










Linux 内核中RAID5源码详解之写过程剖析(一)
前面说了很多铺垫性的东西,感觉是时候放大招了,今天我们就来谈谈内核中RAID5最重要的特征:写。前面说过了handle_stripe() 是处理stripe_head的真正战场,由于该函数十分复杂,所以我在内核源码中增添了写输出信息,便于理解,由于里面的函数调用很多,下面讲的时候会涵盖很多函数的源码,所以请自备花生、水果和饮料,感觉会很长,我尽量将相同的处理部分放在一起讲,同时我也会通过图示的方法让大家便于理解函数的原理。好了,Let’s fight!!!
实验环境
为了便于理解,我通过实验的方法,结合实验数据,给出具体的数字,让大家更清晰的了解函数的运行流程,下面先介绍下我搭建的实验环境。
- RAID5:3+1 RAID5模型
- 内核版本:Linux 4.0.2
- mdadm创建的RAID5模块
接下来我会给出一组形式化的表达:
函数名:
条带stripe_head:条带的状态
设备缓冲区dev: 缓冲区的标志
以及相应函数的说明
————————————–
例如:
handle_stripe:
sh:STRIPE_HANDLE,STRIPE_PREREAD_ACTIVE
d0:R5_OVERWRITE
d1,d2,d3:NULL
这表示了进入handle_stripe()时条带sh的状态为STRIPE_HANDLE,STRIPE_PREREAD_ACTIVE,缓冲区d0的标志为R5_OVERWRITE,d1,d2,d3缓冲区的标志为空。
写过程剖析
写请求的处理
前面说过了请求从文件系统层传到MD模块,然后MD模块中调用md->pers->make_request 来处理请求,而真正的在RAID5中入口是make_request() 函数,好,我们就从那里开始看。
/*make_request()*/
struct r5conf *conf = mddev->private;
int dd_idx;
sector_t new_sector;
sector_t logical_sector, last_sector;
struct stripe_head *sh;
const int rw = bio_data_dir(bi);
int remaining;
DEFINE_WAIT(w);
bool do_prepare;
if (unlikely(bi->bi_rw & REQ_FLUSH)) {
md_flush_request(mddev, bi);
return;
}
md_write_start(mddev, bi);//元数据的写
if (rw == READ &&
mddev->reshape_position == MaxSector &&
chunk_aligned_read(mddev,bi))//读请求的联合处理
return;
if (unlikely(bi->bi_rw & REQ_DISCARD)) {
make_discard_request(mddev, bi);
return;
}
logical_sector = bi->bi_iter.bi_sector & ~((sector_t)STRIPE_SECTORS-1);//请求的起始偏移量
last_sector = bio_end_sector(bi);//请求的结束偏移量
bi->bi_next = NULL;//将请求的next指针赋为NULL
bi->bi_phys_segments = 1;//引用请求的stripe\_head的个数开始只是些基本操作,对于普通的写请求,我们不考虑太多,所以上述的几个函数我们置之不理,对于理解写请求的操作没什么影响,然后计算请求的起始偏移量和结束偏移量,为后面的切片做准备 。接下来:
prepare_to_wait(&conf->wait_for_overlap, &w, TASK_UNINTERRUPTIBLE);
for (;logical_sector < last_sector; logical_sector += STRIPE_SECTORS) {
int previous;
int seq;
do_prepare = false;
retry:
seq = read_seqcount_begin(&conf->gen_lock);
previous = 0;
if (do_prepare)
prepare_to_wait(&conf->wait_for_overlap, &w,
TASK_UNINTERRUPTIBLE);
if (unlikely(conf->reshape_progress != MaxSector)) {
/* spinlock is needed as reshape_progress may be
* 64bit on a 32bit platform, and so it might be
* possible to see a half-updated value
* Of course reshape_progress could change after
* the lock is dropped, so once we get a reference
* to the stripe that we think it is, we will have
* to check again.
*/
spin_lock_irq(&conf->device_lock);
if (mddev->reshape_backwards
? logical_sector < conf->reshape_progress
: logical_sector >= conf->reshape_progress) {
previous = 1;
} else {
if (mddev->reshape_backwards
? logical_sector < conf->reshape_safe
: logical_sector >= conf->reshape_safe) {
spin_unlock_irq(&conf->device_lock);
schedule();
do_prepare = true;
goto retry;
}
}
spin_unlock_irq(&conf->device_lock);
}
new_sector = raid5_compute_sector(conf, logical_sector,
previous,
&dd_idx, NULL);
pr_debug("raid456: make_request, sector %llu logical %llu\n",
(unsigned long long)new_sector,
(unsigned long long)logical_sector);
sh = get_active_stripe(conf, new_sector, previous,
(bi->bi_rw&RWA_MASK), 0);上述代码是将bio请求切片,切成一个个STRIPE_SECTORS大小的数据段,结合图示来了解下为什么切片:
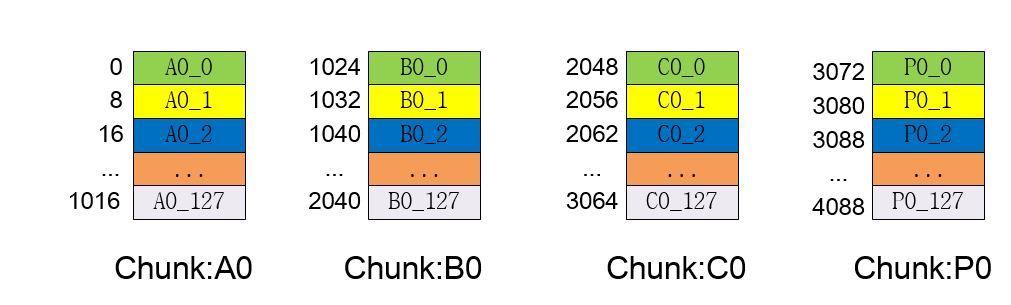
这是RAID5中stripe_head结构图示,方块前的数字代表地址(以sector为单位),采用默认的chunk大小,一个chunk含有128个page,每一个chunk中具有相同的chunk_offset的page组成一个stripe_head,即图中颜色相同的方块。因为RAID5中处理的基本单元为stripe_head,所以,假设有一个bio请求,要求写A0_0和A0_1这两页的数据,可见这两页分属于两个不同的stripe_head,所以需要单独拿出来处理,所以讲bio请求划分成page为单位大小的页,只是为了处理符合RAID5的stripe_head结构。
接下来对每一页进行处理:new_sector = raid5_compute_sector(conf, logical_sector, previous,&dd_idx, NULL); 跟进raid5_compute_sector() :
static sector_t raid5_compute_sector(struct r5conf *conf, sector_t r_sector,
int previous, int *dd_idx,
struct stripe_head *sh)
{/*将r_sector这个偏移量转化为dd_idx号盘,偏移量为返回值的具体位置,同时根据算法设置stripe_head中的校验盘pd_idx,previous表示是否使用以前的版本,可以忽略*/
sector_t stripe, stripe2;
sector_t chunk_number;
unsigned int chunk_offset;
int pd_idx, qd_idx;
int ddf_layout = 0;
sector_t new_sector;
int algorithm = previous ? conf->prev_algo
: conf->algorithm;
int sectors_per_chunk = previous ? conf->prev_chunk_sectors
: conf->chunk_sectors;//一个chunk含有的sector数,默认为1024
int raid_disks = previous ? conf->previous_raid_disks
: conf->raid_disks;//RAID中的磁盘个数
int data_disks = raid_disks - conf->max_degraded;//RAID中的数据盘的个数
/* First compute the information on this sector */
/*
* Compute the chunk number and the sector offset inside the chunk
*/
chunk_offset = sector_div(r_sector, sectors_per_chunk);
chunk_number = r_sector;
/*
* Compute the stripe number
*/
stripe = chunk_number;
*dd_idx = sector_div(stripe, data_disks);
stripe2 = stripe;
/*
* Select the parity disk based on the user selected algorithm.
*/
pd_idx = qd_idx = -1;
switch(conf->level) {
case 5:
switch (algorithm) {
case ALGORITHM_LEFT_ASYMMETRIC:
pd_idx = data_disks - sector_div(stripe2, raid_disks);
if (*dd_idx >= pd_idx)
(*dd_idx)++;
break;
case ALGORITHM_RIGHT_ASYMMETRIC:
pd_idx = sector_div(stripe2, raid_disks);
if (*dd_idx >= pd_idx)
(*dd_idx)++;
break;
case ALGORITHM_LEFT_SYMMETRIC:
pd_idx = data_disks - sector_div(stripe2, raid_disks);
*dd_idx = (pd_idx + 1 + *dd_idx) % raid_disks;
break;
case ALGORITHM_RIGHT_SYMMETRIC:
pd_idx = sector_div(stripe2, raid_disks);
*dd_idx = (pd_idx + 1 + *dd_idx) % raid_disks;
break;
case ALGORITHM_PARITY_0:
pd_idx = 0;
(*dd_idx)++;
break;
case ALGORITHM_PARITY_N:
pd_idx = data_disks;
break;
default:
BUG();
}
break;
}
if (sh) {
sh->pd_idx = pd_idx;
sh->qd_idx = qd_idx;
sh->ddf_layout = ddf_layout;
}
/*
* Finally, compute the new sector number
*/
new_sector = (sector_t)stripe * sectors_per_chunk + chunk_offset;
return new_sector;
}我们根据一个具体偏移量的计算来观察raid5_compute_sector()函数的运做:
假设传进来的r_sector=40.
sectors_per_chunk:1024
raid_disks=4
data_disks=3
在chunk内的偏移chunk_offset= r_sector%sectors_per_chunk=40%1024=40
所在chunk的编号chunk_number=r_sector/sectors_per_chunk=40/1024=0
一个stripe包含3个data_chunk,此为stripe编号stripe=chunk_number/data_disks=0/3=0
dd_idx=chunk_number%data_disks=0%3=0
new_sector=stripe*sectors_per_chunk+chunk_offset=0*1024+40=40 对应于dd_idx这个盘上的stripe偏移
Algorithm=2= ALGORITHM_LEFT_SYMMETRIC
//0号chunk的pd_idx都是3,1号chunk的pd_idx都是2,相应的dd_idx向左移了一下,依次下去,等等
pd_idx=data_disks-stripe%raid_disks=3-0%4=3;
dd_idx=(pd_idx+1+dd_idx)%raid_disks=(3+1+0)%4=0;
So,dd_idx=0,pd_idx=3.
上述的stripe并不是stripe_head,而是由chunk组成的stripe!区分不了stripe和stripe_head的可以参考我的另一篇博文:Linux内核中RAID5的基本架构与数据结构解析,所以对于这个函数我们只要知道传进去的偏移量通过算法确定到哪块盘上,哪个条带上,以及条带的校验盘的盘号就可以了。
返回到make_request() 中,接下来就是获取stripe_head,前一篇博文Linux 内核中RAID5源码详解之stripe_head的管理 已经介绍过了,至此已经得到一个stripe_head结构 sh,那么接下来就需要将请求添加到sh的dev缓冲区的请求链表中:
if (test_bit(STRIPE_EXPANDING, &sh->state) ||
!add_stripe_bio(sh, bi, dd_idx, rw)) {/*add_stripe_bio()就是讲bio添加到stripe_head中*/
/* Stripe is busy expanding or
* add failed due to overlap. Flush everything
* and wait a while
*/
md_wakeup_thread(mddev->thread);
release_stripe(sh);
schedule();
do_prepare = true;
goto retry;
}
set_bit(STRIPE_HANDLE, &sh->state);//设置为需要处理
clear_bit(STRIPE_DELAYED, &sh->state);//清除延迟处理标志
if ((bi->bi_rw & REQ_SYNC) &&
!test_and_set_bit(STRIPE_PREREAD_ACTIVE, &sh->state))/*如果是同步请求,并且以前sh不是STRIPE_PREREAD_ACTIVE状态,而且设置预读状态成功,则将RAID5中预读的条带数+1*/
atomic_inc(&conf->preread_active_stripes);
release_stripe_plug(mddev, sh);//处理条带这里我们细看下add_stripe_bio() 这个函数,跟进:
static int add_stripe_bio(struct stripe_head *sh, struct bio *bi, int dd_idx, int forwrite)
{//dd_idx为将要加入的盘号
struct bio **bip;
struct r5conf *conf = sh->raid_conf;
int firstwrite=0;
pr_debug("adding bi b#%llu to stripe s#%llu\n",
(unsigned long long)bi->bi_iter.bi_sector,
(unsigned long long)sh->sector);
/*
* If several bio share a stripe. The bio bi_phys_segments acts as a
* reference count to avoid race. The reference count should already be
* increased before this function is called (for example, in
* make_request()), so other bio sharing this stripe will not free the
* stripe. If a stripe is owned by one stripe, the stripe lock will
* protect it.
*/
spin_lock_irq(&sh->stripe_lock);
if (forwrite) {//写请求
bip = &sh->dev[dd_idx].towrite;
if (*bip == NULL)
firstwrite = 1;
} else//读请求
bip = &sh->dev[dd_idx].toread;
while (*bip && (*bip)->bi_iter.bi_sector < bi->bi_iter.bi_sector) {
if (bio_end_sector(*bip) > bi->bi_iter.bi_sector)
goto overlap;
bip = & (*bip)->bi_next;
}
if (*bip && (*bip)->bi_iter.bi_sector < bio_end_sector(bi))
goto overlap;
BUG_ON(*bip && bi->bi_next && (*bip) != bi->bi_next);
if (*bip)
bi->bi_next = *bip;
*bip = bi;
raid5_inc_bi_active_stripes(bi);//将bio请求引用的条带数+1
if (forwrite) {//第一次写
/* check if page is covered */
sector_t sector = sh->dev[dd_idx].sector;
for (bi=sh->dev[dd_idx].towrite;
sector < sh->dev[dd_idx].sector + STRIPE_SECTORS &&
bi && bi->bi_iter.bi_sector <= sector;
bi = r5_next_bio(bi, sh->dev[dd_idx].sector)) {
if (bio_end_sector(bi) >= sector)
sector = bio_end_sector(bi);
}
if (sector >= sh->dev[dd_idx].sector + STRIPE_SECTORS)//满写
set_bit(R5_OVERWRITE, &sh->dev[dd_idx].flags);
}
pr_debug("added bi b#%llu to stripe s#%llu, disk %d.\n",
(unsigned long long)(*bip)->bi_iter.bi_sector,
(unsigned long long)sh->sector, dd_idx);
spin_unlock_irq(&sh->stripe_lock);
if (conf->mddev->bitmap && firstwrite) {//bitmap操作
bitmap_startwrite(conf->mddev->bitmap, sh->sector,
STRIPE_SECTORS, 0);
sh->bm_seq = conf->seq_flush+1;
set_bit(STRIPE_BIT_DELAY, &sh->state);
}
return 1;
overlap:
set_bit(R5_Overlap, &sh->dev[dd_idx].flags);
spin_unlock_irq(&sh->stripe_lock);
return 0;
}
相应的注释已经标识出来了,这个函数就是将bio请求添加到相应的盘上,如果请求的范围覆盖了整个缓冲区,则设置为R5_OVERWRITE满写标志。
返回到make_request() ,为sh设置为需要处理的标志,调用release_stripe_plug() 处理sh。至此,make_request() 处理就结束了,这也是对请求最基本的处理,接下来就是对stripe_head的处理了,战场转移到handle_stripe() 中了。















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









