










Linux内核中RAID5的基本架构与数据结构解析
众所周知,早年的计算机存储数据现在磁带上,然后发展到了磁盘,然而仅仅是单个盘,速度和性能都不是很好,然是,要知道人类的聪明才智是连ET都想不到的,前辈们不断的猜想,实验来提高计算机的性能,于是磁盘阵列问世了。由于磁盘阵列(Redundant Arrays of Independent Disks,RAID)的出现,使磁盘的存储性能和安全性等诸多方面有了飞速的提升,随着科技的进步,存储材质也在不断的优化,早期的磁带到磁盘,以及现在的SSD,甚至未来的比SSD性能更好的PCM(phase-change memory)都在极力的提高存储性能。然而试想一下,几个盘连在一起的性能居然比单盘高几倍?不可思议啊!前辈们是怎么做到的?他们怎么这么厉害!今天,我们就来看看真正的RAID是怎么实现的,我们拿用的最多的RAID5这个架构来学习下内核中的RAID实现方法。
相信有关RAID5的资料和博文已经很多很多了,那么我们就换一个特别的方式来了解RAID5,我们从linux内核中的源码起步,从代码的角度来分析RAID5是怎么一步步实现的。这篇博文主要描述RAID5的基本架构以及相应的数据结构。
环境搭建
RAID模块化
要想深入了解内核中的RAID5代码,必须要搭建一个RAID5的环境,为了避免修改源码时重新编译的耗时长的问题,我们将RAID5进行模块化,具体操作见我的一篇博文—Linux 内核中MD及RAID模块化。
搭建RAID5
上述的RAID5模块化结束后,我们就可以搭建RAID5的实验环境,具体操作见我的一篇博文—mdadm创建software RAID。
RAID5环境搭建好后,我们就开始来了解RAID5的原理了。Let’s go!
RAID5的基本架构
RAID5的读写操作采用的是stripe的基本结构,即以stripe为读写的基本单位,假设一个3+1的RAID5,即3个数据盘+1个校验盘,那么一个stripe就包含3个数据块和一个校验块。我们结合图示来仔细看下RAID5的架构。
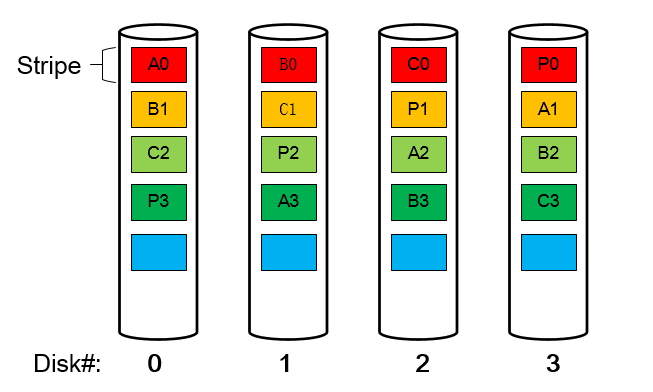
如图所示,这是一个3+1的RAID5,图中的每一个方块表示一个stripe的一个基本单元,又称为chunk;相同颜色的方块组成一个stripe,即每个stripe由3个数据chunk(A,B,C)+1个校验chunk(P)组成。关于校验块的生成方法以及数据恢复原理如下:
- 校验块P的生成方法为
P=A⊕B⊕C。(⊕表示异或运算) - 加入1号盘坏了,此时有读请求读B0块的数据,那么可以通过
B0=A0⊕C0⊕P0的方法 来进行恢复。
可以观察到上图中的校验块不是单独的全部存在一个盘上,这是为了实现RAID中磁盘的磨损平衡,防止某个盘寿命太短而先损坏。 内核中有很多这种平衡校验块的算法,上图中用到的是ALGORITHM_LEFT_SYMMETRIC。
内核中默认的stripe大小
基本上所有的OS都认可的page大小是4KB,由于内核中是按sector为基本大小单位,1 sector = 512B,所以有如下公式:
- 1 page = 8*sector = 4KB
- 1 chunk = 128*page = 512KB
- 1 stripe = 4*chunk = 2048KB
- 1 stripe的data size =3*chunk =1536KB
RAID5的数据结构
RAID5在内核中的处理单元stripe_head
虽然说直观上看RAID5的基本处理单元是stripe,但是一个chunk的大小是512KB,这与OS一次处理的page大小相差太多,所以为了处理的一致性,内核将一个chunk分成128个page,由一个stripe的每个chunk出一个对应的page组成内核中的RAID5处理的基本单元:stripe_head。stripe_head的定义在raid5.h中。
struct stripe_head {
struct hlist_node hash;
struct list_head lru; /* inactive_list or handle_list */
struct llist_node release_list;
struct r5conf *raid_conf;//raid5的全局配置信息
short generation; /* increments with every
* reshape */
sector_t sector; /* sector of this row */
short pd_idx; /* parity disk index */
short qd_idx; /* 'Q' disk index for raid6 */
short ddf_layout;/* use DDF ordering to calculate Q */
short hash_lock_index;
unsigned long state; /* state flags */
atomic_t count; /* nr of active thread/requests */
int bm_seq; /* sequence number for bitmap flushes */
int disks; /* disks in stripe */
enum check_states check_state;
enum reconstruct_states reconstruct_state;
spinlock_t stripe_lock;
int cpu;
struct r5worker_group *group;
/**
* struct stripe_operations
* @target - STRIPE_OP_COMPUTE_BLK target
* @target2 - 2nd compute target in the raid6 case
* @zero_sum_result - P and Q verification flags
* @request - async service request flags for raid_run_ops
*/
struct stripe_operations {
int target, target2;
enum sum_check_flags zero_sum_result;
} ops;
struct r5dev {
/* rreq and rvec are used for the replacement device when
* writing data to both devices.
*/
struct bio req, rreq;
struct bio_vec vec, rvec;
struct page *page, *orig_page;
struct bio *toread, *read, *towrite, *written;
sector_t sector; /* sector of this page */
unsigned long flags;
} dev[1]; /* allocated with extra space depending of RAID geometry */
};相应项的注释已经给出,我们用图来详细了解下stripe_head与stripe的区别。
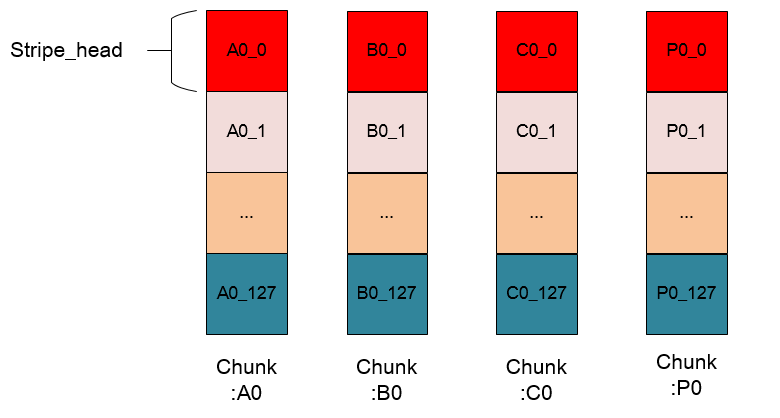
这是第一幅图中的stripe 0 的细化,stripe 0 由A0、B0、C0和P0组成,这幅图中,将每个chunk细化,由于一个chunk的大小是128个page的大小,所以一个chunk中含有128个page,每个page的大小是4KB,所以在每一个chunk中具有相同偏移量的page组成一个stripe_head,即图中每个颜色相同的方块组成一个stripe_head。
- 1 stripe_head = 4*page = 16KB
- 1 stripe = 128 * stripe_head =2048KB
所以说:我们经常说的RAID5的处理单元stripe,实际上是内核中的处理单元stripe_head的结合体,不要搞混淆了哦~
另外我还要再强调一点,每个请求bio都会有一个起始地址,这个地址对应的位置(根据上述的算法ALGORITHM_LEFT_SYMMETRIC来确定到哪块盘上,以及在这块盘上的偏移量),一旦这个位置确定,它就会和在其他盘上具有相同偏移量的page构成一个stripe_head结构,这是确定了的,无法更改的!!!stripe_head中的sector域就是来记录这个偏移量的。
值得注意的是stripe_head中的struct dev:就是对应的每个盘的缓冲区,为一个page的大小,里面包含了发往这个盘上的请求bio链表(toread表示需要处理的读请求,towrite表示需要处理的写请求,read表示已经处理完的读请求,written表示已经处理完的写请求)以及相应的缓冲区标志。
RAID5的全局配置信息r5conf
对每一个系统都需要维护个全局的信息来管理整个系统,RAID5也不例外,对整个RAID5的管理需要维护一个数据结构—r5conf。r5conf定义在raid5.h中:
struct r5conf {
struct hlist_head *stripe_hashtbl;
/* only protect corresponding hash list and inactive_list */
spinlock_t hash_locks[NR_STRIPE_HASH_LOCKS];
struct mddev *mddev;
int chunk_sectors;/*一个chunk中sector的数目, 默认值为1024,即一个chunk的大小为512KB*/
int level, algorithm;//raid5中level=5
int max_degraded;
int raid_disks;//raid中磁盘的个数
int max_nr_stripes;/*raid中允许的最大stripe_head的个数,默认为256,即最多允许256个stripe_head存在*/
/* reshape_progress is the leading edge of a 'reshape'
* It has value MaxSector when no reshape is happening
* If delta_disks < 0, it is the last sector we started work on,
* else is it the next sector to work on.
*/
sector_t reshape_progress;
/* reshape_safe is the trailing edge of a reshape. We know that
* before (or after) this address, all reshape has completed.
*/
sector_t reshape_safe;
int previous_raid_disks;
int prev_chunk_sectors;
int prev_algo;
short generation; /* increments with every reshape */
seqcount_t gen_lock; /* lock against generation changes */
unsigned long reshape_checkpoint; /* Time we last updated
* metadata */
long long min_offset_diff; /* minimum difference between
* data_offset and
* new_data_offset across all
* devices. May be negative,
* but is closest to zero.
*/
struct list_head handle_list; /* stripes needing handling */
struct list_head hold_list; /* preread ready stripes */
struct list_head delayed_list; /* stripes that have plugged requests */
struct list_head bitmap_list; /* stripes delaying awaiting bitmap update */
struct bio *retry_read_aligned; /* currently retrying aligned bios */
struct bio *retry_read_aligned_list; /* aligned bios retry list */
atomic_t preread_active_stripes; /* stripes with scheduled io */
atomic_t active_aligned_reads;
atomic_t pending_full_writes; /* full write backlog */
int bypass_count; /* bypassed prereads */
int bypass_threshold; /* preread nice */
int skip_copy; /* Don't copy data from bio to stripe cache */
struct list_head *last_hold; /* detect hold_list promotions */
atomic_t reshape_stripes; /* stripes with pending writes for reshape */
/* unfortunately we need two cache names as we temporarily have
* two caches.
*/
int active_name;
char cache_name[2][32];
struct kmem_cache *slab_cache; /* for allocating stripes */
int seq_flush, seq_write;
int quiesce;
int fullsync; /* set to 1 if a full sync is needed,
* (fresh device added).
* Cleared when a sync completes.
*/
int recovery_disabled;
/* per cpu variables */
struct raid5_percpu {
struct page *spare_page; /* Used when checking P/Q in raid6 */
void *scribble; /* space for constructing buffer
* lists and performing address
* conversions
*/
} __percpu *percpu;
size_t scribble_len; /* size of scribble region must be
* associated with conf to handle
* cpu hotplug while reshaping
*/
#ifdef CONFIG_HOTPLUG_CPU
struct notifier_block cpu_notify;
#endif
/*
* Free stripes pool
*/
atomic_t active_stripes;
struct list_head inactive_list[NR_STRIPE_HASH_LOCKS];
atomic_t empty_inactive_list_nr;
struct llist_head released_stripes;
wait_queue_head_t wait_for_stripe;
wait_queue_head_t wait_for_overlap;
int inactive_blocked; /* release of inactive stripes blocked,
* waiting for 25% to be free
*/
int pool_size; /* number of disks in stripeheads in pool */
spinlock_t device_lock;
struct disk_info *disks;
/* When taking over an array from a different personality, we store
* the new thread here until we fully activate the array.
*/
struct md_thread *thread;
struct list_head temp_inactive_list[NR_STRIPE_HASH_LOCKS];
struct r5worker_group *worker_groups;
int group_cnt;
int worker_cnt_per_group;
};这里我们需要关注的有如下几点:
- 元数据,比如chunk_sectors、level、raid_disks、max_nr_stripes等,相应的注释已经写在上述代码片段中。
- handle_list、hold_list、delayed_list和bitmap_list,相应代表什么注释中写的很清楚了。由于stripe_head在处理时,会对应不同的状态,所以一个stripe_head在执行时会在上述几个链表中切换,弄清了这几个链表的切换条件和流程对理解raid5的运行原理有很大帮助!
- raid5的守护线程
struct md_thread *thread,在raid5中守护线程为raid5d。
RAID5中数据结构的状态解析
stripe_head的状态标识
在stripe_head的定义中有这样一个域 unsinged long state ,然后在raid5.h中会发现这样一个enum结构:
/*
* Stripe state
*/
enum {
STRIPE_ACTIVE,//正在处理
STRIPE_HANDLE,//需要处理
STRIPE_SYNC_REQUESTED,//同步请求
STRIPE_SYNCING,//正在同步
STRIPE_INSYNC,//已经同步
STRIPE_REPLACED,
STRIPE_PREREAD_ACTIVE,//预读
STRIPE_DELAYED,//延迟处理
STRIPE_DEGRADED,//降级
STRIPE_BIT_DELAY,//等待bitmap处理
STRIPE_EXPANDING,//扩展
STRIPE_EXPAND_SOURCE,
STRIPE_EXPAND_READY,
STRIPE_IO_STARTED, //IO已经下发
STRIPE_FULL_WRITE, /* all blocks are set to be overwritten ,即满写*/
STRIPE_BIOFILL_RUN,/*bio填充,就是讲page的内容copy到bio的page中*/
STRIPE_COMPUTE_RUN,//正在计算
STRIPE_OPS_REQ_PENDING,//handle_stripe 排队用
STRIPE_ON_UNPLUG_LIST,/*批量处理release_list时标识是否加入unplug链表*/
STRIPE_ON_RELEASE_LIST,
};在实际操作中,通过set_bit(&sh->state) 和 clear_bit(&sh->state) 来进行置位和复位操作,上述相应注释已经给出。这些状态代表了此时stripe_head需要什么操作或者正在进行什么操作,根据这些状态决定下面如何操作stripe_head,所以这些状态很重要,一定要熟练掌握,这里只是简要介绍下,下篇博文会结合具体操作来分析stripe_head的变化情况。
dev的状态标识
dev表示了盘的缓冲区,它的状态标识在 unsinged long flags , 相应的状态集合在raid5.h中,如下:
/* Flags for struct r5dev.flags */
enum r5dev_flags {
R5_UPTODATE, /* page contains current data */
R5_LOCKED, /* IO has been submitted on "req" */
R5_DOUBLE_LOCKED,/* Cannot clear R5_LOCKED until 2 writes complete */
R5_OVERWRITE, /* towrite covers whole page */
/* and some that are internal to handle_stripe */
R5_Insync, /* rdev && rdev->in_sync at start */
R5_Wantread, /* want to schedule a read */
R5_Wantwrite,
R5_Overlap, /* There is a pending overlapping request
* on this block */
R5_ReadNoMerge, /* prevent bio from merging in block-layer */
R5_ReadError, /* seen a read error here recently */
R5_ReWrite, /* have tried to over-write the readerror */
R5_Expanded, /* This block now has post-expand data */
R5_Wantcompute, /* compute_block in progress treat as
* uptodate
*/
R5_Wantfill, /* dev->toread contains a bio that needs
* filling
*/
R5_Wantdrain, /* dev->towrite needs to be drained */
R5_WantFUA, /* Write should be FUA */
R5_SyncIO, /* The IO is sync */
R5_WriteError, /* got a write error - need to record it */
R5_MadeGood, /* A bad block has been fixed by writing to it */
R5_ReadRepl, /* Will/did read from replacement rather than orig */
R5_MadeGoodRepl,/* A bad block on the replacement device has been
* fixed by writing to it */
R5_NeedReplace, /* This device has a replacement which is not
* up-to-date at this stripe. */
R5_WantReplace, /* We need to update the replacement, we have read
* data in, and now is a good time to write it out.
*/
R5_Discard, /* Discard the stripe */
R5_SkipCopy, /* Don't copy data from bio to stripe cache */
};相应的注释已经给出,有可能个刚刚看起来很吃力,其实这个很简单,就是单个单位之间的数据转换标志:bio中的page、dev中的page以及磁盘上的数据。

同时两个状态的结合也可以表示dev中数据的新旧:
| dev flag | uptodate | locked |
|---|---|---|
| empty | 0 | 0 |
| want | 0 | 1 |
| dirty | 1 | 1 |
| clean | 1 | 0 |
Note:一定要对RAID5中的各种状态熟练掌握,因为在代码中你会发现都是根据其状态作出相应的操作,所以了解了每一项代表的什么状态才能更清楚的掌握RAID5的运作原理。
到这里应该对内核中的RAID5体系以及相应的数据结构有了一定的了解了吧,下一篇我会结合RAID5中的写请求来详细的分析RAID5是如何实现写请求的。















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









