialization)其class文件。
加载 Loading
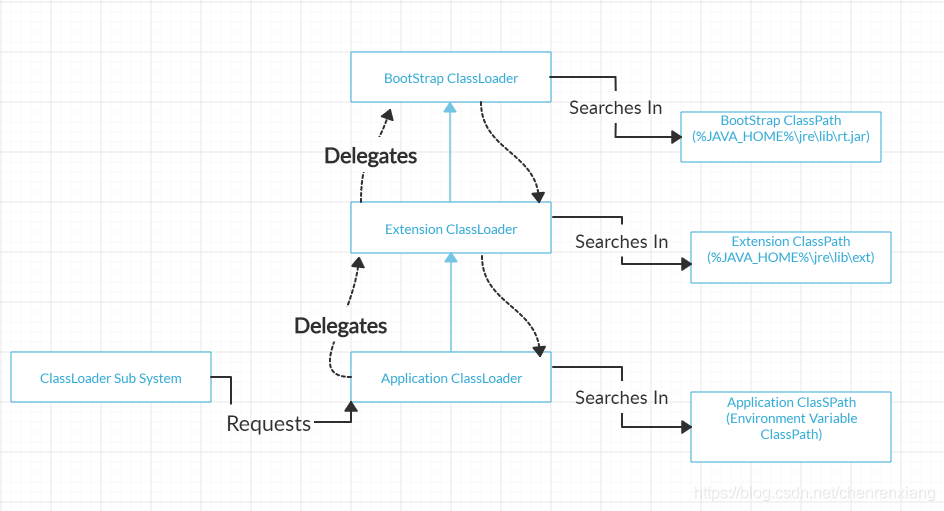
加载过程将由启动类加载器(BootStrap ClassLoader)、扩展类加载器(Extention ClassLoader)和 应用类加载器(Application ClassLoader)共同完成。
- 启动类加载器: 这是顶级类加载器并且是
扩展类加载器的上一级,负责加载rt.jar文件。rt.jar文件包含所有Java标准库的类文件,比如java.lang包、java.net包、java.util包、java.io包等等。 - 扩展类加载器:是
启动类加载器的下一级,并且是应用类加载器的上一级,负责加载位于$JAVA_HOME/jre/lib/ext目录下的jar文件。 - 应用类加载器:它是
扩展类加载器的下一级,负责加载应用程序的类路径和环境变量中指定的路径下的class文件。
以上的加载器在加载类文件的时候遵循 委托层次算法(Delegation Hierarchy Algorithm)。这是什么意思呢? 我们上面已经介绍了三种类加载器的级别关系,当类加载器收到类加载的请求,它会先把该请求委托给上一级加载器,并向上传递,最终请求都会传递到顶层的启动类加载器中。只有当上级加载器无法完成该加载请求,下级的加载器才会尝试自己去加载。如果到最后都无法实现该类的加载,就会抛出ClassNotFoundException异常。
加载器工作流程图如下:
连接 Linking
连接包含三个步骤:验证(Verification)、准备(Preparation)和 解析(Resolution)
- 验证:确保.class文件的正确性。比如,检查该文件的格式是否正确,是否由有效的编译器生成。如果验证失败,将抛出运行时异常
java.lang.VerifyError - 准备:为所有的类变量(静态变量)分配内存并赋予默认值。
- 解析:把方法区的所有符号引用替换为直接引用,此操作是通过搜索方法区域找到引用实体来完成的。
初始化 Intialization
这是类加载的最后一个阶段。该阶段会按照代码的定义来初始化类变量(静态变量),即会执行初始化静态变量的代码。该过程的执行顺序为代码的从上至下、先父类后子类。比如:当初始化一个类的时候,若发现其父类还未进行初始化,会先触发其父类的初始化。
4. 运行时数据区 Runtime Data Area
运行时数据区可分为五个主要的功能块:
- 方法区(Method Area):所有类级别的信息,比如类名、直接父类名、类中的方法和变量的信息,包括静态变量等都会被存储在方法区。每个JVM里只有一个方法区,它是共享资源。
- 堆区(Heap Area):所有的对象(Objects)和其相应的实例变量以及数组都被存储在堆区。每个JVM里也只有一个堆区,它也是共享资源。由于方法区和堆区共享多个线程的内存,因此存储的数据不是线程安全的。
- 栈区(Stack Area):对于每个线程,会创建一个独立的运行时栈。对于每个方法调用,栈内存会为其创建一个
栈帧(Stack Frame)。由于栈区不是共享资源,因此它是线程安全的。栈帧是用于支持虚拟机进行方法调用和执行的数据结构,栈帧中储存着方法的局部变量表、操作栈、动态链接、返回地址以及一些额外的附加信息。每个方法从调用到执行完成的过程就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
- 程序计数器(Program Counter Registers):每个线程有单独的程序计数器,用以保存当前的执行指令地址。
- 本地方法栈(Native Method Stacks):本地方法栈用于保存本地方法信息。每一个线程都会有一个对应的本地方法栈。
5. 执行引擎 Execution Engine
分配给运行时数据区的字节码将由执行引擎执行。执行引擎逐行读取字节码,使用存储在各个存储区中的数据和信息并执行指令。它可以分为三个部分:
- 解析器(Interpreter):它用于逐行解析字节码并执行。解析器有一个缺点,如果一个方法被多次调用,那么它将作多次解析。
- 即时编译器(Just-In-Time Compiler 或 JIT):用于提高解析器的效率。它编译整个字节码并将其变为本地代码。当解析器遇到重复的方法调用时,JIT直接提供本地代码,从而避免重复解析,提高解析器效率。
- 垃圾回收器(Garbage Collector):负责回收不再被引用的对象,以清理内存空间。
本地编程接口 Java Native Interface
JNI用于和本地方法库交互,并给执行引擎提供其所需的本地类库。它使得在Java虚拟机内部运行的Java代码能够与用其它编程语言(如C、C++ 和汇编语言)编写的应用程序和库进行交互操作。
本地方法库 Native Method Libraries
执行引擎所需的本地方法库。
参考的文章:














 1979
1979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









