






hbase列式分布式数据库:
结构化数据和非结构化数据
支持实时数据处理
列存储
水平扩展优秀
HBASE接口:java api ,shell,hive
HBASE数据模型:
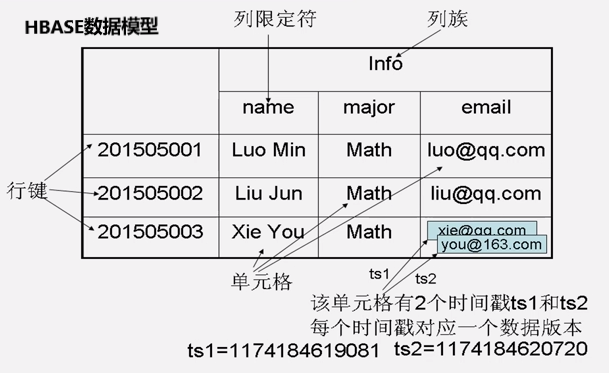
列式存储在数据分析中效率很高,同一列数据类型相同可以达到更高的压缩率;
事务性操作比较多使用传统 行式存储;
分析型应用为主 列式储存;
master服务器:
分区信息维护和管理、维护region服务器列表、监控region、负责对region进行分配、负载均衡
region服务器:
客户端存取数据、维护redion
hbase三级寻址:
zookeeper -> -ROOT表-> .META->用户数据表
hbase安装:
伪分布式:
hbase-site.xml文件
<property>
<name>hbase.cluster.distributed</name> #是否为分布式
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://weide:8020/hbase</value> #hbase共享目录,持久化hbase数据
</property>
<property>
<name>hbase.master.port</name> #hbasemaster的主机和端口
<value>weide:16000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name> #时间同步允许的时间差
<value>180000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name> #zookeeper地址,内置zookeeper进程名HQuorumPeer
<value>weide</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name> #zookeeper配置信息快照的位置,需要自己创建
<value>/home/hadoop/tmp/zookeeperdata</value>
</property>
hbase-env.sh文件,修改jdk位置、hadoop配置文件位置、zookeeper是否使用内置的;
regionservers文件 修改hbase从机器主机地址
一主多从模式:
java api:
hbase shell 增删改查:
增:put 'sinaNews','444','info1:title','weide'
删:
改:
查:
单条查根据列名 scan 'sina',{COLUMNS => ['info2:type'] }
根据行名 get 'sina','258'
全表扫描、
过滤器
上传数据:Dimportcsv方式
1.现在hbase建表
2./hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,info1:data,info1:source,info2:title,info1:type,info2:body,info1:url sinanews /weide/csv3.txt
mapreduce操作hbase:















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









