








Python中的随机森林
随机森林是一种用途广泛的机器学习方法,具有广泛的应用范围,从营销到医疗和保险。它可以用来模拟营销对客户获取,保留和流失的影响,或者预测患者的疾病风险和易感性。
随机森林能够回归和分类。它可以处理大量的功能,并且有助于估计哪些变量对正在建模的基础数据非常重要。
这是一篇关于使用Python的随机森林的文章。
什么是随机森林?
随机森林是几乎任何预测问题(甚至非线性问题)的可靠选择。这是一个相对较新的机器学习策略(它在90年代出现在贝尔实验室),它可以用于任何事情。它属于更大类的机器学习算法,称为集成方法。
集成学习
集成学习涉及多个模型的组合以解决单个预测问题。它通过生成多个分类器/模型来独立学习和预测。然后将这些预测合并成一个单一的(兆)预测,应该与任何一个分类器所做的预测一样好或更好。
随机决策树
所以我们知道随机森林是其他模型的集合,但是它聚合的是什么类型的模型呢?正如你可能已经猜到它的名字,随机森林聚合分类(或回归)树。决策树由一系列决策组成,可以用来对数据集中的观察进行分类。
随机森林
诱导随机森林的算法会自动产生一堆随机决策树。由于树是随机生成的,所以大部分对于学习分类/回归问题(可能是99.9%的树)都没有多大意义。

如果观察长度为45,蓝眼睛,2腿,则将被分类为红色。
投票
那么10000(可能)不好的模型有什么好处呢?事实证明,他们真的没有那么有用。但是有一些非常有用的决策树也可以与坏的决策树一起生成。
当你进行预测时,新的观察结果被推下每个决策树,并分配一个预测值/标签。一旦森林中的每棵树都报告了它的预测值/标签,则预测被汇总,并且所有树的模式投票被返回作为最终的预测。
简单地说,99.9%的无关树木在全地图上进行预测,相互抵消。少数优秀的树木的预测能够预测噪音并产生良好的预测。
为什么我应该使用它?
容易
随机森林是学习方法的Leatherman。你可以扔任何东西给它,它会做一个有用的工作。它在估计推断变换方面做得非常好,因此不需要像SVM那样进行很多调整(即对于时间紧迫的人来说是好的)。
一个例子转换
随机森林能够在没有精心设计的数据转换的情况下学习。以 f(x) = log(x)功能为例。
好吧,让我们写一些代码。我们将在Yhat自己的用于分析数据的互动环境中编写我们的Python代码,Rodeo。您可以下载Rodeo for Mac,Windows或Linux [这里](https://www.yhat.com/products/rodeo)。
首先,创建一些伪造的数据并添加一点噪音。
import numpy as np
import pylab as pl
x = np.random.uniform(1, 100, 1000)
y = np.log(x) + np.random.normal(0, .3, 1000)
pl.scatter(x, y, s=1, label="log(x) with noise")
pl.plot(np.arange(1, 100), np.log(np.arange(1, 100)), c="b", label="log(x) true function")
pl.xlabel("x")
pl.ylabel("f(x) = log(x)")
pl.legend(loc="best")
pl.title("A Basic Log Function")
pl.show() 继在Rodeo?这是你应该看到的。
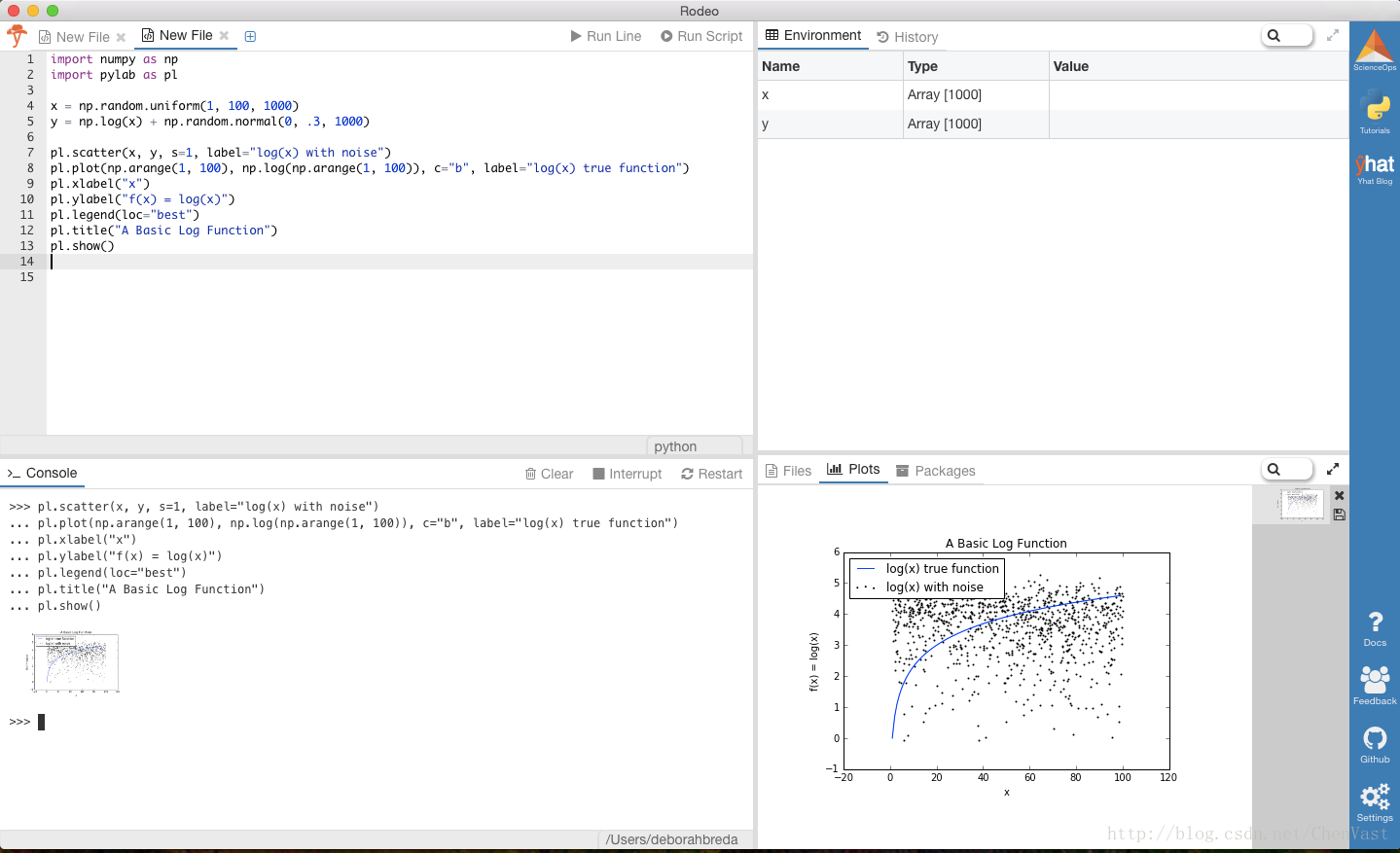

如果我们尝试建立一个基本的线性模型来预测y使用,x我们用一条直线来排列log(x)函数。而如果我们使用一个随机森林,它在log(x)曲线近似方面做得更好,我们得到的东西更像真正的函数。
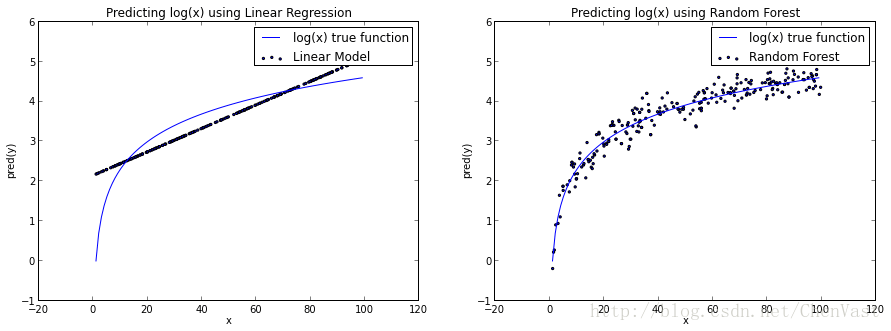
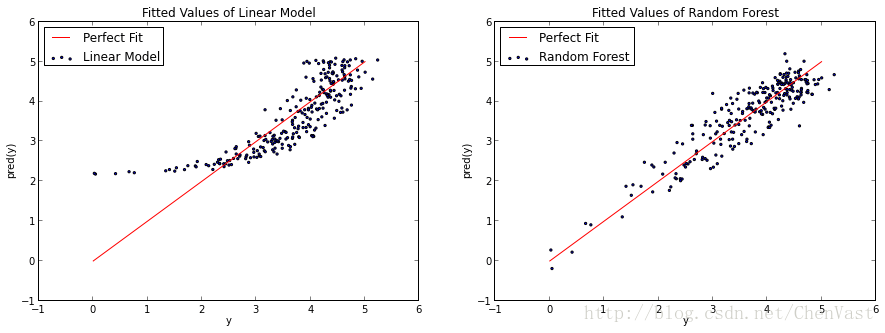
你可以争辩说,随机森林有点过分的适应了这个log(x)函数。无论哪种方式,我认为这很好地说明了随机森林不受线性约束的限制。
用途
变量选择
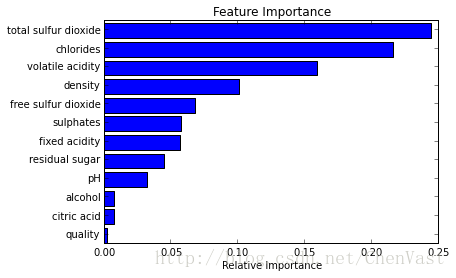
随机森林的最佳用例之一是特征选择。尝试大量决策树变化的副产品之一是您可以检查哪些变量在每个树中工作最好/最差。
当某个树使用一个变量而另一个不使用时,可以比较从该变量的包含/排除中丢失或获得的值。好的随机森林实现将为你做,所以你所需要做的就是知道要查看哪个方法或变量。
在下面的例子中,我们试图找出哪些变量是最重要的葡萄酒分类为红色或白色。
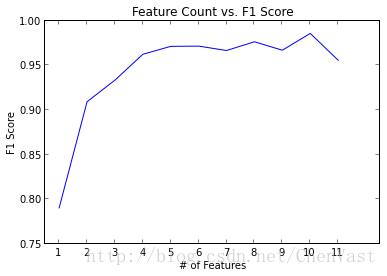
分类
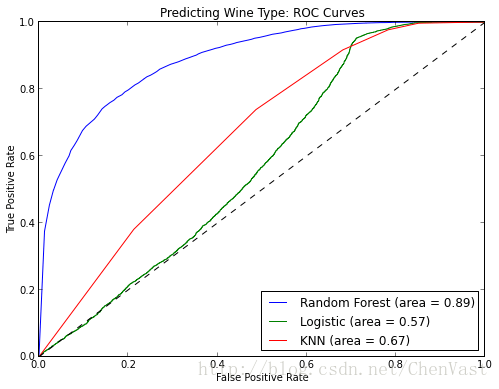
随机森林也是很好的分类。它可以用于对具有多个可能值的类别进行预测,并且可以对其进行校准以输出概率。你需要注意的一件事是过拟合。随机森林可能容易过度拟合,尤其是在处理相对较小的数据集时。如果你的模型对我们的测试集做出“太好”的预测,你应该怀疑。
过拟合的一种方法是在模型中只使用真正相关的特征。虽然这并不总是切割和干燥,但使用特征选择技术(如之前提到的技术)可以使其更容易。
回归
是的。它也能用于回归问题。
我发现,随机森林不像其他算法,确实很好地学习分类变量或分类和实际变量的混合。具有高基数(可能值的)的分类变量可能会非常棘手,所以在后面的口袋里有这样的东西可能会非常有用。
一个简短的Python例子
Scikit-Learn是开始随机森林的好方法。scikit-learn API在算法上是非常一致的,所以你可以很容易地在模型之间进行比赛和切换。很多时候我从简单的事情开始,然后移动到随机森林。
scikit-learn中随机森林实现的最好特征之一就是n_jobs参数。这将根据您想要使用的核心数量自动并行化您的随机森林。这是一个伟大的演讲由scikit学习贡献者奥利维尔GRISEL,他谈到一个20节点集群EC2上训练随机森林。
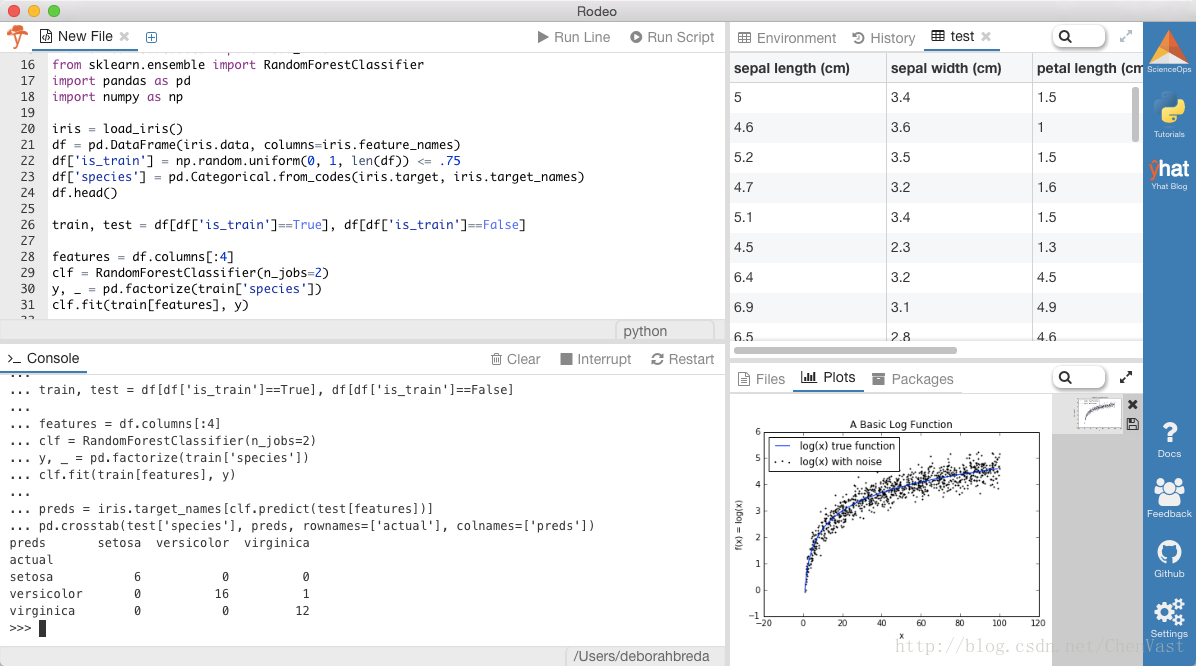
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])这是你应该看到的。 我们使用随机选择的数据,所以你的确切值会每次都有所不同。
最后的想法
鉴于随机森林的先进程度,使用起来非常容易。与任何建模一样,要小心过度配合。如果您有兴趣随机入森林R,请查看randomForest包装。
原文:http://blog.yhat.com/posts/python-random-forest.html














 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









