






基于网络电视节目的精准营销分析
本篇文章,准备以网络电视节目精准营销作为契子,介绍一种向量算法,希望能在以后的行业应用中有所运用。
案例简介
伴随着互联网技术的快速发展和应用拓展,“三网融合”(因特网、电信网、广播电视网)为传统广播电视媒介带来了发展机遇,广播电视运营商可以与众多的家庭用户实现信息的实时交互,使得全方位、个性化的产品营销和有偿服务成为现实。
某广电网络运营公司现已建设大数据基础营销服务平台,如果给出你部分用户的观看记录信息数据和运营公司的产品信息数据,利用数据挖掘的办法,该怎样分析用户的收视偏好?怎么对用户或者产品进行打包推荐?数据是王道,下面先看数据:
表1.电视节目数据
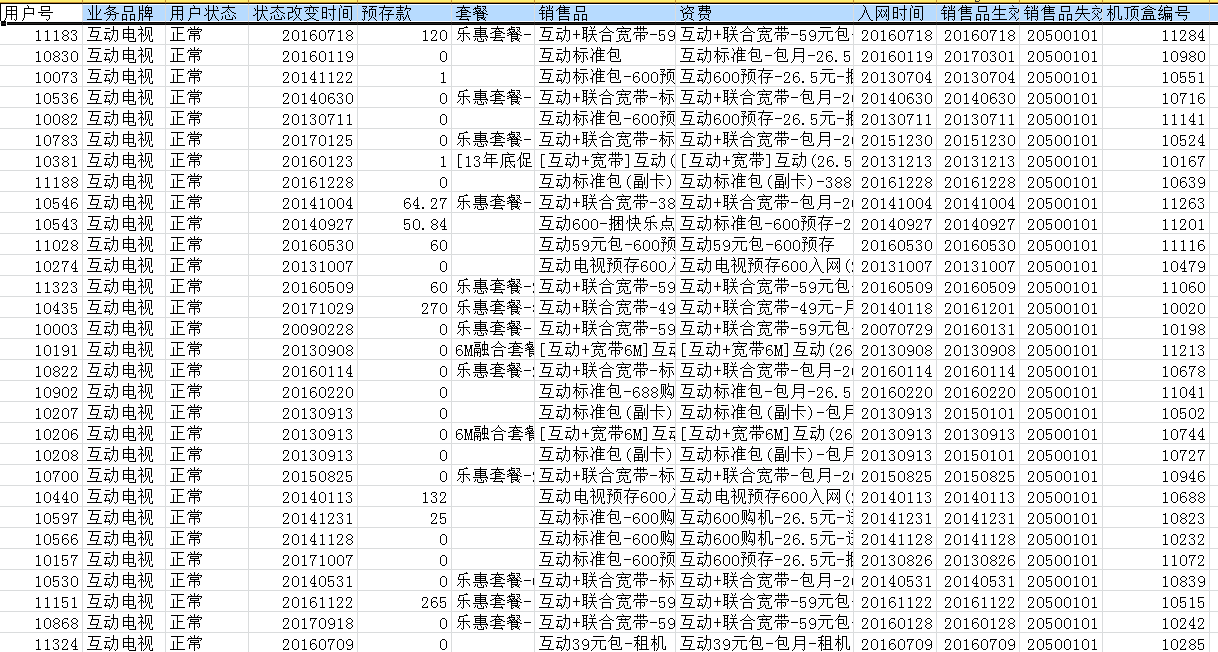
表2.用户数据
 表3.用户收视信息
表3.用户收视信息
初步分析及算法引入
根据这些数据,其实我们可以做些人为分析的。比如说,两个小孩,都喜欢看宫崎骏的动漫,如果他们认识,肯定会进行一些动漫讨论或分享,很随意也就把自己看的动漫节目推荐给了对方。如果不认识,作为第三方,根据他们的收视纪录,也可以进行推荐,这是常规的处理办法。如果数据量很大,这种办法显然不可行。所以,怎么把这种人为处理办法转换为机器语言,让计算机进行类似的活动,就显得很重要。
其实上面说的人为办法,也就是计算机语言里所谓的算法。什么是算法?算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或者多个操作。这两年随着人工智能技术的发展势头,各种学习算法也是不绝于耳。常听的概念有数据挖掘、机器学习、深度学习等,理论概念太抽象,网络上各种学习资源太多,所以还是分析点干货,窥一斑而知全豹.
针对上面案例中电视节目打包/标签推荐,一般来讲可以用基于物品或者用户的ItemCF/UserCF等方式来做,但随着13年谷歌发布的Word2vec之后,大家认识到很多特征的表示都可以转成稠密向量,来直接替换电视节目或用户的id,这样从向量出发得到的结果更有效。这里用到的deepwalk,底层使用word2vec实现,原理是把用户看过的电视节目,或电视节目被用户看过,宏观看作一张网,deepwalk就是学习出各个节点表达的信息。特别感谢deepwalk作者的贡献,一篇论文,引起这么多人趋之若鹜的研究。
deepwalk这篇paper是有一篇很有意思的文章,整篇paper都在探讨一件事:将一个网络中的每个节点映射成一个低维的向量。说白了就是用一个向量去表示网络中的每个节点,并且希望这些向量能够将网络中的节点中的关系表达出来,即希望在原始网络中关系越紧密的结点对应的向量在其空间中距离越近。用张图表示如下所示(出自论文):
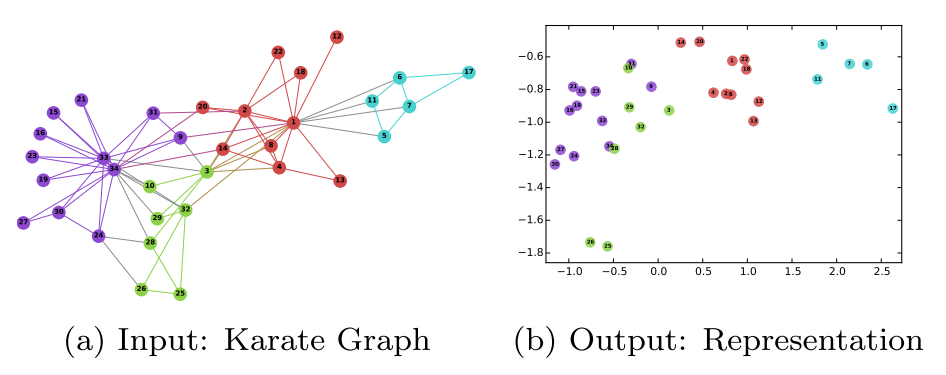
输入的是一个网络,其中颜色相同的结点表示拓扑关系上更为相近的结点。输出的是每个节点的二维向量,每个节点对应的向量关系如图所示。可以从这个图看出,越是拓扑结构相近的点,其对应的二维向量在二维空间上距离与近。
个人理解可以将这个过程理解为一个降维的过程,但是不同于传统意义上的高纬度降到低纬度,而是将一个复杂的结构降到低纬度。或者说可以理解为,将网络中的拓扑结构,嵌入到一个低维向量中,每个节点的低维向量,从某种程度上反应了该节点在网络中的连接情况。翻译成大白话,也就是把看的出来的一些复杂关系图,转换为向量数据,目的也就是可以借助于一些数学方法比如说余弦定理、贝叶斯公式等进行临近分析。数据量越大,通过deepwalk建立的数据模型越精准,目前已在阿里巴巴得到了系统运用。
处理流程
再具体到案例中,结合这个算法,可以这样考虑。各个电视节目可以按照不同的纬度,在模拟网络里进行各种排列组合,然后作为算法的接收数据,转换为矢量数据,这是重点需要分析的,随后就是根据算法提供的一些API函数,进行常规业务处理。
整体思路或者说流程是:
- 从用户看过的电视节目里找出隐喻关联,比如说相同导演、相同演员,或者都是大陆片还是欧美片,每个电视节目是可以独立标识的。相同导演、演员的节目可以排列在一起,比如说放在一个集合里。
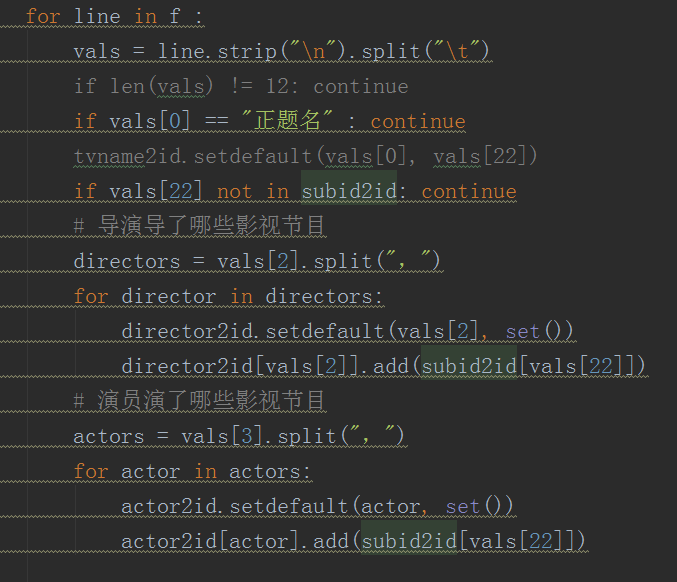
- 这些组合数据可通过deepwalk进行训练,生成模型数据。

- 依赖这些模型数据,借助于现成的目标API,进行程序遍历判断,最终得出需要的结果数据。
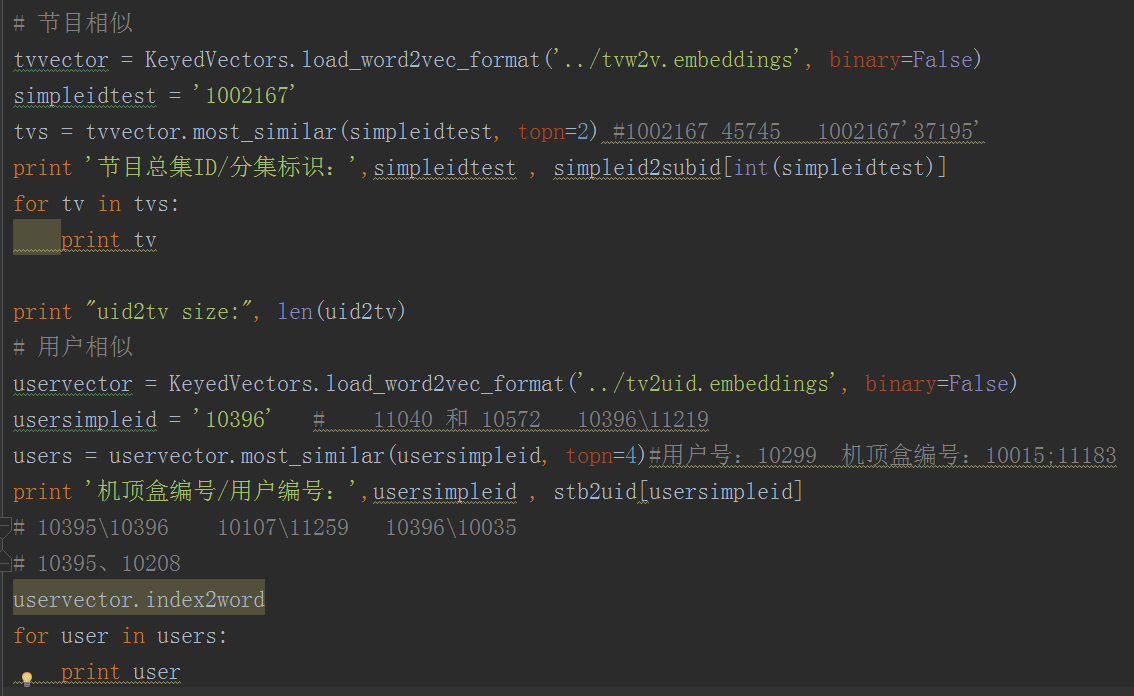
算法不是万能的,这里得到的其实就是论文里右边的output数据集合,要最终得到用户的收视偏好,还需要取出集合里的数据做进一步处理。通过代码片段不难看出,相似用户或者相似节目不难找出,但是要进一步分析用户收视偏好,还需要做下一步工作,回归常规的逻辑处理,也就是通过对用户收视节目进行打标签处理,进而对用户进行分类,这里会用到数据爬取的知识。不论是数据爬取还是算法分析,都可以独立成一个独立模块,需要深究的东西还很多,有兴趣的大家可以一并研究下。
结束语
在铁路行业,每天都会产生很多列车运行记录数据,这些数据记录了设备状态、轨迹数据及很多项点数据,限于某些因素,基本都是事后分析,通过教训来买得经验。而每次经验都是很多幸福家庭的晴天霹雷换来的,倘若能借着一些技术手段,用好这些数据,做到实时分析和预警,应该会有很不错的发展。















 5142
5142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









