







本章介绍输入/输出机制、文件系统相关任务以及相关模块(如 IO、File 和 Path)。IO 系统提供了一个很好的机会来阐明 Elixir 和 Erlang VM 的一些思维模式和新奇思想。
输入输出模块
输入输出模块是 Elixir 中读写标准输入/输出 (:stdio)、标准错误 (:stderr)、文件和其他输入输出设备的主要机制。该模块的使用非常简单:

默认情况下,输入输出模块中的函数从标准输入读取并写入标准输出。我们可以通过传递 :stderr 作为参数(以便写入标准错误设备)来更改此设置:

文件模块
文件模块包含允许我们将文件作为输入输出设备打开的函数。默认情况下,文件以二进制模式打开,这要求开发人员使用输入输出模块中的特定 IO.binread/2 和 IO.binwrite/2 函数:
潜在数据丢失警告
以下代码打开一个文件进行写入。如果给定路径上有现有文件,则将删除其内容。
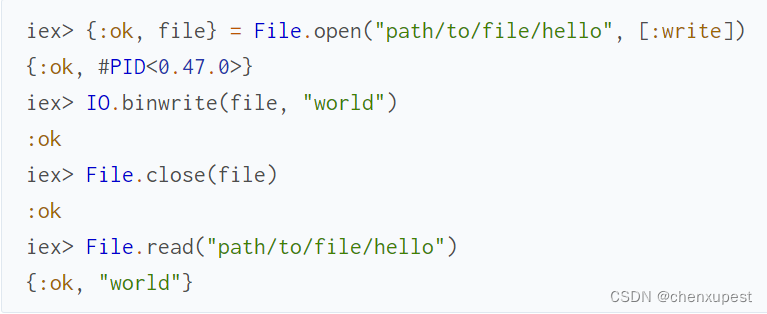
可以使用 :append 选项而不是 :write 打开文件以保留其内容。您还可以传递 :utf8 选项,该选项告诉 File 模块将从文件读取的字节解释为 UTF-8 编码的字节。
除了用于打开、读取和写入文件的函数外,File 模块还有许多用于文件系统的函数。这些函数以它们的 UNIX 等效函数命名。例如,File.rm/1 可用于删除文件,File.mkdir/1 可用于创建目录,File.mkdir_p/1 可用于创建目录及其所有父链。甚至还有 File.cp_r/2 和 File.rm_rf/1 分别用于递归复制和删除文件和目录(即,也复制和删除目录的内容)。
您还会注意到 File 模块中的函数有两种变体:一种是“常规”变体,另一种是带有尾随感叹号 (!) 的变体。例如,当我们读取上面示例中的“hello”文件时,我们使用 File.read/1。或者,我们可以使用 File.read!/1:

请注意,带有 ! 的版本返回文件的内容而不是元组,如果出现任何问题,该函数会引发错误。
没有 ! 的版本当您想使用模式匹配处理不同的结果时,是首选:
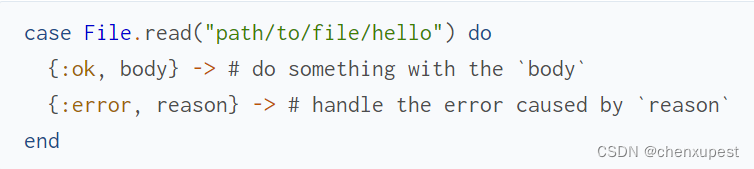
但是,如果您希望文件在那里,则感叹号变体更有用,因为它会引发有意义的错误消息。避免写:

因为,如果发生错误,File.read/1 将返回 {:error,reason},并且模式匹配将失败。您仍将获得所需的结果(引发错误),但消息将与不匹配的模式有关(因此对于错误的具体含义却一无所知)。
因此,如果您不想处理错误结果,请优先使用以感叹号结尾的函数,例如 File.read!/1。
路径模块
文件模块中的大多数函数都要求将路径作为参数。最常见的是,这些路径将是常规二进制文件。路径模块提供了处理此类路径的功能:

最好使用路径模块中的函数,而不是直接操作字符串,因为路径模块可以透明地处理不同的操作系统。最后,请记住,在 Windows 上执行文件操作时,Elixir 会自动将斜杠 (/) 转换为反斜杠 (\)。
至此,我们介绍了 Elixir 提供的用于处理输入输出和与文件系统交互的主要模块。在下一节中,我们将深入了解一下,并了解输入输出系统如何在 VM 中实现。
进程
您可能已经注意到 File.open/2 返回一个类似 {:ok, pid} 的元组:

发生这种情况是因为输入输出模块实际上与进程一起工作(请参阅上一章)。假设文件是一个进程,当您写入已关闭的文件时,实际上是在向已终止的进程发送一条消息:
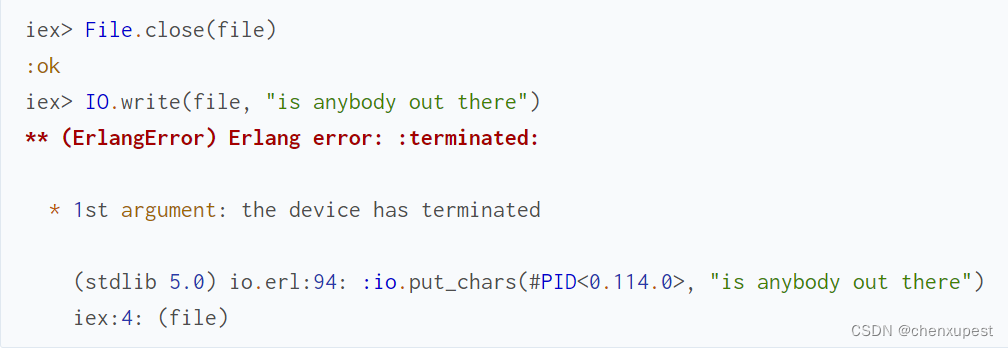
让我们更详细地了解当您请求 IO.write(pid, binary) 时会发生什么。输入输出模块向 pid 标识的进程发送一条消息,其中包含所需的操作。一个小的临时进程可以帮助我们看到它:
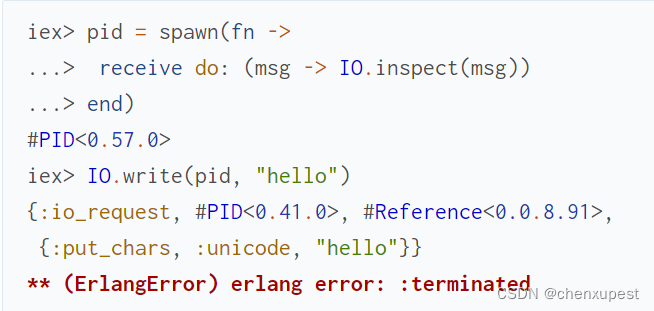
在 IO.write/2 之后,我们可以看到打印出来的输入输出模块发送的请求(一个四元素元组)。不久之后,我们看到它失败了,因为输入输出模块期望某种结果,而我们没有提供。
通过使用进程对输入输出设备进行建模,Erlang VM 甚至允许我们跨节点读取和写入文件。太棒了!
iodata 和 chardata
在上面的所有示例中,我们在写入文件时都使用了二进制文件。但是,Elixir 中的大多数 IO 函数也接受“iodata”或“chardata”。
使用“iodata”和“chardata”的主要原因之一是性能。例如,假设您需要在应用程序中向某人打招呼:
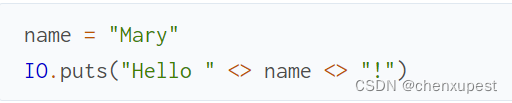
由于 Elixir 中的字符串是不可变的,与大多数数据结构一样,上面的示例会将字符串“Mary”复制到新的“Hello Mary!”字符串中。虽然这对于上面的短字符串来说不太可能,但对于大字符串来说,复制可能非常昂贵!因此,Elixir 中的 IO 函数允许您传递字符串列表:

在上面的示例中,没有复制。相反,我们创建一个包含原始名称的列表。我们将此类列表称为“iodata”或“chardata”,我们很快就会了解它们之间的确切区别。
这些列表非常有用,因为它实际上可以在几种情况下简化字符串的处理。例如,假设您有一个值列表,例如 [“apple”、“banana”、“lemon”],您希望用逗号分隔这些值写入磁盘。您如何实现这一点?
一种方式是使用 Enum.join/2 并将值转换为字符串:

以上通过将每个值复制到新字符串中来返回一个新字符串。但是,有了本节中的知识,我们知道我们可以将字符串列表传递给 IO/File 函数。因此我们可以这样做:

"iodata" 和 "chardata" 不仅包含字符串,还可能包含任意嵌套的字符串列表:

"iodata" 和 "chardata" 也可能包含整数。例如,我们可以使用 ? 作为分隔符来打印以逗号分隔的值列表,该分隔符表示逗号 (44):

"iodata" 和 "chardata" 之间的区别正是所述整数所代表的内容。对于 iodata,整数表示字节。对于 chardata,整数表示 Unicode 码位。对于 ASCII 字符,字节表示与码位表示相同,因此它适合这两种分类。但是,默认 IO 设备与 chardata 一起工作,这意味着我们可以这样做:

总体而言,列表中的整数可能表示一堆字节或一堆字符,使用哪一个取决于 IO 设备的编码。如果文件未经过编码打开,则文件应处于原始模式,并且必须使用 IO 模块中以 bin* 开头的函数。这些函数需要 iodata 作为参数,其中列表中的整数表示字节。
另一方面,默认 IO 设备 (:stdio) 和使用 :utf8 编码打开的文件与 IO 模块中的其余函数一起工作。这些函数需要 chardata 作为参数,其中整数表示码位。
虽然这是一个微妙的差异,但如果您打算将包含整数的列表传递给这些函数,则只需担心这些细节。如果您传递二进制文件或二进制文件列表,则不会出现歧义。
最后,还有最后一个构造称为 charlist,我们在前面的章节中讨论过。Charlist 是 chardata 的一个特例,其中所有值都是表示 Unicode 码位的整数。它们可以用 ~c 符号创建:
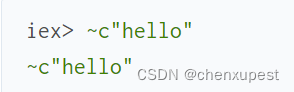
字符列表主要出现在与 Erlang 交互时,因为一些 Erlang API 使用字符列表作为字符串的表示。因此,任何包含可打印 ASCII 码位的列表都将打印为字符列表:

我们在这个小部分中塞进了很多内容,让我们来整理一下:
1.iodata 和 chardata 是二进制和整数的列表。这些二进制和整数可以任意嵌套在列表中。它们的目标是在使用 IO 设备和文件时提供灵活性和性能;
2.iodata 和 chardata 之间的选择取决于 IO 设备的编码。如果文件在没有编码的情况下打开,则文件需要 iodata,并且必须使用以 bin* 开头的 IO 模块中的函数。默认 IO 设备 (:stdio) 和使用 :utf8 编码打开的文件需要 chardata,并与 IO 模块中的其余函数配合使用;
3.charlists 是 chardata 的一个特例,它专门使用整数 Unicode 代码点列表。它们可以使用 ~c 符号创建。如果列表中的所有整数都代表可打印的 ASCII 代码点,则使用 ~c 符号自动打印整数列表。
这结束了我们对 IO 设备和 IO 相关功能的介绍。我们了解了三个 Elixir 模块 - IO、File 和 Path - 以及 VM 如何使用进程来实现底层 IO 机制以及如何使用 chardata 和 iodata 进行 IO 操作。















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









