







-
-
- 网页分析
-
进入Network在众多响应中寻找和弹幕相关的API,
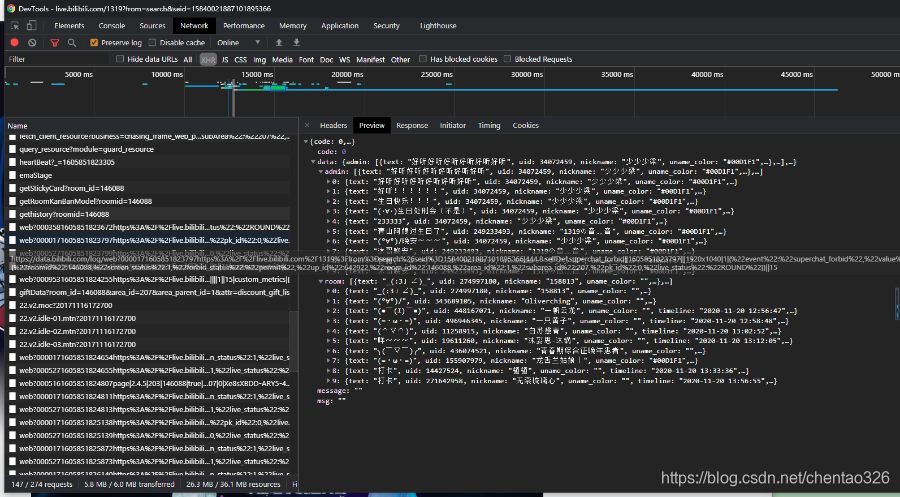
图3-1 B站直播房间页面的开发者工具界面preview
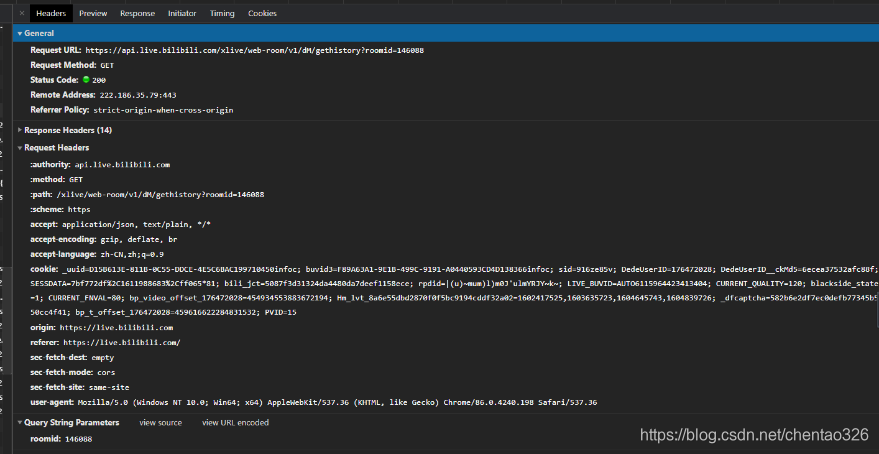
图3-2
在3-2展示的页面中可以查看到URL中有参数roomid,
在获取到url、相关参数以及headers后,通过requests.post()获取解析直播间弹幕。结果如图3-3:
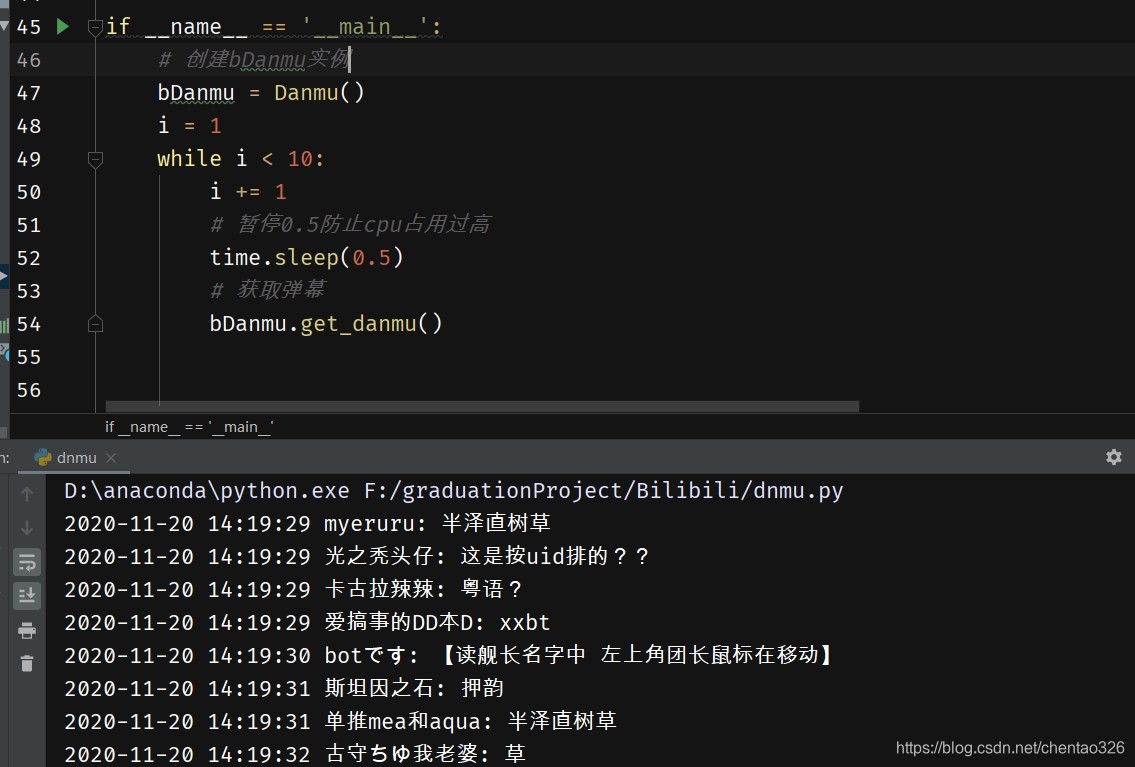
图3-3 获取的部分弹幕
| import requests import time import io,sys |
- 定义Danmu类
其中包含了url,请求头headers,POST传递的参数以及get_danmu()方法。在headers中可以增加更多header中的参数,增加不被反爬机制发现的可能性。关键代码如下:
| def __init__(self): # 弹幕url self.url = 'https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory' # 请求头 self.headers = { 'Host': 'api.live.bilibili.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0', } # 定义POST传递的参数 self.data = { 'roomid': ' 21396545', 'csrf_token': '', 'csrf': '', 'visit_id': '', } |
- 构造get_danmu()方法
| def get_danmu(self): # 获取直播间弹幕 html = requests.post(url=self.url, headers=self.headers, data=self.data).json() # 解析弹幕列表 for content in html['data']['room']: # 获取昵称 nickname = content['nickname'] # 获取发言 text = content['text'] # 获取发言时间 timeline = content['timeline'] # 记录发言 msg = timeline + ' ' + nickname + ': ' + text print(msg) |
# -*- encoding: utf-8 -*-
#@time: 2020/11/15 22:54
#@author: chenTao
#@file: dnmu.py
import requests
import time
import io,sys
# import
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
class Danmu():
def __init__(self):
# 弹幕url
self.url = 'https://api.live.bilibili.com/xlive/web-room/v1/dM/gethistory'
# 请求头
self.headers = {
'Host': 'api.live.bilibili.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0',
}
# 定义POST传递的参数
self.data = {
'roomid': '21396545',
'csrf_token': '',
'csrf': '',
'visit_id': '',
}
def get_danmu(self):
# 获取直播间弹幕
html = requests.post(url=self.url, headers=self.headers, data=self.data).json()
# 解析弹幕列表
for content in html['data']['room']:
# 获取昵称
nickname = content['nickname']
# 获取发言
text = content['text']
# 获取发言时间
timeline = content['timeline']
# 记录发言
msg = timeline + ' ' + nickname + ': ' + text
print(msg)
if __name__ == '__main__':
# 创建bDanmu实例
bDanmu = Danmu()
i = 1
while i < 10:
i += 1
# 暂停0.5防止cpu占用过高
time.sleep(0.5)
# 获取弹幕
bDanmu.get_danmu()

















 2100
2100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









