










在成功安装和配置hadoop集群环境后(大家可以看我的其他几篇关于hadoop的微博,都是本人边学习边实践的经历,大家可以借鉴一下),接下来我来为大家介绍一下如何在Ubuntu下安装eclipse并且为eclipse配置hadoop开发环境。
1、安装eclipse
下载eclipse安装包,我用的是eclipse-jee-helios-SR2-linux-gtk.tar.gz (由于安装包太大不能上传,所以有需要的可以留下邮箱,我发给你),把安装包复制到自己要安装的目录下,然后通过cd命令进入安装目录,再通过命令:tar -zxvf eclipse-jee-helios-SR2-linux-gtk.tar.gz 把安装包压缩到当前目录下,我的情况如下图所示(大家可以根据自己的喜欢安装在不同的目录下):

此时eclipse就安装完成,如果想把eclipse的快捷方式弄到桌面上,具体详见我写的博客:如何在ubuntu下创建eclipse的桌面快捷方式(http://blog.csdn.net/chenyuangege/article/details/45771001)
2、为eclipse配置hadoop开发环境
(1)安装hadoop插件
下载hadoop在eclipse下的插件,我的插件是:hadoop-eclipse-plugin-1.2.1.jar,下载地址:
http://download.csdn.net/detail/chenyuangege/8709267 ,注意这个插件的版本号要和你安装的hadoop版本号相对应,比如我这里安装的hadoop是:hadoop-1.2.1.tar.gz ,那么你的插件就得是相应的版本号:hadoop-eclipse-plugin-1.2.1.jar 。下载此插件后要放在eclipse/dropins目录下,不要放在eclipse/plugins目录下,然后重启eclipse。
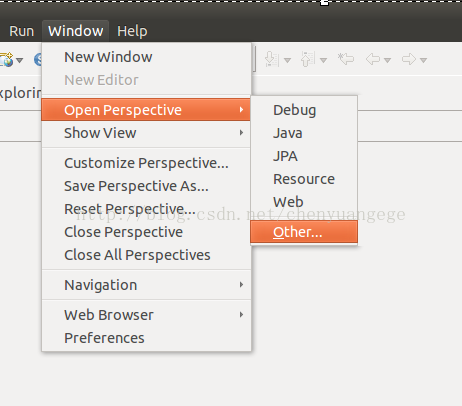
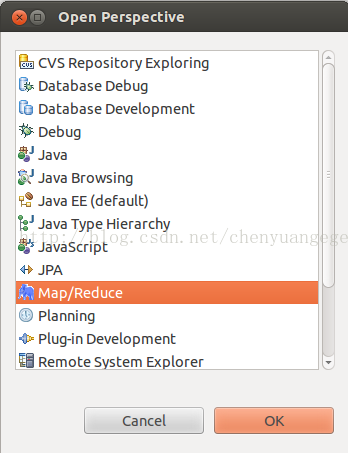
(2)选择Windows-->open perspective-->other,在弹出的框中选中"Map/Reduce",这样子就可以切换到Map/Reduce工作目录了,如下图所示:
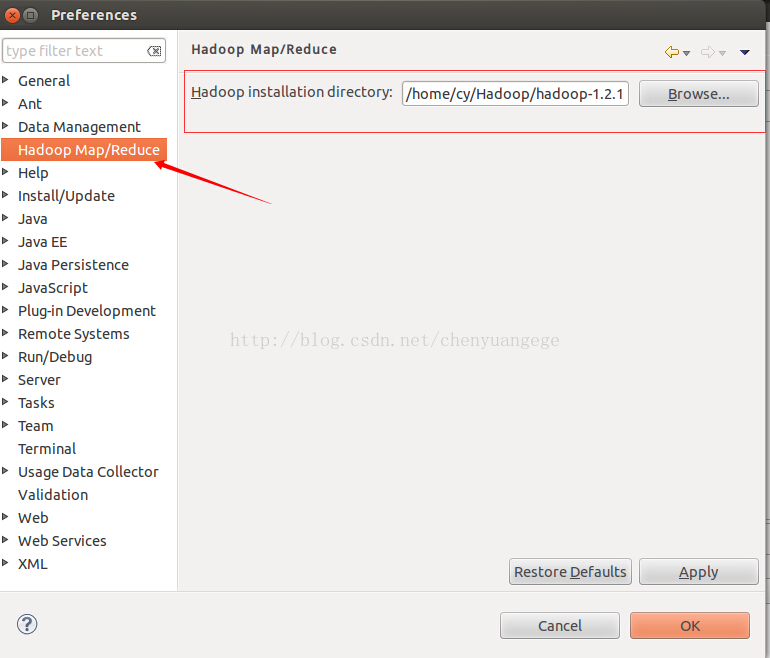
(3)在Eclipse中指定Hadoop的安装目录。选择“Window”下的“Preference”,然后弹出一个窗体,在窗体的左侧中找到“Hadoop Map/Reduce”选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:/home/cy/Hadoop/hadoop-1.2.1)。 如下图所示:
(4)配置Map/Reduce Locations。选择Map/Reduce location标签页,点击右键选择new hadoop location新建hadoop location,如下图所示:
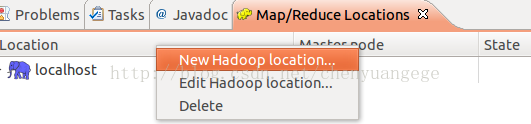

注意:上图中Location name 可以随便去自己喜欢取的名字,我自己取的是:localhost;
Map/Reduce Master:
Host:(即/home/cy/Hadoop/hadoop-1.2.1/conf/mapred-site.xml中ip,我自己的是slave2)
Port:(即/home/cy/Hadoop/hadoop-1.2.1/conf/mapred-site.xml中端口,我自己的是9001)
DFS Master:
Use M/R Master host:前面的不要勾上(因为我的NameNode和JobTracker不在一个机器上),要是你的NameNode和JobTracker在一个机器上的话就要勾上
Host(即/home/cy/Hadoop/hadoop-1.2.1/conf/core-site.xml中ip,我自己的是master))
Port (即/home/cy/Hadoop/hadoop-1.2.1/conf/core-site.xml中端口,我自己的是9000))
User name:cy(操作hadoop的用户)
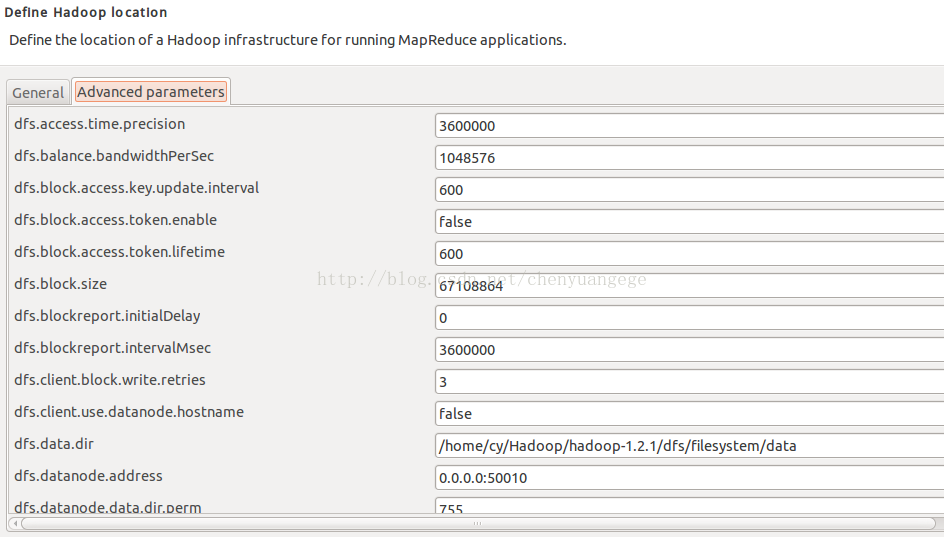
注意:安装/home/cy/Hadoop/hadoop-1.2.1/conf/目录下的core-site.xml,hdfs-site.xml和mapred-site.xml文件中的参数和对应的值,把上图所示中的相应参数设置成对应的值。
(5)点击“finish”之后,会发现Eclipse软件下面的“Map/Reduce Locations”出现一条信息, 就是我们刚才建立的“Map/Reduce Location ”,如下图所示:
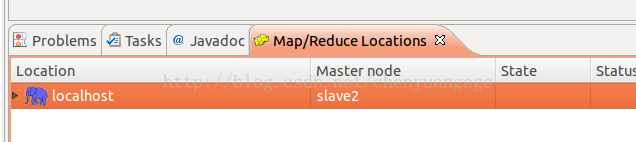
(6)如果此时你还没有启动集群的话,那就启动一下集群。
(7)如果成功的话,就可以看到hdfs的文件系统了,如下图所示:
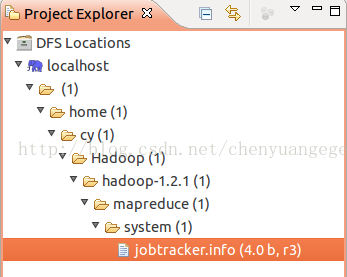
如果出现上面的目录结构,那么恭喜你了,说明你在ubuntu下eclipse的hadoop开发环境已经配置成功了,接下来就可以在hadoop集群下编写map/reduce 程序了。
我现在也在学习hadoop,以后还会继续写我学hadoop的相关经历。















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









