







学完了ng深度学习第四课,复习一遍代码。
今天写第一周的作业---用tensorflow框架训练深层网络实现图像识别,代码写完后问题出来啦(问题已找出,用红色字体标出)
ng的准确率:
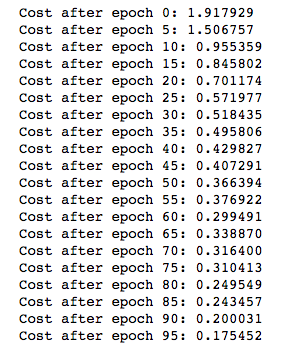
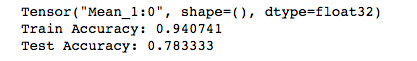
我的准确率:
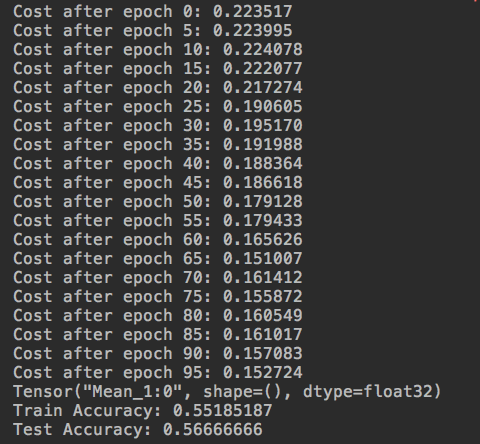
代价函数的初始值以及训练过程中的变化情况也很不一样,检查了代码是一样的。应该还是哪部分的代码出了问题,之前写别的代码也出现过类似的情况,当时是因为w的初始化公式不一样造成的。这里是什么问题暂时没检查出来,先放在这里。
import math
import numpy as np
import h5py
import matplotlib.pyplot as plt
import tensorflow as tf
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
# create a list of random mini batches from (X,Y)
def random_mini_batches(X,Y,mini_batch_size = 64):
# X---(m,Hi,Wi,Ci)
# Y---(m,n_y) value 0 or 1
m = X.shape[0]
mini_batches = []
# step 1: shuffle (X,Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation, :, :, :]
shuffled_Y = Y[permutation, :]
# step 2: partition (shuffled_X,shuffled_Y).minus the end case.
num_complete_minibatchs = math.floor(m/mini_batch_size)
for k in range(0, num_complete_minibatchs):
mini_batch_X = shuffled_X[k*mini_batch_size:k*mini_batch_size+mini_batch_size, :, :, :]
mini_batch_Y = shuffled_Y[k*mini_batch_size:k*mini_batch_size+mini_batch_size, :]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
#(原来是这里的缩进失误,按这种写法,只用了训练集的一部分数据,得出的结果对训练集和测试集的准确率当然就很差了。)
# handling the end case (last mini_batch <mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatchs*mini_batch_size:m, :, :, :]
mini_batch_Y = shuffled_Y[num_complete_minibatchs*mini_batch_size:m, :]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
# 定义onehot数组
def convert_to_one_hot(Y, C):
#先将Y转换成一行数,再将数组中指定位置的数置为1
Y = np.eye(C)[Y.reshape(-1)].T
return Y
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
X_train = X_train_orig/255.
X_test = X_test_orig/255.
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
def create_placeholders(n_H0, n_W0, n_C0, n_y):
# Creates the placeholders for the tensorflow session
X = tf.placeholder(tf.float32, shape=[None, n_H0, n_W0, n_C0])
Y = tf.placeholder(tf.float32, shape=[None, n_y])
return X, Y
def initialize_parameters():
W1 = tf.get_variable("W1", shape=[4, 4, 3, 8], initializer=tf.contrib.layers.xavier_initializer(seed=0))
W2 = tf.get_variable("W2", shape=[2, 2, 8, 16], initializer=tf.contrib.layers.xavier_initializer(seed=0))
parameters = {"W1": W1, "W2": W2}
return parameters
# Implements the forward propagation for the model:
# CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
def forward_propagation(X,parameters):
W1 = parameters['W1']
W2 = parameters['W2']
# CONV2D: stride of 1, padding 'SAME'
Z1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, sride 8, padding 'SAME'
P1 = tf.nn.max_pool(A1, ksize=[1, 8, 8, 1], strides=[1, 8, 8, 1], padding='SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(P1, W2, strides=[1, 1, 1, 1], padding='SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(A2, ksize=[1, 4, 4, 1], strides=[1, 4, 4, 1], padding='SAME')
# FLATTEN
P2 = tf.contrib.layers.flatten(P2)
# FULLY-CONNECTED without non-linear activation function (not not call softmax).
# 6 neurons in output layer. Hint: one of the arguments should be "activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P2, num_outputs=6, activation_fn=None)
return Z3
def compute_cost(Z3, Y):
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=Z3, labels=Y))
return cost
def model(X_train, Y_train, X_test, Y_test, learning_rate=0.009, num_epochs=100, minibatch_size=64, print_cost=True):
# Implements a three-layer ConvNet in Tensorflow:
# CONV2D -> RELU -> MAXPOOL -> CONV2D -> RELU -> MAXPOOL -> FLATTEN -> FULLYCONNECTED
# X_train - - training set, of shape(None, 64, 64, 3)
# Y_train - - test set, of shape(None, n_y=6)
# X_test - - training set, of shape(None, 64, 64, 3)
# Y_test - - test set, of shape(None, n_y=6)
(m, n_H0, n_W0, n_C0) = X_train.shape
n_y = Y_train.shape[1]
costs = []
# Create placeholders of the correct shape
X, Y = create_placeholders(n_H0, n_W0, n_C0, n_y)
# initialize parameters
parameters = initialize_parameters()
# forward propagation : build the forward propagation in the tensorflow graph
Z3 = forward_propagation(X, parameters)
# cost function
cost = compute_cost(Z3, Y)
# backpropagation
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# initial all the variables globally
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size)
minibatches = random_mini_batches(X_train, Y_train, minibatch_size)
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch
_, temp_cost = sess.run([optimizer, cost], feed_dict = {X : minibatch_X, Y : minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
# print the cost every epoch
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f" % (epoch, minibatch_cost))
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate = " + str(learning_rate))
plt.show()
# calculate the correct predictions
predict_op = tf.argmax(Z3, 1) # 对Z3矩阵按列计算最大值 (0表示行,1表示列)
correct_prediction = tf.equal(predict_op, tf.argmax(Y, 1))
# calculate accuracy on the test set
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) # 求均值
print(accuracy)
train_accuracy = accuracy.eval({X: X_train, Y: Y_train}) # eval运行计算图,类似于run
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("Train Accuracy:", train_accuracy)
print("Test Accuracy:", test_accuracy)
return train_accuracy, test_accuracy, parameters
# test
_, _, parameters = model(X_train, Y_train, X_test, Y_test)














 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









