







Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
本文介绍了flink关于分布式缓存的使用示例,比较简单。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本示例需要hadoop环境可用。
本专题分为以下几篇文章:
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(1) - File、Socket、console
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(2) - jdbc/mysql
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(3) - redis
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(4) - clickhouse
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(5) - kafka
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(6) - 分布式缓存
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(7) - 广播变量
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(8) - 完整版
一、maven依赖
为避免篇幅过长,所有基础依赖均在第一篇文章中列出,具体依赖参考文章
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(1) - File、Socket、console中的依赖
下文中具体需要的依赖将在介绍时添加新增的依赖。
二、分布式缓存(Distributed Cache)示例
1、介绍
Flink提供了一个类似于Hadoop的分布式缓存,以使用户函数的并行实例可以在本地访问文件。此功能可用于共享包含静态外部数据(如字典或机器学习回归模型)的文件。
关于hadoop分布式缓存参考:19、Join操作map side join 和 reduce side join
缓存的工作方式如下:
- 程序在其ExecutionEnvironment中以特定名称将本地或远程文件系统(如HDFS或S3)的文件或目录注册为缓存文件。
- 当程序执行时,Flink会自动将文件或目录复制到所有工作程序的本地文件系统。
- 用户函数可以查找指定名称下的文件或目录,并从工作者的本地文件系统访问它。
官方示例代码
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// register a file from HDFS
env.registerCachedFile("hdfs:///path/to/your/file", "hdfsFile");
// register a local executable file (script, executable, ...)
env.registerCachedFile("file:///path/to/exec/file", "localExecFile", true);
// define your program and execute
...
DataSet<String> input = ...;
DataSet<Integer> result = input.map(new MyMapper());
...
env.execute();
访问用户函数(此处为MapFunction)中的缓存文件。函数必须扩展RichFunction类,因为它需要访问RuntimeContext。
// extend a RichFunction to have access to the RuntimeContext
public final class MyMapper extends RichMapFunction<String, Integer> {
@Override
public void open(Configuration config) {
// access cached file via RuntimeContext and DistributedCache
File myFile = getRuntimeContext().getDistributedCache().getFile("hdfsFile");
// read the file (or navigate the directory)
...
}
@Override
public Integer map(String value) throws Exception {
// use content of cached file
...
}
}
2、maven依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.4</version>
</dependency>
3、实现
import java.io.File;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import akka.japi.tuple.Tuple4;
/**
* @author alanchan
*
*/
public class DistributedCacheSink {
public static void main(String[] args) throws Exception {
// env
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Source
// 注册分布式缓存文件
env.registerCachedFile("hdfs://server2:8020//flinktest/words/goodsDistributedCacheFile", "goodsDistributedCacheFile");
// order数据集(id,name,goodsid)
DataSource<Tuple3<Integer, String, Integer>> ordersDS = env
.fromCollection(Arrays.asList(Tuple3.of(1, "alanchanchn", 1), Tuple3.of(2, "alanchan", 4), Tuple3.of(3, "alan", 123)));
// Transformation
// 将ordersDS(id,name,goodsid)中的数据和分布式缓存中goodsDistributedCacheFile的数据(goodsid,goodsname)关联,得到这样格式的数据: (id,name,goodsid,goodsname)
MapOperator<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, Integer, String>> result = ordersDS
// public abstract class RichMapFunction<IN, OUT> extends AbstractRichFunction
// implements MapFunction<IN, OUT> {
// @Override
// public abstract OUT map(IN value) throws Exception;
// }
.map(new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple4<Integer, String, Integer, String>>() {
// 获取缓存数据,并存储,具体以实际应用为准
Map<Integer, String> goodsMap = new HashMap<>();
//读取缓存数据,并放入本地数据结构中
@Override
public void open(Configuration parameters) throws Exception {
// 加载分布式缓存文件
File file = getRuntimeContext().getDistributedCache().getFile("goodsDistributedCacheFile");
List<String> goodsList = FileUtils.readLines(file);
for (String str : goodsList) {
String[] arr = str.split(",");
goodsMap.put(Integer.parseInt(arr[0]), arr[1]);
}
}
//关联数据,并输出需要的数据结构
@Override
public Tuple4<Integer, String, Integer, String> map(Tuple3<Integer, String, Integer> value) throws Exception {
// 使用分布式缓存文件中的数据
// 返回(id,name,goodsid,goodsname)
return new Tuple4(value.f0, value.f1, value.f2, goodsMap.get(value.f2));
}
});
// Sink
result.print();
}
}
4、验证
1)、验证步骤
1、准备分布式文件及其内容,并上传至hdfs中
2、运行程序,查看输出
2)、验证
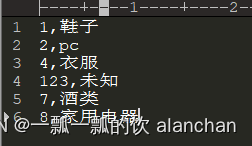
1、缓存文件内容
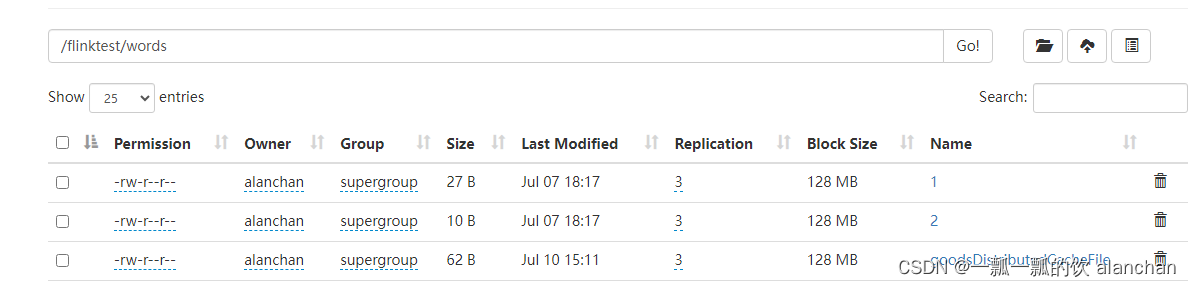
2、上传至hdfs
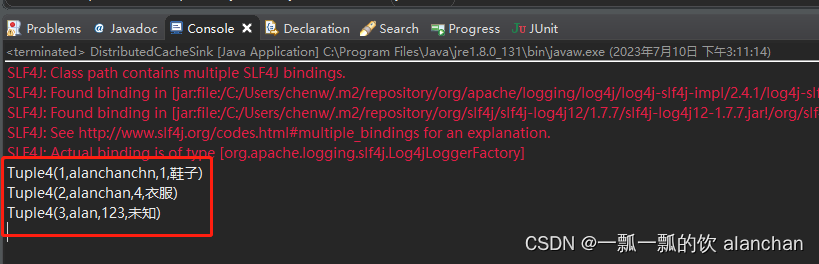
3、运行程序,查看结果
以上,本文介绍了flink关于分布式缓存的使用示例,比较简单。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(1) - File、Socket、console
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(2) - jdbc/mysql
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(3) - redis
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(4) - clickhouse
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(5) - kafka
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(6) - 分布式缓存
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(7) - 广播变量
【flink番外篇】4、flink的sink(内置、mysql、kafka、redis、clickhouse、分布式缓存、广播变量)介绍及示例(8) - 完整版

















 4145
4145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











