






Hadoop 安装模式
Hadoop 一共有三种安装模式:
- Hadoop 单机安装
-
- Hadoop 运行在单台服务器上,无需进行其他配置即可运行。
- 单Java进程,方便进行测试。
- Hadoop读取的是本地的文件系统,而非HDFS.
- Hadoop 伪分布安装
-
- Hadoop 运行在单台服务器上,需要修改配置文件。
- 单台服务器运行多个角色 Namenode、DataNode、NodeManager、ResourceManager
- Hadoop 从HDFS读取数据。
- Hadoop集群安装
-
- Hadoop 运行在多台服务器,需要对不同进程进行规划,运行在不同节点上。
- 通过hadoop 配置文件完成进程角色的分配
- 需要通过Zookeeper 组件实现Namenode和 ResourceManager 的HA
Hadoop 安装前环境准备---关闭防火墙
防火墙是对我们的服务器进行的一种保护,但是有时候也妨碍Hadoop集群间的相互通讯,为了学习的方便,我们需要关闭防火墙。 CentOS 7.0默认使用的是firewall作为防火墙。
关闭防火墙
- centos 7.0 关闭防火墙
-
- systemctl stop firewalld.service #停止firewall
- systemctl disable firewalld.service #禁止firewall开机启动
- firewall-cmd --state #查看默认防火墙状态(关闭后显示not running,开启后显示running)
- centos 6.0 关闭防火墙
-
- 临时性关闭 service iptables stop/start
- 永久性关闭 chkconfig iptables off/on 需要重启服务器
- 查看防火墙状态 service iptables status
Hadoop 安装前环境准备---绑定hostname与IP
为了方便操作和访问hadoop集群,我们需要绑定hostname与IP
绑定host name 与IP
- 修改/etc/hosts配置文件 vi /etc/hosts
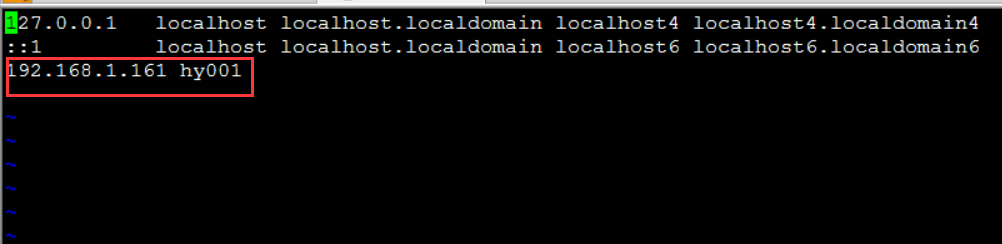
Hadoop 安装前环境准备---创建Hadoop用户
hadoop集群搭建的过程中,为了集群安全考虑,我们一般不直接使用超级用户root,而是需要我们新建一个新的用户,比如hadoop。
创建Hadoop用户
- 创建hadoop用户命令
-
- useradd -m hadoop
- 为hadoop用户设置密码
-
- passwd hadoop
Hadoop 安装前环境准备---SSH免密码登录
Hadoop 启动或者停止脚步是需要通过SSH发送命令启动相关守护进程,为了避免每次启动或者停止Hadoop输入密码进行验证,需设置免密码登录
配置SSH免密码登录
- 切换到hadoop用户
-
- su hadoop
- 创建 .ssh 文件
-
- mkdir .ssh
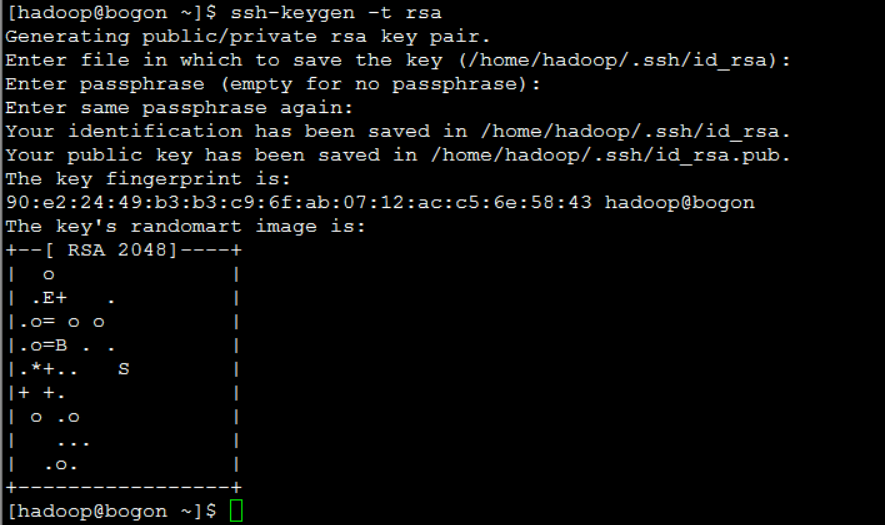
- 生成rsa秘钥
-
- ssh -keygen -t rsa (创建完一直回车)
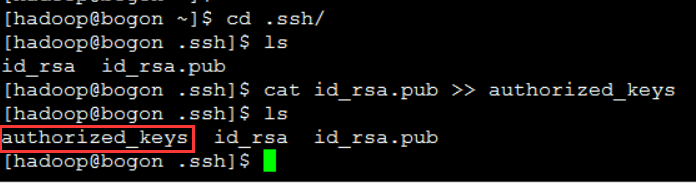
生成到认证文件中
- cat idrsa.pub >> authorized_keys

- 对.ssh目录进行授权
-
- chmod 700 .ssh
- chmod 600 .ssh/* 对.ssh目录下的
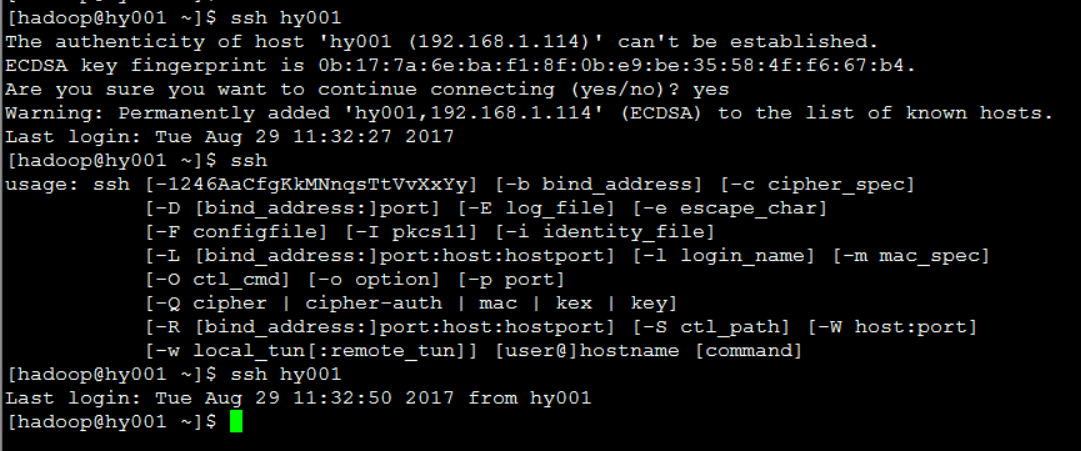
- SSH免密码登录
-
- ssh hy001 第一次会有确认操作 第二次再登录就可以不用输入密码登录了
Hdoop 安装前环境准备---jdk安装
因为hadoop 运行环境是JVM,所以我们需要提前安装和配置jdk.
jdk安装
- 下载并解压
-
- java jdk 下载地址:http://www.oracle.com/technetwork/java/javase/archive-139210.html
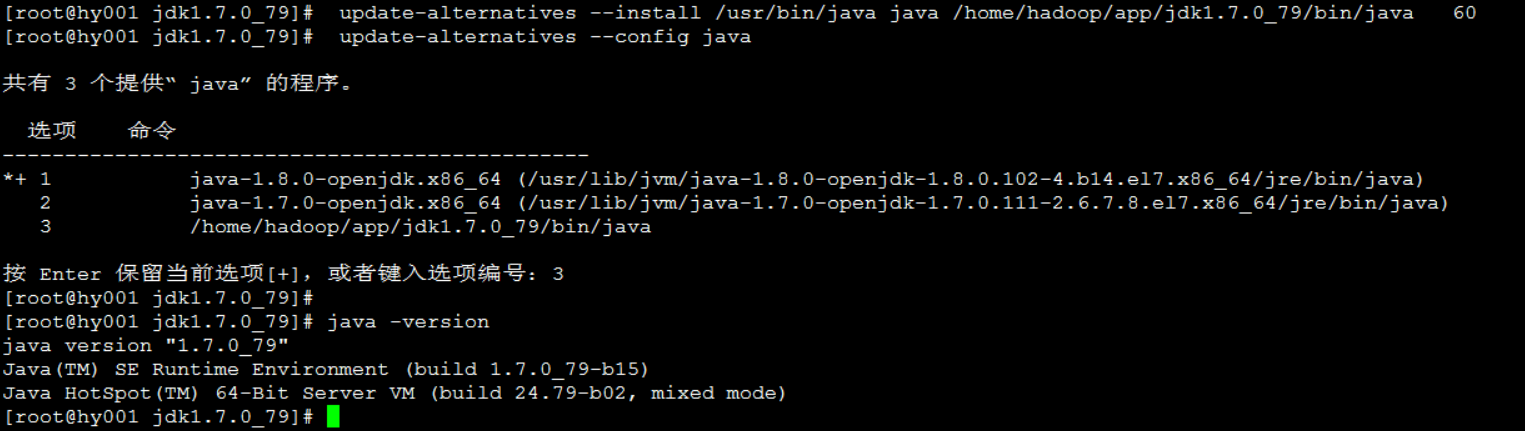
centos7 修改openjdk 方法:
[root@hy003 app]# update-alternatives --install /usr/bin/java java /home/hadoop/app/jdk1.7.0_79/bin/java 60
[root@hy003 app]# update-alternatives --config java
共有 3 个提供“java”的程序。
选项 命令
*+ 1 java-1.8.0-openjdk.x86_64 (/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.102- 4.b14.el7.x86_64/jre/bin/java)
2 java-1.7.0-openjdk.x86_64 (/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64/jre/bin/java)
3 /home/hadoop/app/jdk1.7.0_79/bin/java
按 Enter 保留当前选项[+],或者键入选项编号:3
[root@hy003 app]# java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)Hadoop 单机安装
Hadoop 单机安装
- 下载并解压Hadoop2.6安装包
-
- 下载地址:https://archive.apache.org/dist/hadoop/common/
- 解压:tar -zxvf hadoop-2.6.0.tar.gz
- 验证单机模式是否安装成功 bin/hadoop version

- 测试运行
- 在hadoop-2.6.0 下新建一个 txt 文件 joe.txt
vi joe.txt
hadoop qiaohaiyan
hadoop qiaohaiyan
hadoop qiaohaiyan
hadoop qiaohaiyan- 测试运行单机版
输入命令: bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount joe.txt output 查看运行结果:cat output/part-r-00000

Hadoop 伪分布集群安装
配置hadoop相关配置文件,
创建hadoop安装目录软连接,
配置hadoop环境变量,
创建hadoop相关数据目录,
格式化Namenode, 启动Hadoop伪分布集群 ,
Web UI 查看HDFS、 YARN
测试运行Hadoop伪分布集群
配置hadoop相关配置文件

配置hadoop相关配置文件,
创建hadoop安装目录软连接,
配置hadoop环境变量,
创建hadoop相关数据目录,
格式化Namenode,
启动Hadoop伪分布集群 ,
Web UI 查看HDFS、 YARN
测试运行Hadoop伪分布集群
配置hadoop相关配置文件
core-site.xml 文件配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hy001:9000</value>
<!--设置HDFS服务的主机名和端口号 -->
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/data/tmp</value>
<!--这里的路径默认是 NameNode 、DataNode 等存放数据的公共临时目录 -->
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
<!-- 不管谁提交的都变成 hadoop 提交的 -->
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml 文件配置
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
<description>Determineswhere on the local filesystem the DFS name node should store the name table. Ifthis is a comma-delimited list of directories then the name table is replicatedin all of the directories, for redundancy. </description>
<final>true</final>
<!-- 设置HDFS中的Namenode 文件目录 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
<description>Determineswhere on the local filesystem an DFS data node should store its blocks. If thisis a comma-delimited list of directories, then data will be stored in all nameddirectories, typically on different devices.Directories that do not exist areignored.
</description>
<final>true</final>
<!-- 设置HDFS中的datanode 文件目录 -->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<!-- 设置数据块副本 -->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<!-- hdfs的访问权限设置为false -->
</property>
</configuration>
mapred-site.xml 文件配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!-- 指定运行 mapreduce 的环境为yarn -->
</property>
</configuration>
yarn-site.xml 文件配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!-- 为了能够运行MapReduce程序,需要让NodeManager在启动时加载shuffle server -->
</property>
</configuration>slaves 文件配置
将文件中localhost 修改成 hy001创建hadoop安装目录软连接 配置hadoop环境变量
- 创建hadoop软连接 执行 ln -s hadoop-2.6.0 hadoop
-
配置hadoop环境变量 vi ~/.bashrc
JAVA_HOME=/home/hadoop/app/jdk HADOOP_HOME=/home/hadoop/app/hadoop CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH HADOOP_HOME -
使环境变量生效 执行 source ~/.bashrc
创建hadoop相关目录
[hadoop@hy001 ~]$ pwd
/home/hadoop
[hadoop@hy001 ~]$ mkdir -p data/tmp
[hadoop@hy001 ~]$ mkdir -p data/dfs/name
[hadoop@hy001 ~]$ mkdir -p data/dfs/data
[hadoop@hy001 ~]$ ls
app data
格式化Namenode
[hadoop@hy001 hadoop]$ bin/hdfs namenode -format
启动启动Hadoop伪分布集群
sbin/start-all.sh
查看各节点启动情况: jps
[hadoop@hy001 hadoop]$ jps
7080 SecondaryNameNode
7218 ResourceManager
8217 Jps
6806 NameNode
6901 DataNode
7311 NodeManager
Web UI 查看HDFS、 YARN
访问HDFS 因为咱们没配置 HDFS 端口号 默认的为 50070
http://192.168.1.114:50070
访问 yarn 默认端口为 8088
http://192.168.1.114:8088
测试运行Hadoop伪分布集群
创建一个目录 qiao
[hadoop@hy001 hadoop]$ bin/hdfs dfs -mkdir /qiao
[hadoop@hy001 hadoop]$ bin/hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2017-08-29 17:22 /qiao
将joe.txt 文件放到 qiao这个目录中
[hadoop@hy001 hadoop]$ bin/hdfs dfs -put joe.txt /qiao
[hadoop@hy001 hadoop]$ bin/hdfs dfs -ls /qiao
Found 1 items
-rw-r--r-- 1 hadoop supergroup 72 2017-08-29 17:24 /qiao/joe.txt
[hadoop@hy001 hadoop]$ jps
8997 Jps
7080 SecondaryNameNode
7218 ResourceManager
6806 NameNode
6901 DataNode
7311 NodeManager
执行hadoop的 wordcount 计算命令
[hadoop@hy001 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /qiao/joe.txt /qiao/output
[hadoop@hy001 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount hdfs://192.168.1.114:9000/qiao/joe.txt hdfs://192.168.1.114:9000/qiao/output2
查看运行结果
[hadoop@hy001 hadoop]$ bin/hdfs dfs -cat /qiao/output/*
hadoop 4
qiaohaiyan 4
[hadoop@hy001 hadoop]$ 














 188
188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









