






文章目录
1. 结构体类型的声明
前面学习操作符时,已经学习了结构体的知识,这里稍作复习。
1.1 结构体的回顾
挤乳沟是一些值的集合,这些值称为成员变量,结构的每个成员可以是不同类型的变量。
1.1.1 结构体的声明

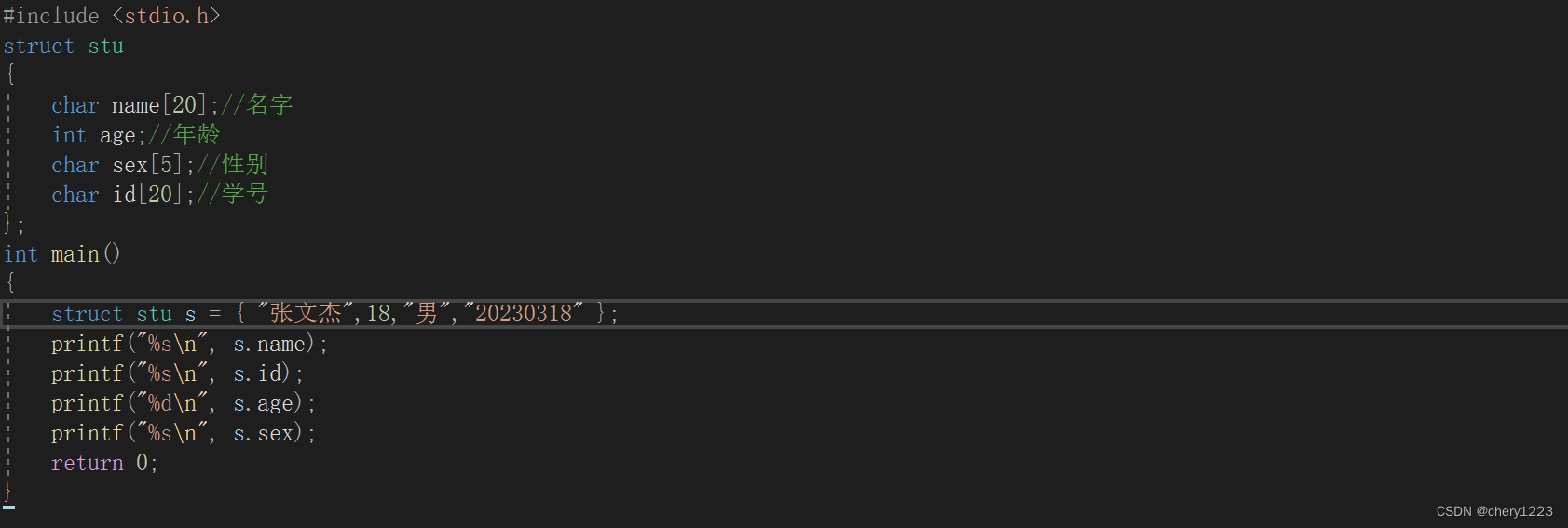
例如描述一个学生:
1.1.2 结构体变量的创建和初始化
1.2 结构体的特殊声明
在声明结构体时,可以不完全的声明。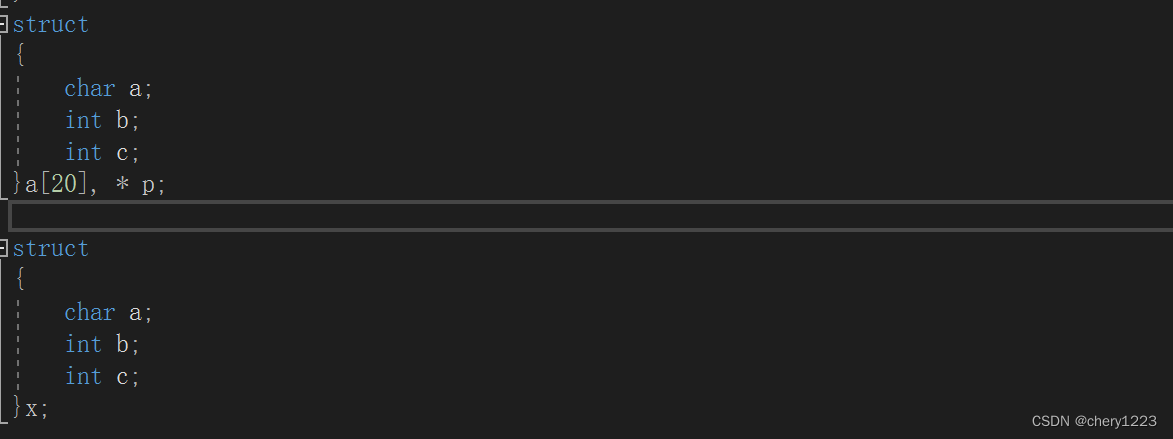
这时,我们可能有疑问:p等不等于&a?其实,编译器会报出警告,会把上面两个声明当成完全不同的两个类型,所以是非法的,如果匿名结构体类型,没有结构体类型重命名的话,基本上只能使用一次。
1.3 结构的自引用
在结构体中包含一个类型为该结构体本身的成员是否可以呢?
比如定义一个链表的节点: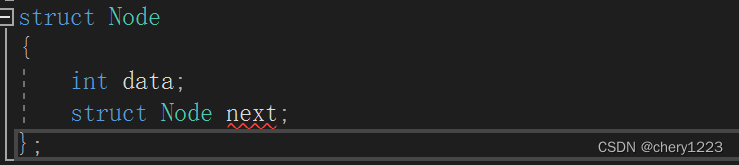
这时,我们看到编译器是会报错的,因为当结构体里面再包含一个结构体,这样不停包含下去,结构体就会变得无穷大,是不合理的。
正确的引用方式需要用到指针:
在结构体自引用的过程中,夹杂了typeof对匿名结构体类型重命名,也容易引入问题,比如:
因为Node是对前面的匿名结构体类型的重命名产生的,但是在匿名结构体内部提前使用Node类型来创建成员变量,这是不行的。解决方案如下:
2. 结构体内存对齐
现在我们需要深入讨论一下计算结构体的大小,这也是一个热门的考点:结构体内存对齐。
2.1 对齐规则
首先得掌握结构体的对齐规则:
- 结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
- 对齐数=编译器默认的一个对齐数与该成员变量大小的较小值。
- vs中默认的值为:8。
- Linux中gcc没有默认对齐数,对齐数就是成员自身大小。
- 结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
2.2 为什么存在内存对齐?
根据整理,大致有两个原因:
- 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些待定类型的数据,否则抛出硬件异常。
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对其的内存,处理器不得不两次内存访问,而对齐的内存访问仅需要一次访问。
总的来说:结构体的内存对齐是拿空间来换取时间的做法。
那么我们在设计结构体时,为了尽可能节省空间,我们可以让相同类型的成员在一起,使得所浪费空间变小。
2.3 修改默认对齐数
#pragma这个预处理指令,可以改变编译器的默认对齐数。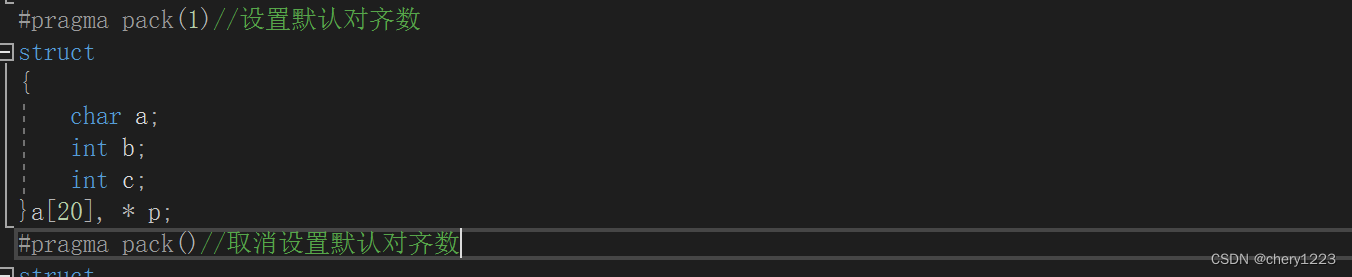
3. 结构体传参
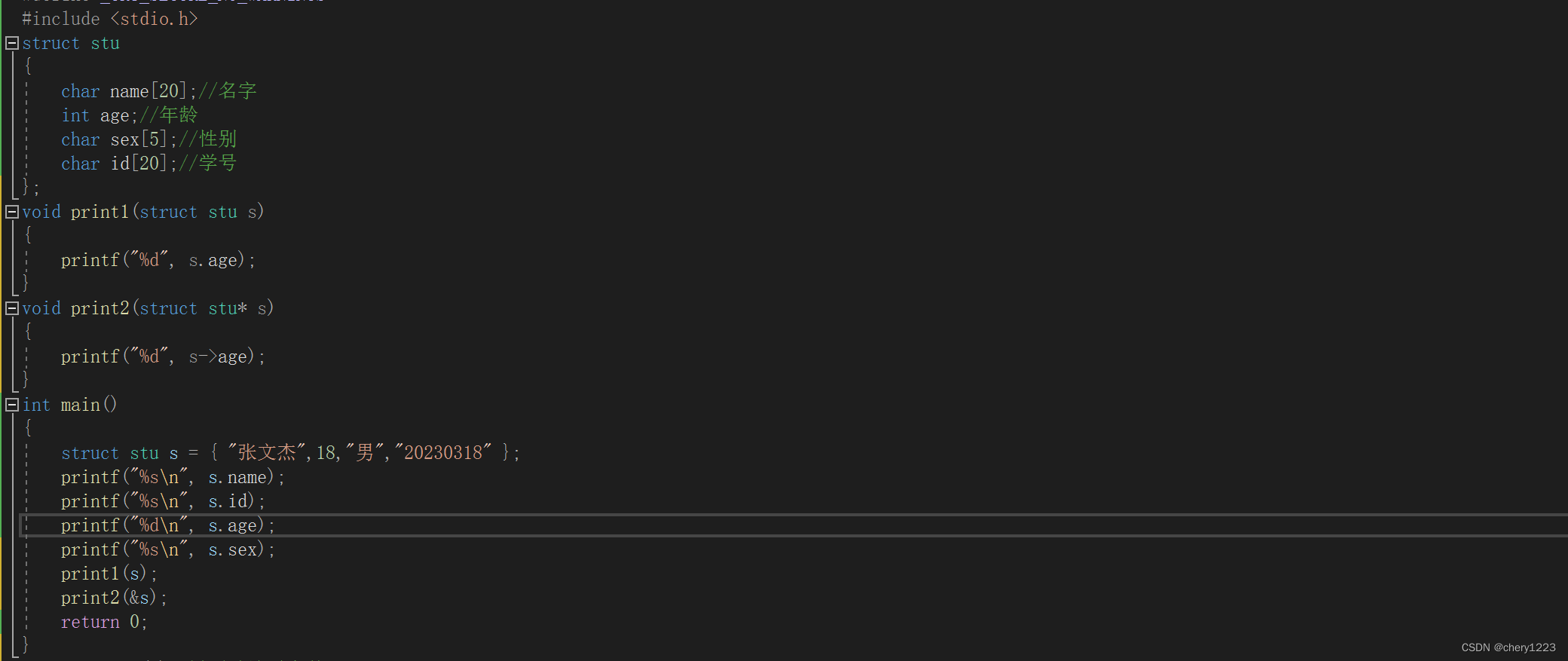
上面的print1和print2中,print2更好一些,应为函数传参时,参数时需要压栈的,就会有时间和空间上的系统开销。
结论:结构体传参的时候,尽可能传结构体地址
4. 结构体实现位段
结构体讲完就得讲结构体实现位段的能力。
4.1 什么是位段
位段的声明和结构是类似的,有两个不同:
- 位段的成员必须是int,unsigned int或signed int,在c99中位段成员的类型也可以选择其他类型。
- 位段的成员名后边有一个冒号和一个数字。
比如: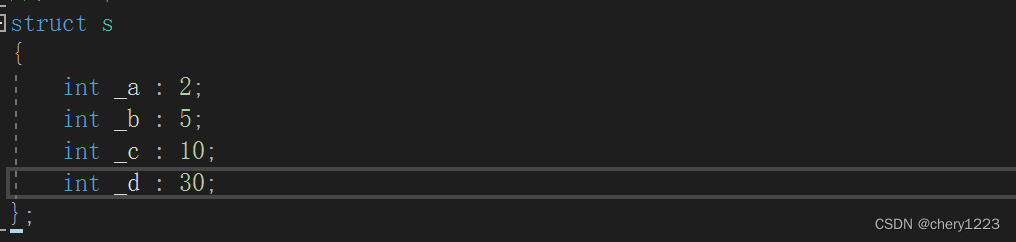
s就是一个位段类型。
那么位段s所占内存的大小是多少?
答案是8个字节。
4.2 位段的内存分配
- 位段的成员可以是int,unsigned int,signed int或者是char类型。
- 位段的空间上是按照需要以4个字节或者一个字节的方式来开辟的
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。

4.3 位段的跨平台问题
- int位段被当成有符号数还是无符号数是不确定的。
- 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,会在16位机器中出现问题)
- 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
- 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4.4 位段的使用
下面是网络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要几个bit位就能描述,这里使用位段,能够实现想要的效果,也节省了空间,这样网络传输的数据报大小也会较小一些,对网络的畅通是有帮助的。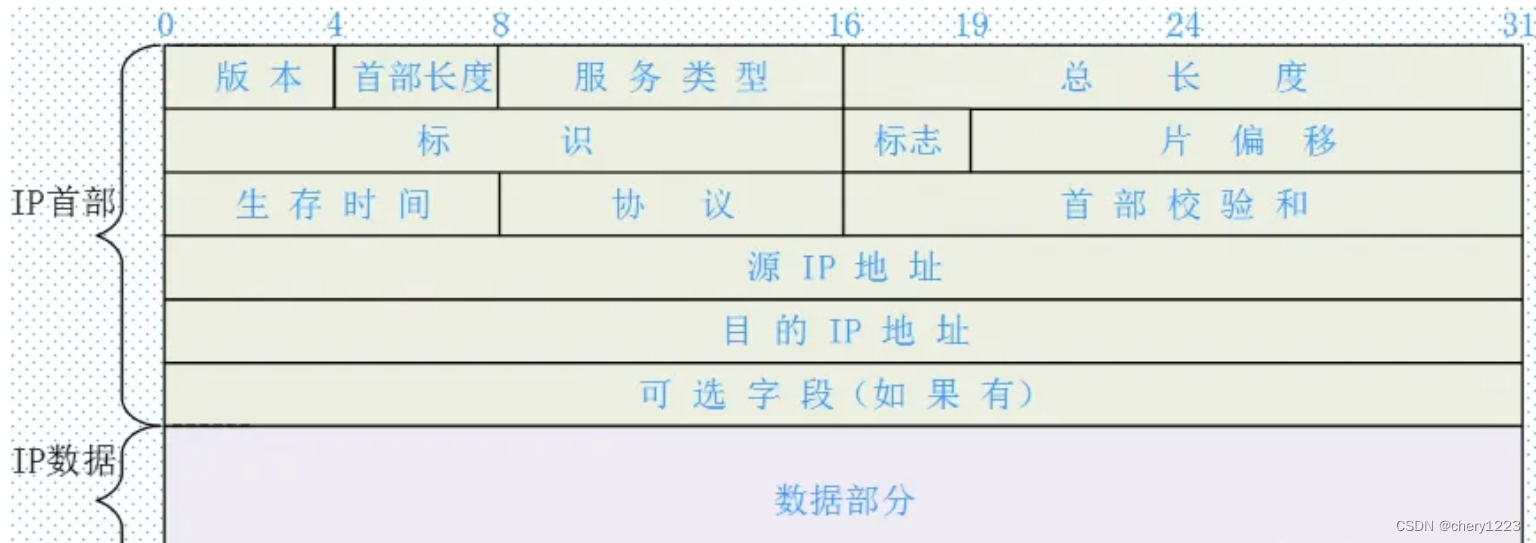
4.5 位段使用的注意事项
位段的几个成员共有同一个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的,内存中每个字节分配一个地址,一个字节内部的bit位是没有地址的。
所以不能对位段的成员使用&操作符,这样就不能使用scanf直接给位段的成员输入值,只能是先输入放在一个变量中,然后赋值给位段的成员。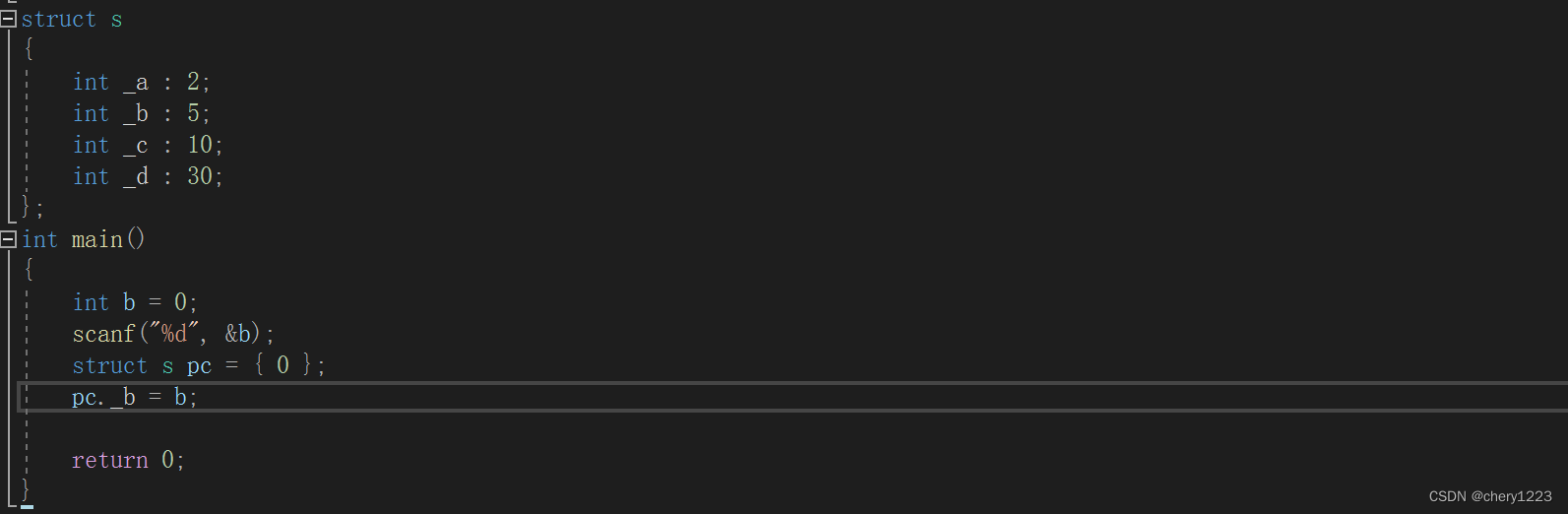
5. 联合体
5.1 联合体类型的声明
像结构体一样,联合体也是由一个或者多个成员构成,这些成员可以不同类型。
但是编译器只为最大的成员分配足够多的内存空间。联合体的特点是所有成员共用同一块内存空间。所以联合体也叫:共用体。
给联合体其中一个成员赋值,其他成员的值也跟着变化。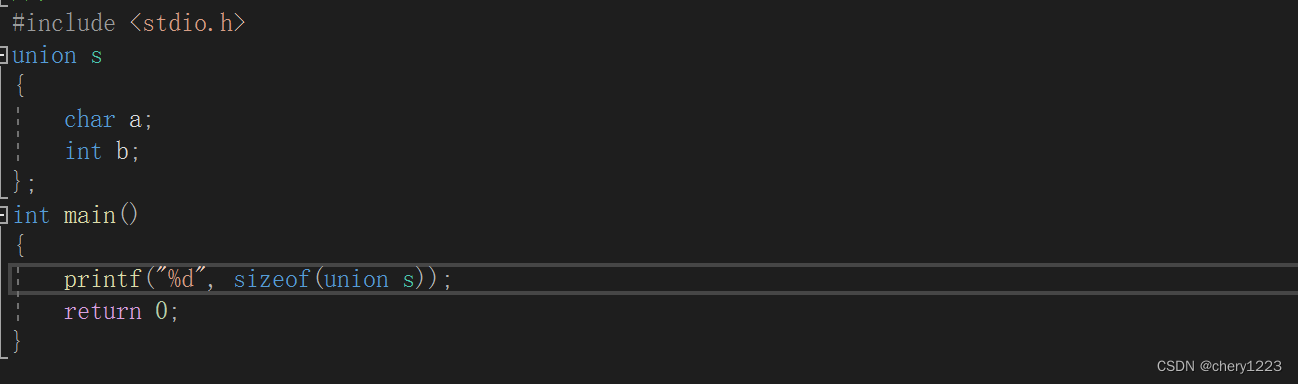
输出结果: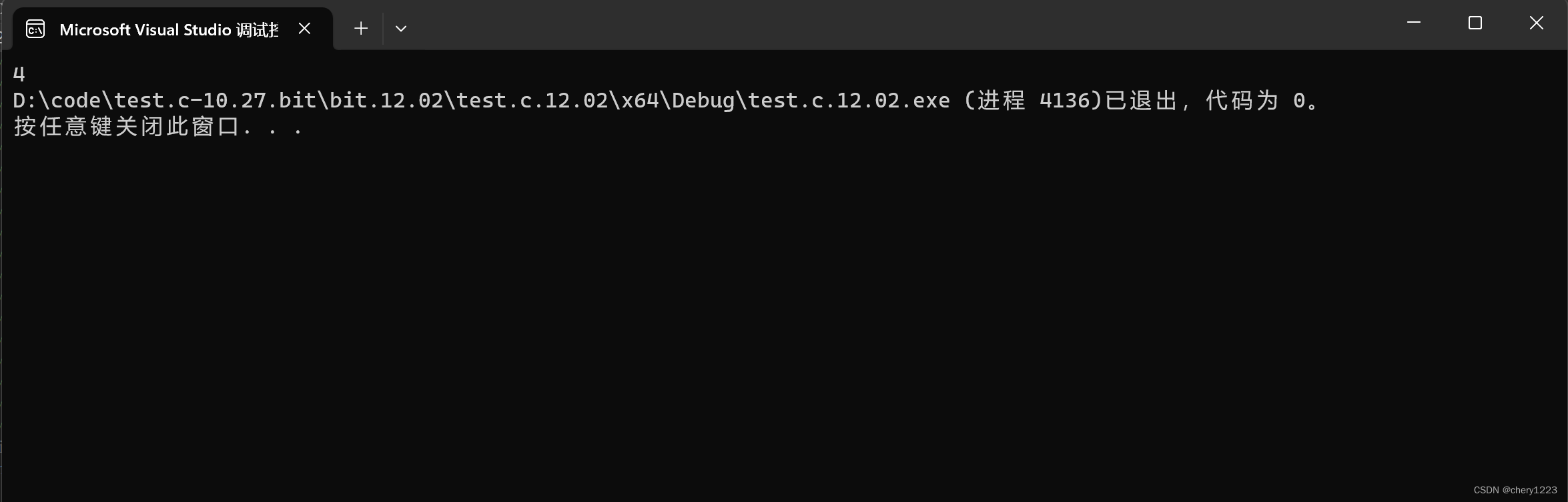
5.2 联合体的特点
联合的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为联合和至少得有能力保存最大的那个成员)。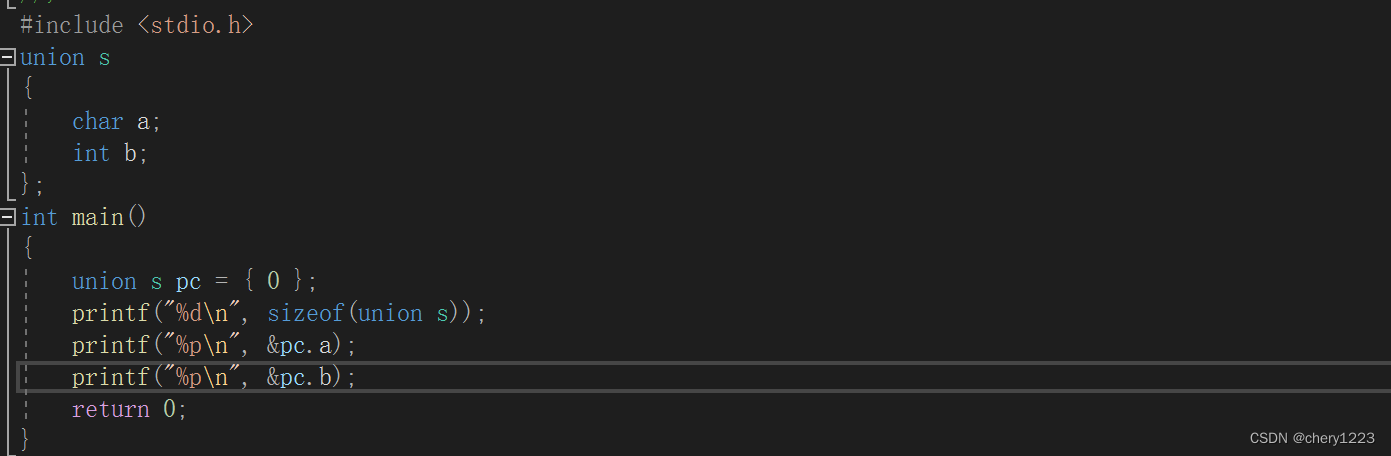
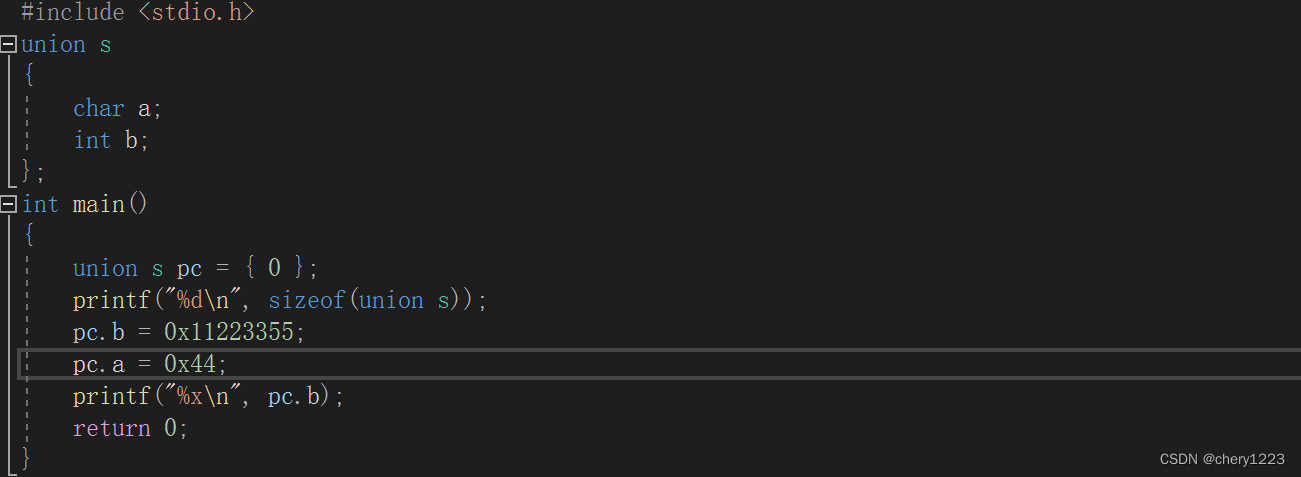
输出结果:
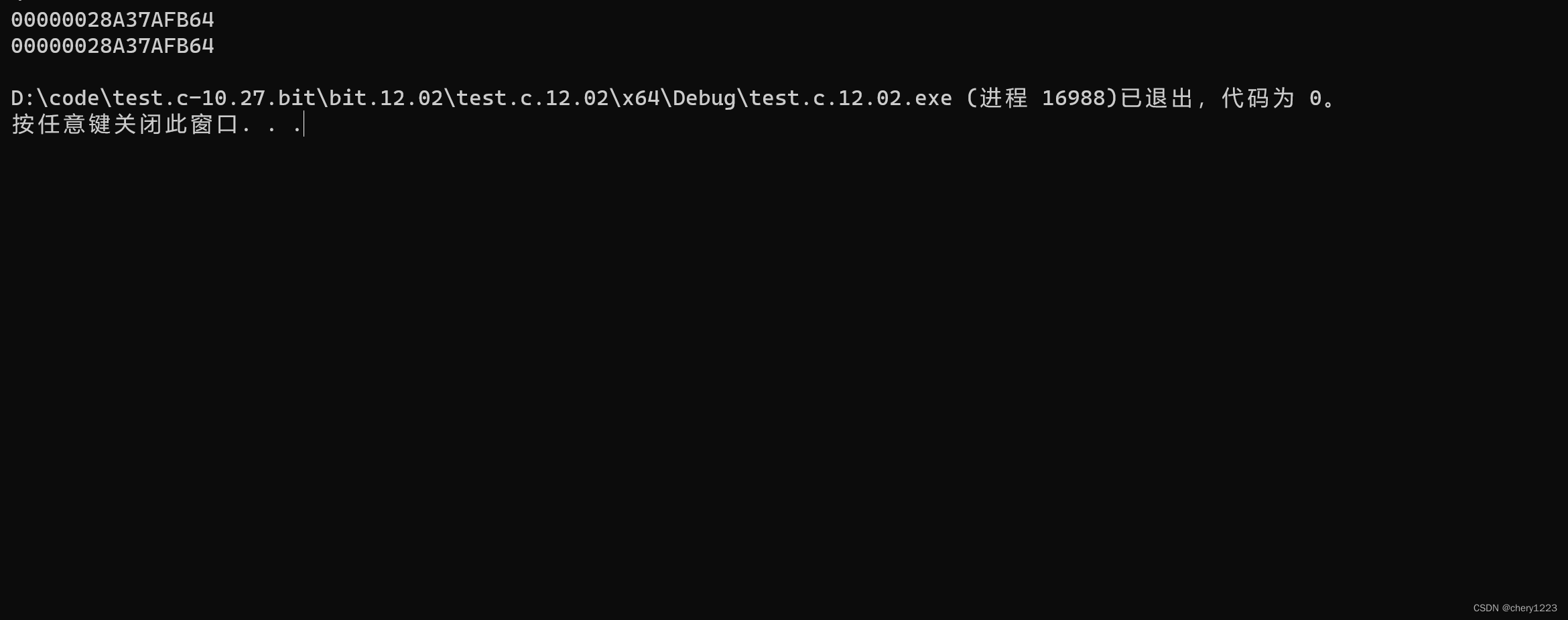
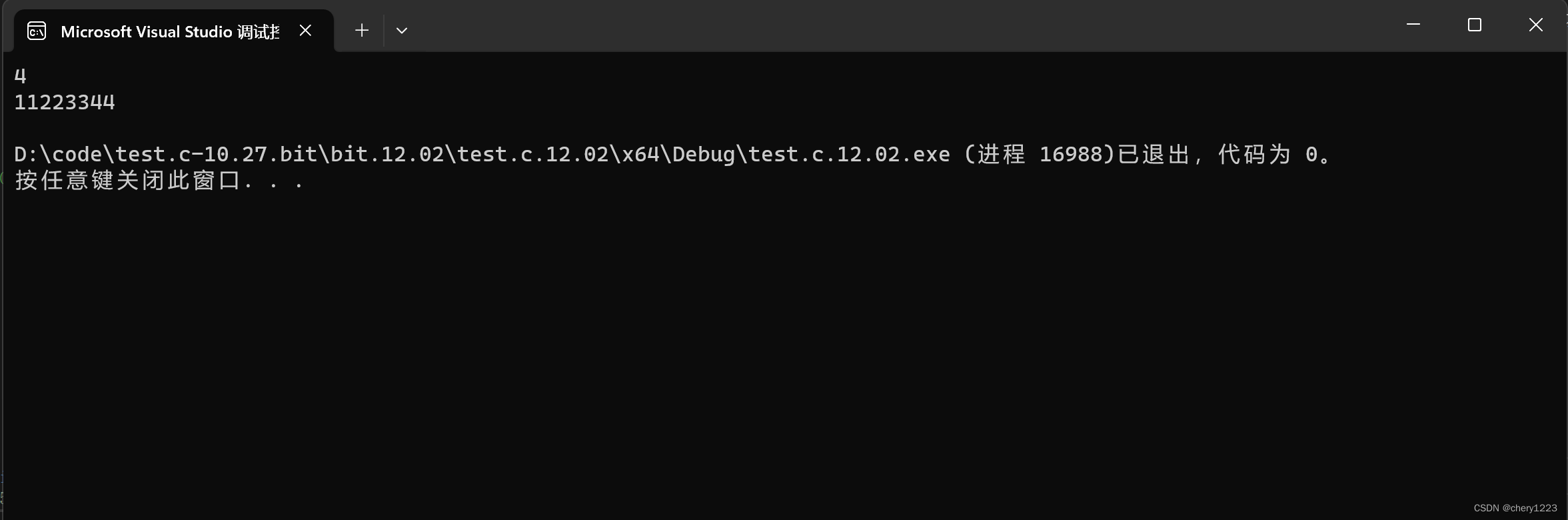
代码输出的两个地址一模一样,并且我们发现b的第四个字节的内容修改为44了。
我们仔细分析就可以画出,un的内存布局图。
5.3 相同成员的结构体和联合体对比
我们可以通过上述结构体和联合体的描述可以嘴比两者的内存分布情况。
5.4 联合体大小的计算
联合体的大小至少是最大成员的大小。
当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。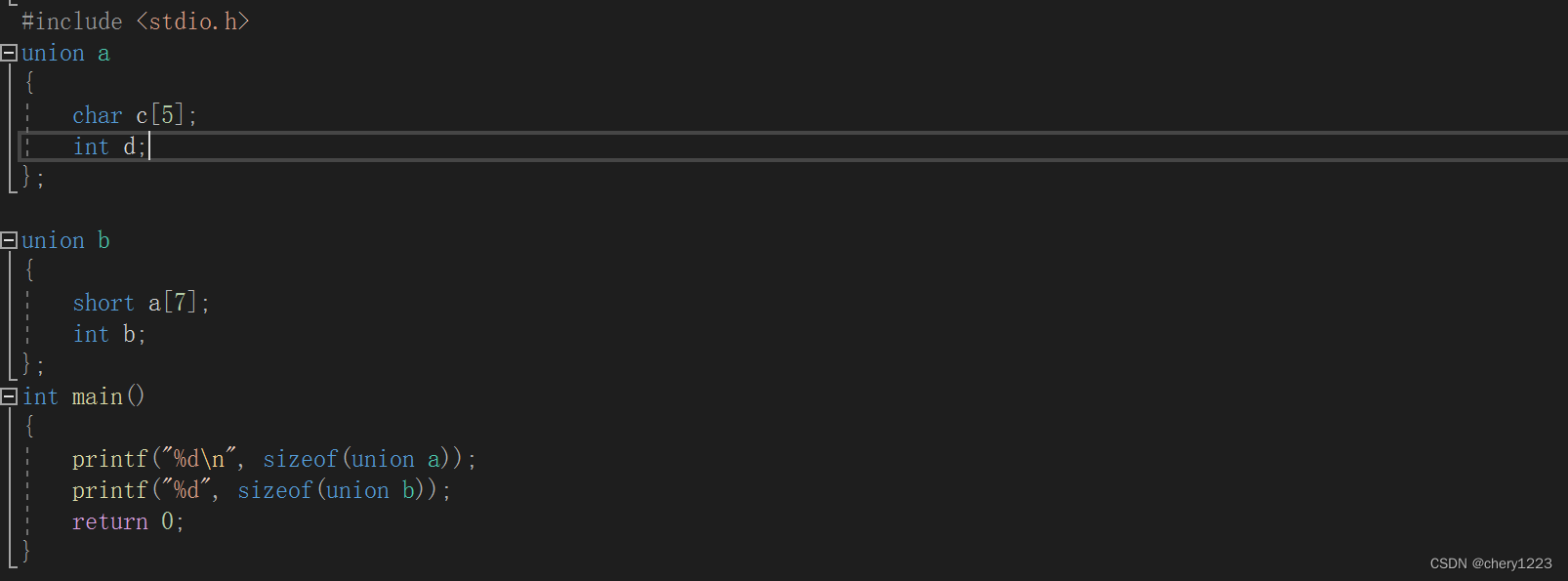
输出结果计算: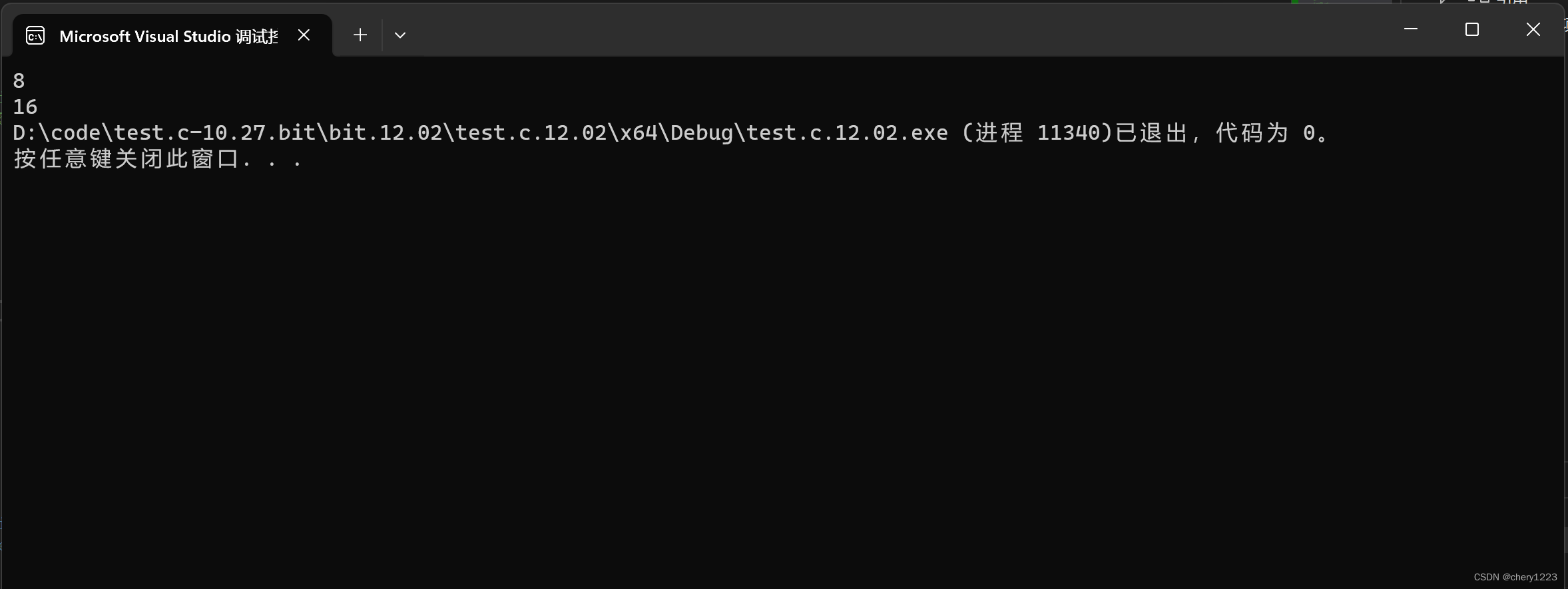
使用联合体是可以节省空间的,举例:
你如,我们要搞一个活动,要上线一个礼物兑换单,礼品兑换单中有三种商品:图书,杯子,衬衫。
每一种商品都有:库存量,价格,商品类型和商品相关的其他信息。
图书:书名、作者、⻚数
杯⼦:设计
衬衫:设计、可选颜⾊、可选尺⼨
这时,我们可以同时用结构体和联合体,因为如果一味地应用结构体的话,就会使得结构体的大小偏大,浪费很多内存,因为对于礼品兑换单中的商品来说,只有部分属性信息是常用的。
所以,我们就可以把公共属性单独写出来,剩余属于各种商品本身的属性使用联合体起来,这样就可以介绍所需的内存空间,一定程度上节省了内存。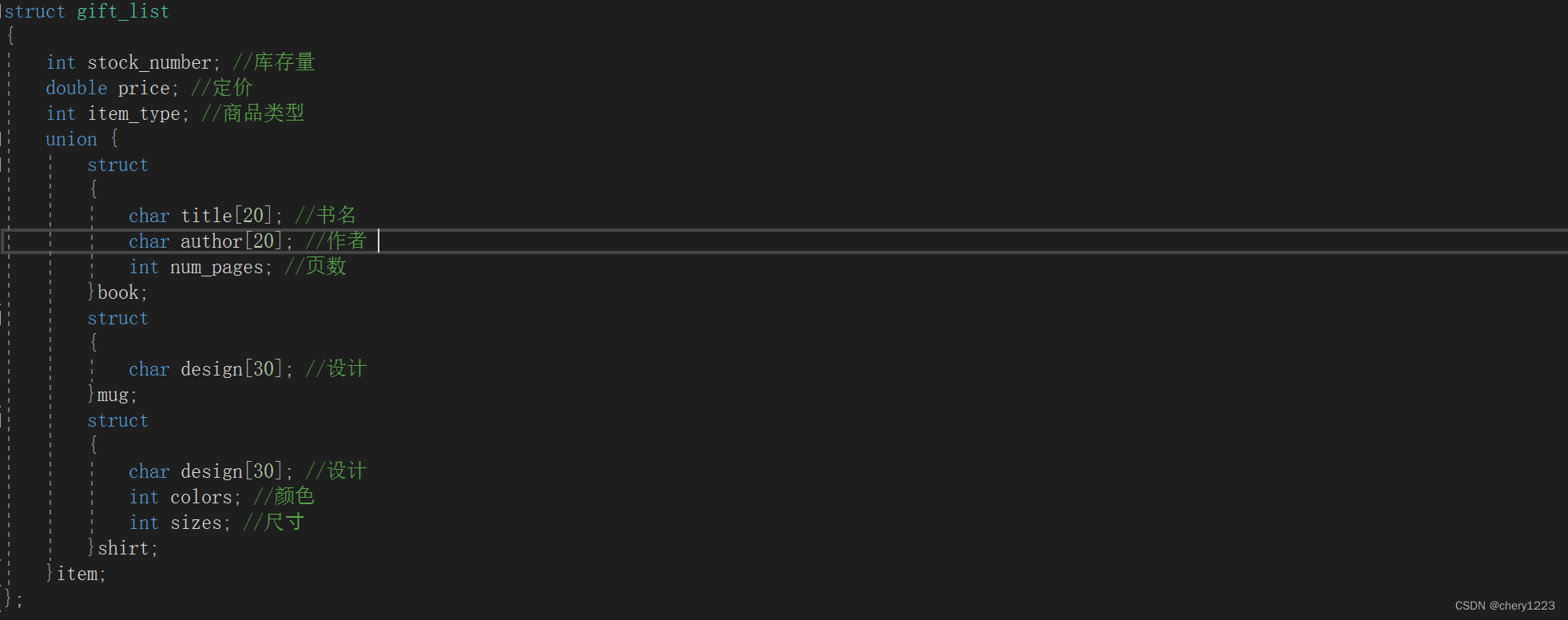
6. 枚举类型
6.1 枚举类型的声明
枚举顾名思义就是一一列举。
把可能的取值一一列举。
比如星期,性别等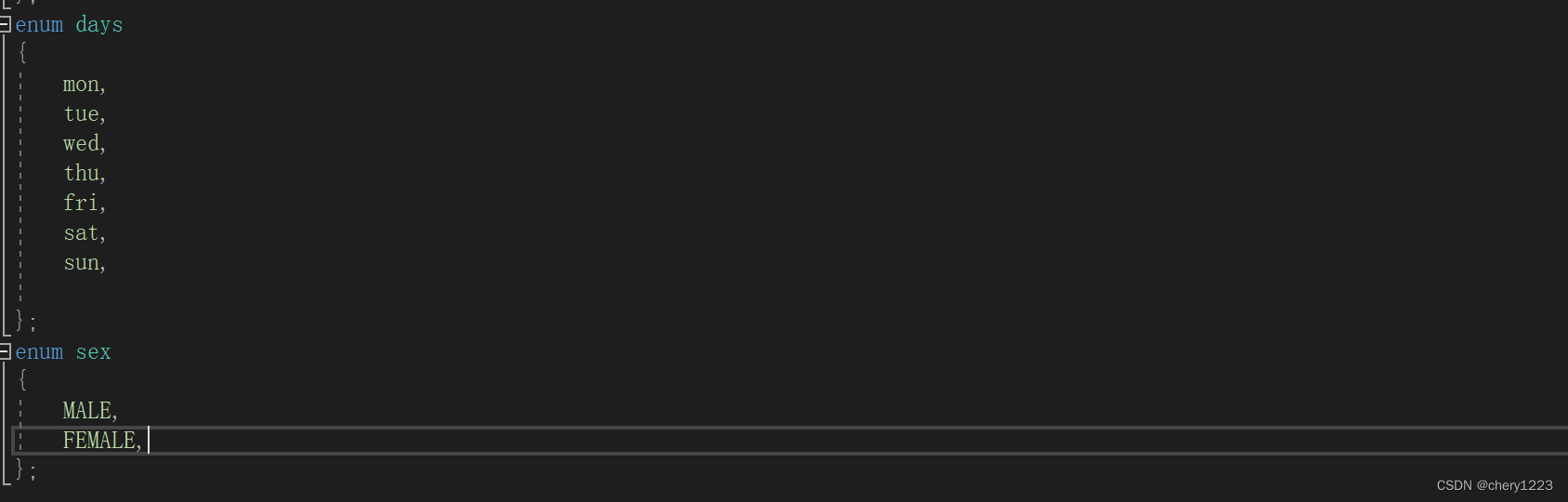
定义的enum days,enum sex都是枚举类型。
{}中的内容是枚举类型的可能取值,也叫枚举常量。
这些可能取值都是有值的,默认从0开始,依次递增1,当然在声明枚举类型的时候也可以赋初值。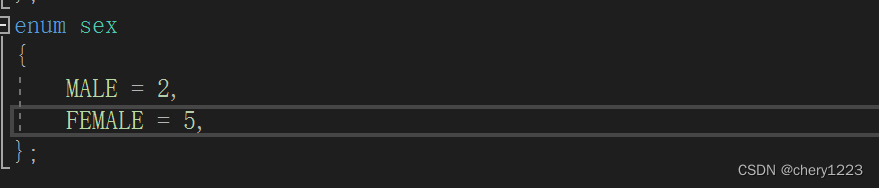
6.2 枚举类型的优点
为什么要用枚举
我们可以使用#define定义常量,为什么非要用枚举?
枚举的优点:
- 增加代码的可读性和可维护性
- 和#define定义的标识符比较枚举有类型检查,更加严谨。、
- 便于调试,预处理阶段会删除#define定义的符号。
- 使用方便,一次可以定义多个常量。
- 枚举常量是遵循作用域规则的,枚举声明在函数内,只能在函数内使用。
6.3 枚举类型的使用
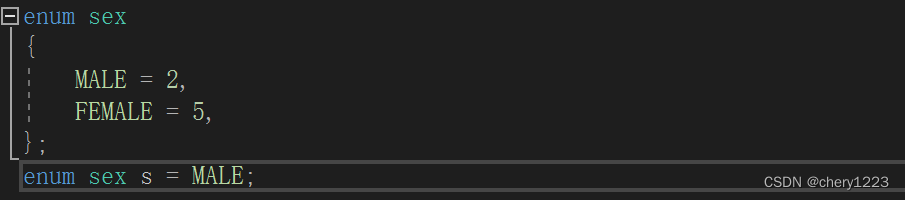
使用枚举常量给枚举变量赋值,但是有可能不能拿整数给枚举变量赋值。
完















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









