






一、找到百度指数对应的数据
1.1、
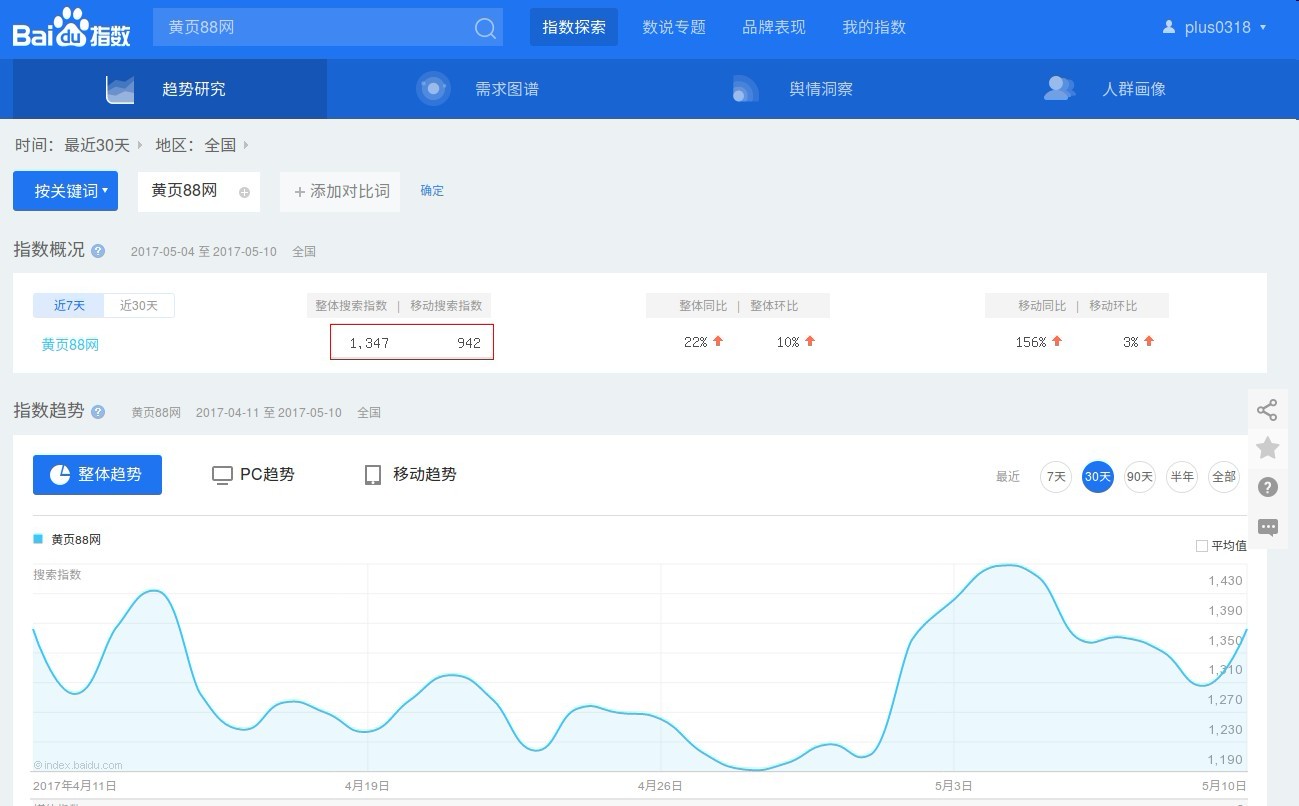
1.2、
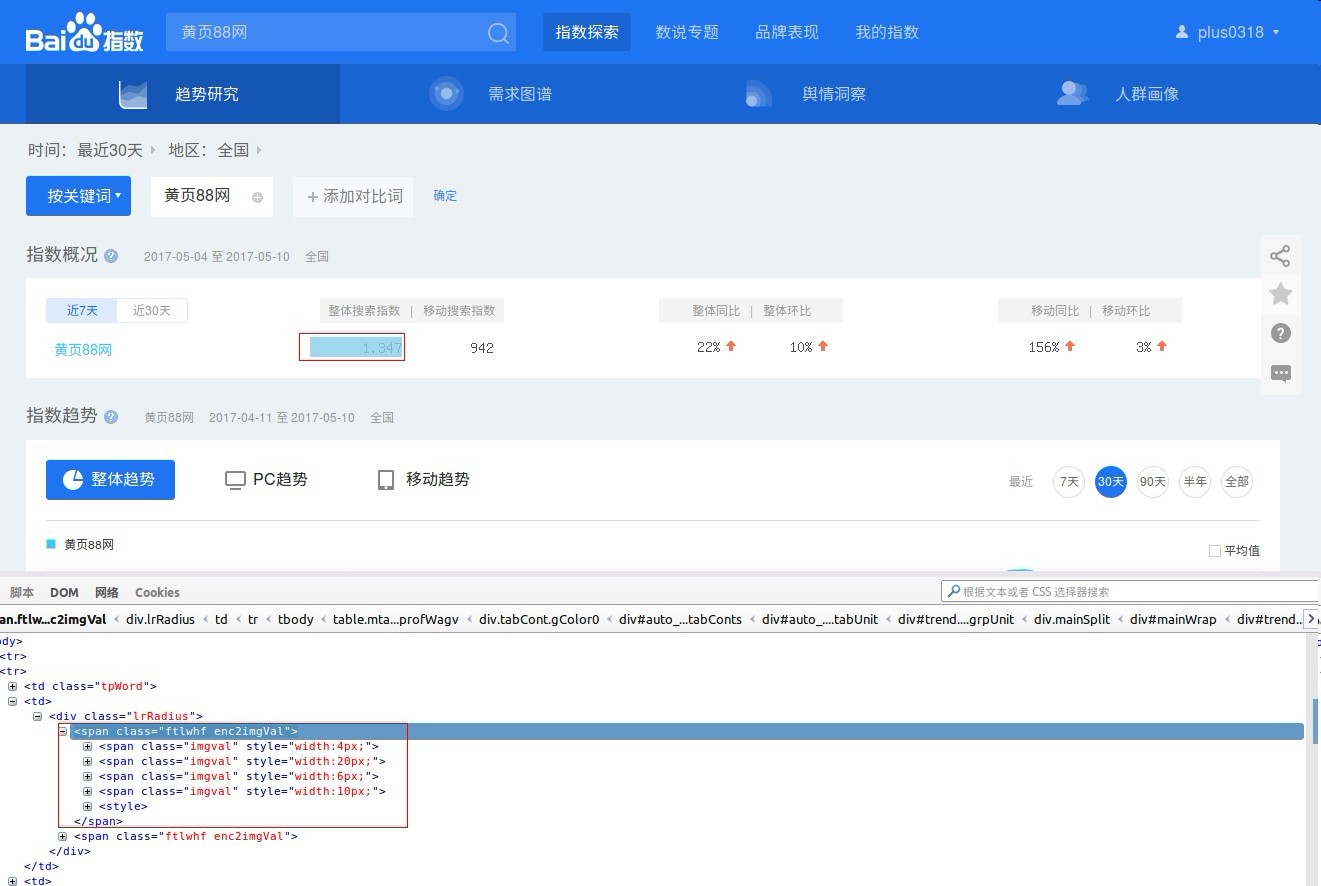
1.3、
结论:毛文本都找不着啊。根本就找不着根于百度指数数字相关的任何文本。
但是在style中找着了一个这个
![]()
将这个字符串与index.baidu.com拼起来,放进浏览器。会得到一个下载图片,这个图片打开来是这个样子滴。
![]()
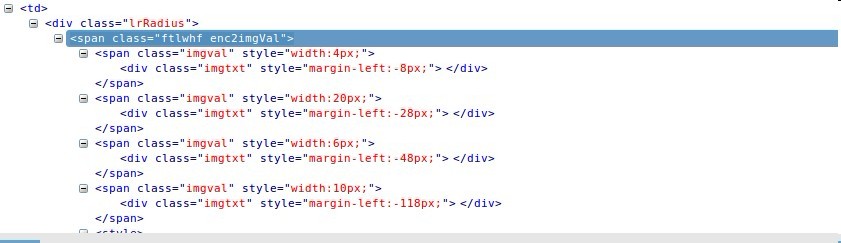
可以看到这张图片中包含了相对应的百度指数中的数字。
只不过,百度通过加密,以style-css的形式,显示出相对应的"图片形"的数字。
从这个角度来看.想要从百度加密原理的方式来"破解"指数,是比较困难的。
二、
其困难有二、
2.1、没有办法确切的知道这套加密方式,可能百度有几套加密方法,可能刷新一次,加密方式就换了一种。(我试过,刷新过后,背景图片和css都换了。)所以“破解”这种加密方式是及其困难的。
2.2、在以后执行过程中,如果百度增加了加密方式,或者更换了加密方式,就彻底“懵逼”。
三、
那我们能不能尝试另外一种方式来采集百度指数呢?
当时是有的,只不过稍微“笨”一些。
思路
3.1、像人一样打开浏览器
3.2、像人一样打开相应的百度指数的页面
3.3、让机器定位百度指数的x,y坐标
3.4、截屏
3.5、在截图中找到第3.3部记录下来的坐标。截小图
3.6、识别图中的数字
技术细节详见:利用python+selenium_phantomjs批量获取百度指数 第二步 技术细节
这里只贴了一个主文件。全部代码请见我的公众号“爬虫张小呆”

有代码经验的同学请见我的github:
https://github.com/plus0318/BaiduIndex















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









