





百度指数很多时候在我们做项目的时候会很有帮助,从搜索引擎的流量端给到我们一些帮助,比如:家具行业的销量跟"装修","新房","二手房"等关键词是什么关系等等,技术培训行业那中语言现在能挣大钱,搜搜"Python","Scala","Spark"看这样,等等诸如此类。直接利用百度指数的视图是比较方便、直接的,但有时候我们需要拿到具体的数据进行二次加工,那怎么获取百度指数数据呢?

如果你是Python 大牛,你可能花点小时间搞个全自动的Python脚本,从登录到抓取,再到存储,甚至之后的数据处理、可视化都不费吹灰之力。但是,杀鸡焉用牛刀~~,且看下面
- 登录你的百度账户之后,粘贴你当前的Cookies。不Python大牛的地方就是这里,你需要每次都要粘贴你的当前Cookies,因为它隔一段时间就会失效!
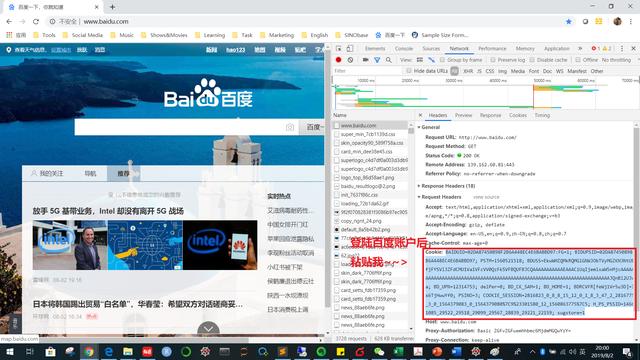
- 替换下面COOKIES的内容
COOKIES = """BAIDUID=02DA87450898F2B6A448EC4E6BABBD97:FG=1; BIDUPSID=02DA87450898F2B6A448EC4E6BABBD97; PSTM=1560521518; BDUSS=EkwWHZQMkRQMGlGNWJObTVyMGZKN3NtUEtNfjFYSVl3ZFdCMU1Va1VFcVV0QzFkSVFBQUFBJCQAAAAAAAAAAAEAAACiUqIjemlxaW5nMjcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJQnBl2UJwZda; BD_UPN=12314753; delPer=0; BD_CK_SAM=1; BD_HOME=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=3; COOKIE_SESSION=2816823_0_8_8_15_12_0_1_8_3_47_2_2816775_0_3_0_1564379083_0_1564379080%7C9%23301580_12_1560863775%7C5; H_PS_PSSID=1466_21085_29522_29518_29099_29567_28839_29221_22159; sugstore=1; BDSVRTM=235"""- 修改主代码里的关键词列表,后面就靠你了,自己修修改改又能用三年。
from urllib.parse import urlencodefrom collections import defaultdictimport datetimeimport requestsimport jsonimport pandas as pd"""数据轮子,2019-07"""# # # # # # # # # # # # # # # # # # # # # # ## 登录之后,百度首页的请求cookies,必填 !!!# # # # # # # # # # # # # # # # # # # # # # #COOKIES = """BAIDUID=02DA87450898F2B6A448EC4E6BABBD97:FG=1; BIDUPSID=02DA87450898F2B6A448EC4E6BABBD97; PSTM=1560521518; BDUSS=EkwWHZQMkRQMGlGNWJObTVyMGZKN3NtUEtNfjFYSVl3ZFdCMU1Va1VFcVV0QzFkSVFBQUFBJCQAAAAAAAAAAAEAAACiUqIjemlxaW5nMjcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAJQnBl2UJwZda; BD_UPN=12314753; delPer=0; BD_CK_SAM=1; BD_HOME=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=3; COOKIE_SESSION=2816823_0_8_8_15_12_0_1_8_3_47_2_2816775_0_3_0_1564379083_0_1564379080%7C9%23301580_12_1560863775%7C5; H_PS_PSSID=1466_21085_29522_29518_29099_29567_28839_29221_22159; sugstore=1; BDSVRTM=235"""headers = { 'Host': 'index.baidu.com', 'Connection': 'keep-alive', 'X-Requested-With': 'XMLHttpRequest', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' }class BaiduIndex(): """ 百度搜索指数 :keywords: list or string ',' :start_date: string '2018-10-02' :end_date: string '2018-10-02' :area: int, search by cls.province_code/cls.city_code """ def __init__(self, keywords, start_date, end_date, area=0): self._keywords = keywords if isinstance(keywords, list) else keywords.split(',') self._time_range_list = self.get_time_range_list(start_date, end_date) self._all_kind = ['all', 'pc', 'wise'] self._area = area self.result = {keyword: defaultdict(list) for keyword in self._keywords} self.get_result() def get_result(self): for start_date, end_date in self._time_range_list: encrypt_datas, uniqid = self.get_encrypt_datas(start_date, end_date) key = self.get_key(uniqid) for encrypt_data in encrypt_datas: for kind in self._all_kind: encrypt_data[kind]['data'] = self.decrypt_func(key, encrypt_data[kind]['data']) self.format_data(encrypt_data) def get_encrypt_datas(self, start_date, end_date): request_args = { 'word': ','.join(self._keywords), 'startDate': start_date, 'endDate': end_date, 'area': self._area } url = 'http://index.baidu.com/api/SearchApi/index?' + urlencode(request_args) html = self.http_get(url) datas = json.loads(html) uniqid = datas['data']['uniqid'] encrypt_datas = [] for single_data in datas['data']['userIndexes']: encrypt_datas.append(single_data) return (encrypt_datas, uniqid) def get_key(self, uniqid): url = 'http://index.baidu.com/Interface/api/ptbk?uniqid=%s' % uniqid html = self.http_get(url) datas = json.loads(html) key = datas['data'] return key def format_data(self, data): keyword = str(data['word']) time_len = len(data['all']['data']) start_date = data['all']['startDate'] cur_date = datetime.datetime.strptime(start_date, '%Y-%m-%d') for i in range(time_len): for kind in self._all_kind: index_datas = data[kind]['data'] index_data = index_datas[i] if len(index_datas) != 1 else index_datas[0] formated_data = { 'date': cur_date.strftime('%Y-%m-%d'), 'index': index_data if index_data else '0' } self.result[keyword][kind].append(formated_data) cur_date += datetime.timedelta(days=1) def __call__(self, keyword, kind='all'): return self.result[keyword][kind] @staticmethod def http_get(url, cookies=COOKIES): headers['Cookie'] = cookies response = requests.get(url, headers=headers) if response.status_code == 200: return response.text else: return None @staticmethod def get_time_range_list(startdate, enddate): """ max 6 months """ date_range_list = [] startdate = datetime.datetime.strptime(startdate, '%Y-%m-%d') enddate = datetime.datetime.strptime(enddate, '%Y-%m-%d') while 1: tempdate = startdate + datetime.timedelta(days=300) if tempdate > enddate: all_days = (enddate-startdate).days date_range_list.append((startdate, enddate)) return date_range_list date_range_list.append((startdate, tempdate)) startdate = tempdate + datetime.timedelta(days=1) @staticmethod def decrypt_func(key, data): """ decrypt data """ a = key i = data n = {} s = [] for o in range(len(a)//2): n[a[o]] = a[len(a)//2 + o] for r in range(len(data)): s.append(n[i[r]]) return ''.join(s).split(',')if __name__ == '__main__': # 最多同时请求5个关键词 baidu_index = BaiduIndex(keywords=['华为','大众','香奈儿'], start_date='2018-06-10', end_date='2019-07-04') # 获取全部5个关键词的全部数据 # print(baidu_index.result['华为']['all']) # 获取1个关键词的移动端数据 # print(baidu_index.result['华为']['wise']) # 获取1个关键词的pc端数据 # print(baidu_index.result['以太坊']['pc']) # 写出 data = baidu_index.result['华为']['all'] fn = 'Baidu_index_{}.xlsx'.format('华为(PC+移动)') pd.DataFrame(data).to_excel(fn, index=False, engine='openpyxl') 















 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









