






DOM(文档对象模型)是针对HTML和XML文档的一个API,可将HTML/XML文档描绘成多层节点组成的结构:文档节点是每个文档的根节点。总共有12种节点类型,继承与同一个基类型(Node类型,IE不可以访问到Node类型)
//用nodeType属性表示节点类型
Node.ELEMENT_NODE(1);//元素节点
Node.ATTRIBUTE_NODE(2);//属性节点
Node.TEXT_NODE(3);//文本节点
Node.CDATA_SECTION_NODE(4);//用于XML的,表示CDATA域
Node.ENTITY_REFERENCE_NODE(5);//实体引用
Node.ENTITY_NODE(6);//实体
Node.PROCESSING_INSTRUCTION_NODE(7);//处理指令
Node.COMMENT_NODE(8);//注释节点
Node.DOCUMENT_NODE(9);//文档节点
Node.DOCUMENT_TYPE_NODE(10);//文档类型节点
Node.DOCUMENT_FRAGMENT_NODE(11);//
Node.NOTATION_NODE(12);可通过nodeName/nodeValue获取节点名称和类型
if(someNode.nodeType == 1) {
value = someNode.nodeName;
}其中每个节点之间的关系如下:每个节点都有一个childNode属性,保存着一个NodeList对象(类数组,动态变化的),所有节点有一个ownerDocument指向文档的文档节点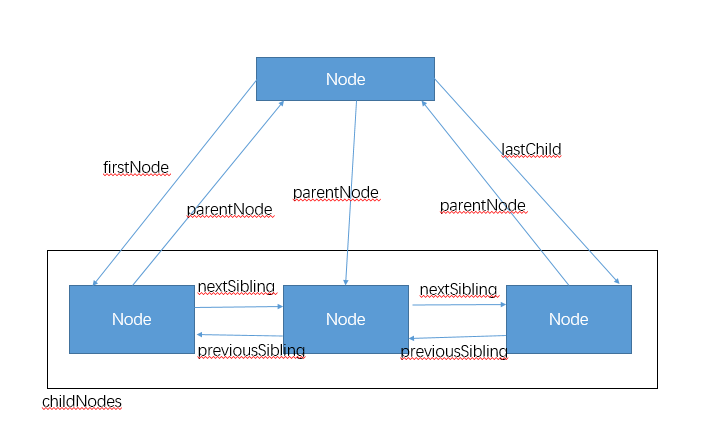
对节点的子节点的操作可有以下:
appendChild():向childNodes列表末尾添加新节点,任何DOM节点不能同时出现在文档的多个位置上。
insertBefore()、replaceChild()、removeChild()
每个节点都有的方法:
cloneChild():参数true表示深复制、false表示浅复制
normalize():处理文本文档树的文本节点
Document类型:
document对象是HTMLDocument(继承自Document类型)的一个实例。
所有浏览器支持document.documentElement(指向html)和document.body(指向body)属性,Document还有一个可能的子节点是DocumentType(<!DOCTYPE>),不同浏览器对document.doctype和注释的处理不同。
可以通过document.title/document.URL/document.domain(通过改变这个可以是不同域的文档通信)获取文档信息。
查找元素方法:getElementById(id)/getElementByTagName(tag_name)/getElementByName(name)
Element类型:
提供对元素标签名、子节点及特性的访问。
通过nodeName或者tagName可以访问元素类型
var element = document.getElementById("myElement");
if(element.tagName.toLowerCase() == "div") {
//.....
}所有HTML元素都是由HTMLElement或者更具体的子类型来表示的,可以直接访问和修改element的属性:id、title、lang、dir、className(css样式类)等等,也可以通过getAttribute()、setAttribute()、removeAttribute()方法操作特性。(在其他浏览器中不适用setAttribute()方法添加自定义属性不会成为元素的特性,而在IE中可以)。
Element类型有attributes属性,里面包含了一个NamedNodeMap(动态集合),有getNamedItem(name)、removeNamedItem(name)、setNamedItem(node)、item(pos)等方法:
//获取元素的id特性的两中表示方法
var id = element.attributes.getNamedItem("id").nodeValue;
var id = element.attributes["id"].nodeValue;可使用document。createElement()创建新元素,参数可以是元素标签名,也可以是html片段
var div = document.createElement("div");
div.id = "myNewDiv";
//或者如下
var div = document.createElement("<div id=\"myNewDiv\"></div>";
Text类型:
表示纯文本内容。有如下方法:
appendData(text)
deleteData(offset,count)
insertData(offset,text)
replaceData(offset,count,text)
splitText(offset):将文档分成两部分
subStringData(offset,count)
normalize():用于规范化文本节点,不能存在相邻的文本节点,用normalize()合并节点
DocumentFragment类型:
文档片段节点可以当作一个仓库来使用,用于存放可能添加到文档中的节点,在文档中不占据位置
//先定义一个整体的fragment,一次性添加三个li,防止多次渲染
var fragment = document.createDocumentFragment();
var ul = document.getElementById("myList");
var li = null;
for(var i = 0;i<3;i++) {
li = document.createElement("li");
li.appendChild(document.createTextNode("Item"+(i+1)));
fragment.appendChild(li);
}
ul.appendChild(fragment);















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









