







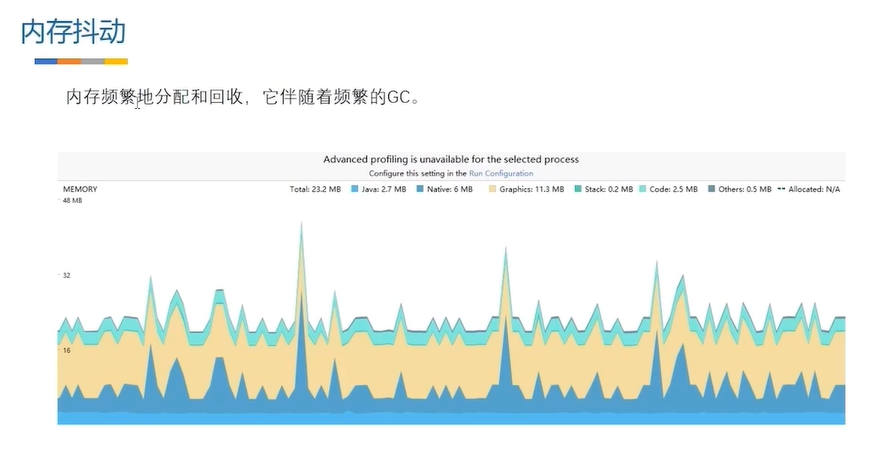
频繁创建对象 gc频繁回收sb
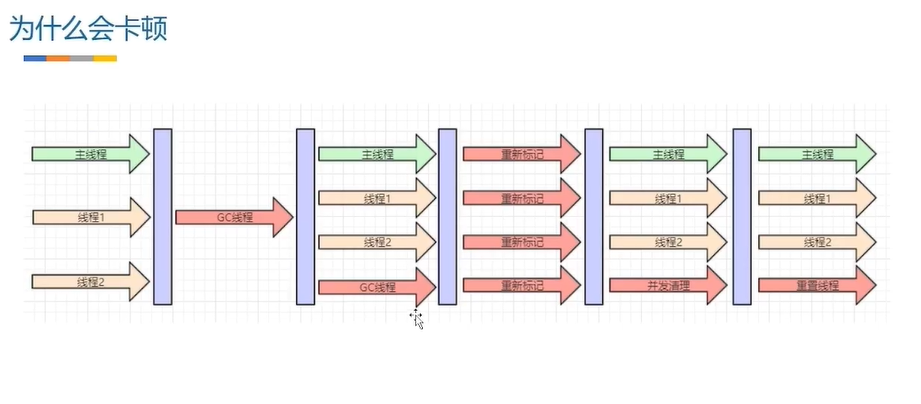



暂停产生垃圾就叫stw
卡死 会oom 内存抖动会导致oom
内存泄漏会出现oom 无法回收 和内存抖动不一样
内存抖动是可以回收的 他并不是无法回收的
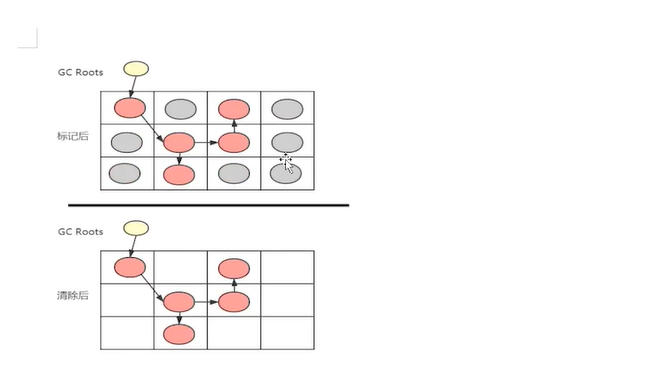
具体的垃圾回收算法 jc具体垃圾回收算法 标记 清除 标记整理 复制
标记清除带来的问题 导致内存碎片
基于java Android呢?版本讨论 8.0以下内存抖动和java一样会oom 8.0以上不会oom
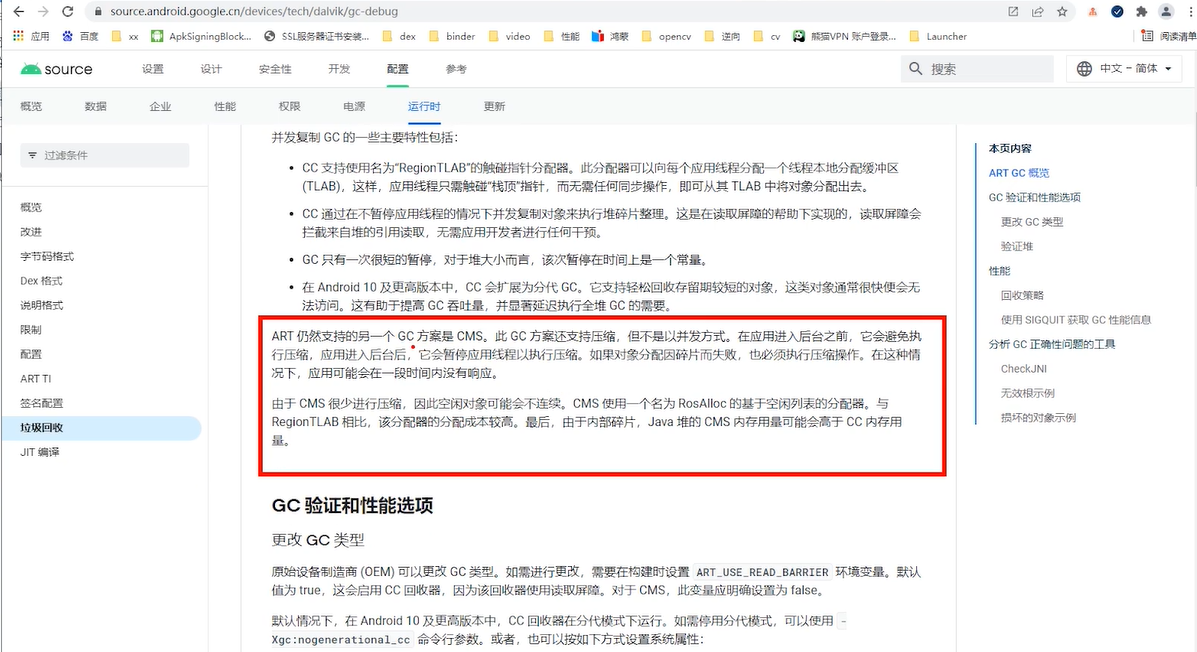
压缩 跟标记整理算法差不多 会整理 会压缩

profile 内存监测工具
不能在ondraw创建对象
内存泄漏点击这个👇快照 java堆
点record 程序对象的申请情况, 7.0 还是8.0 如果你手机版本比较高 就没有record按钮 点击鼠标不动 拖一段时间
allocation call stack 创建对象的堆栈 从下往上看
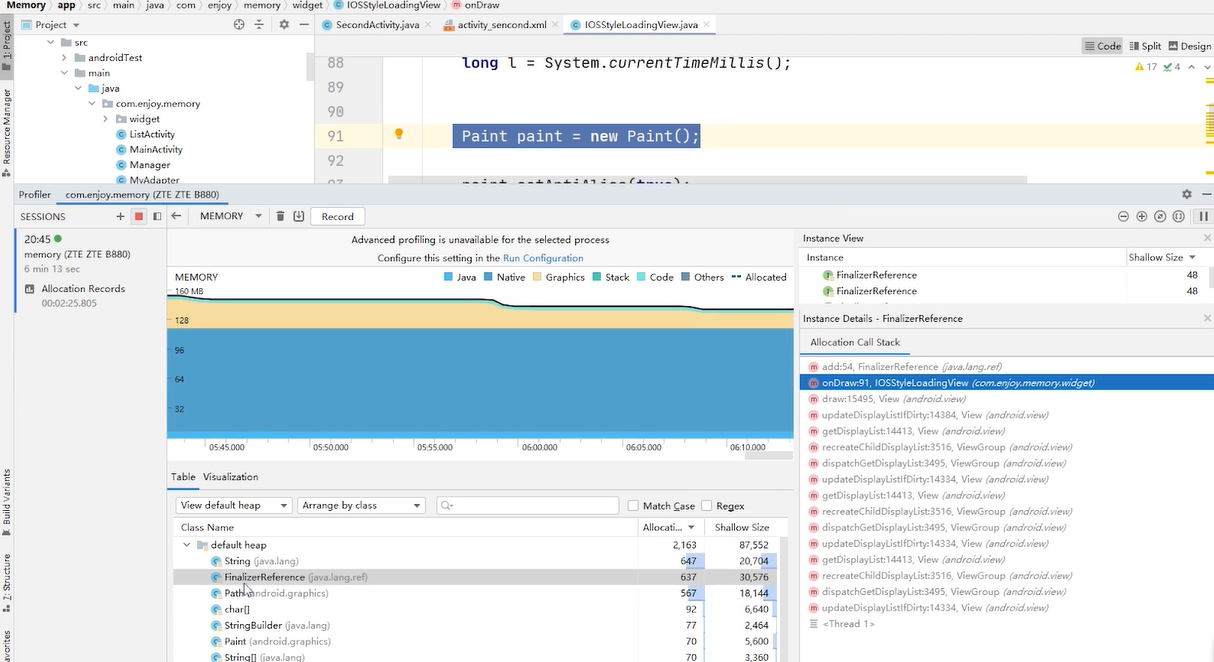
finalizerreference 是由于我们创建paint对象从而创建的 finalizerreference 为了减少 finalizerreference的个数,要减少paint的个数
path paint 创建的对象都会导致finalizerreference 的产生
强软弱虚 都在java.lang.ref包下面
finalizerreference 也是在这个包下,是一个回收引用 特殊引用
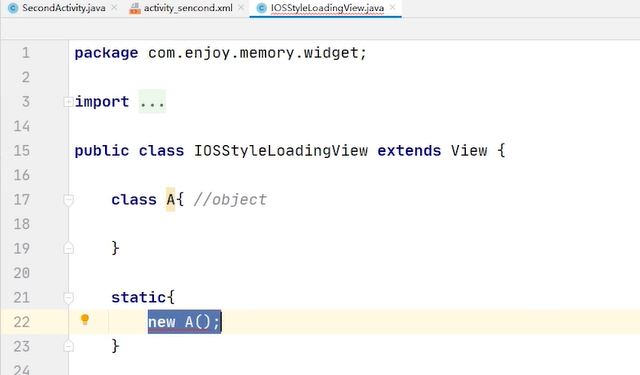
这个A对象不会导致 每new 一个对象 伴随一个 finalizerreference,但是我把A对象改动一下 我去重写父类的finalize 并且写自己的代码 不是空的实现,里面是有代码的 再去new A 虚拟机就会自动创建finalizerefresh
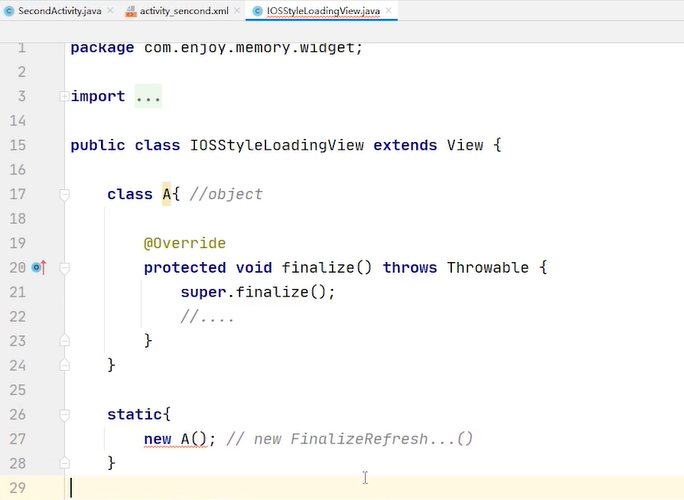
这些对象大多数都是在ondraw里面创建出来的,所以我们就检查 能不能减少对象的创建
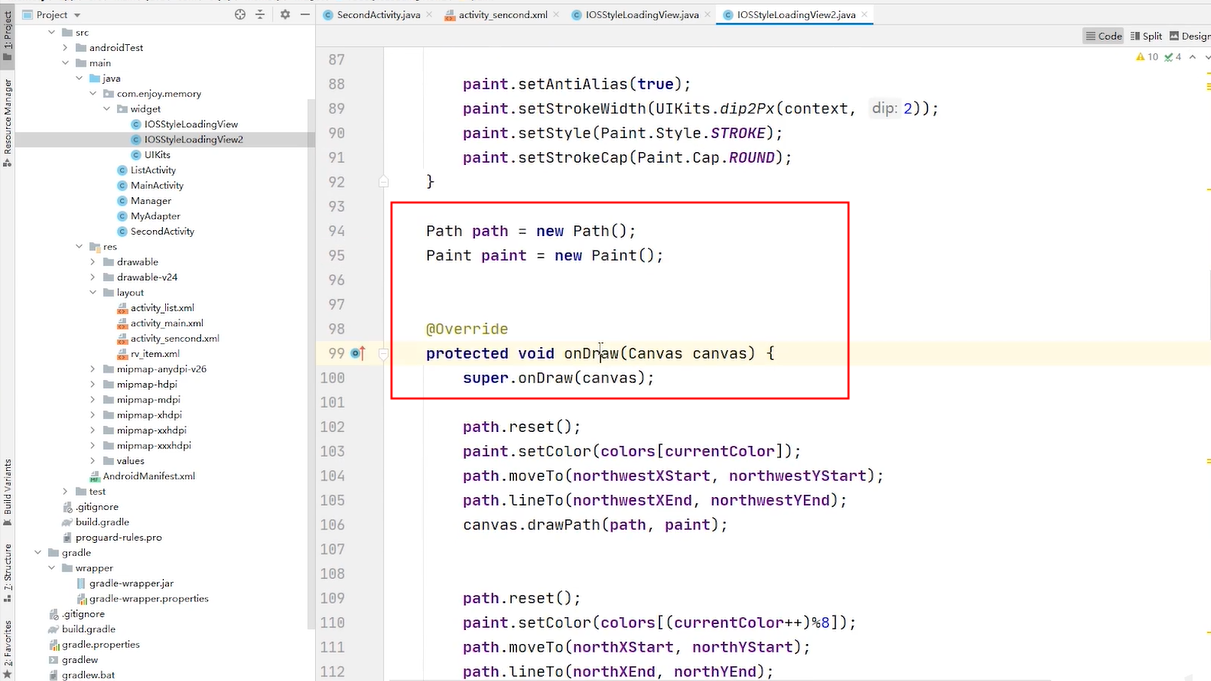
ondraw可能会一个很频繁调用的方法 会很频繁的创建对象,会出现内存抖动问题


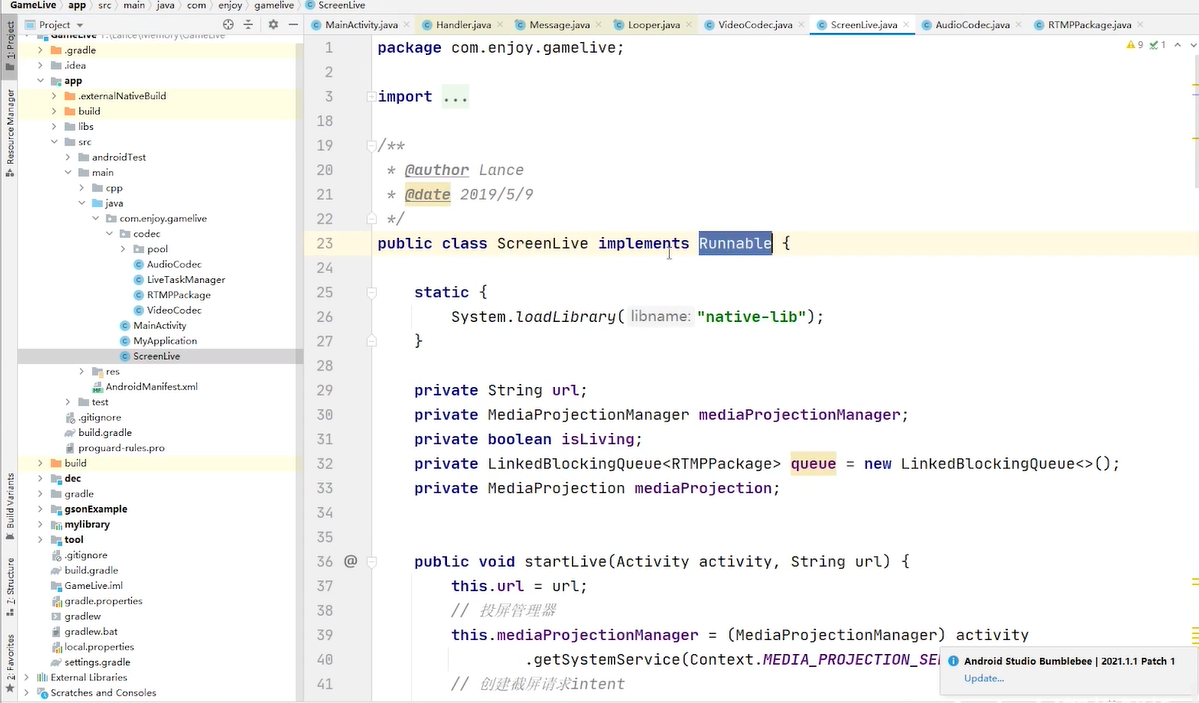
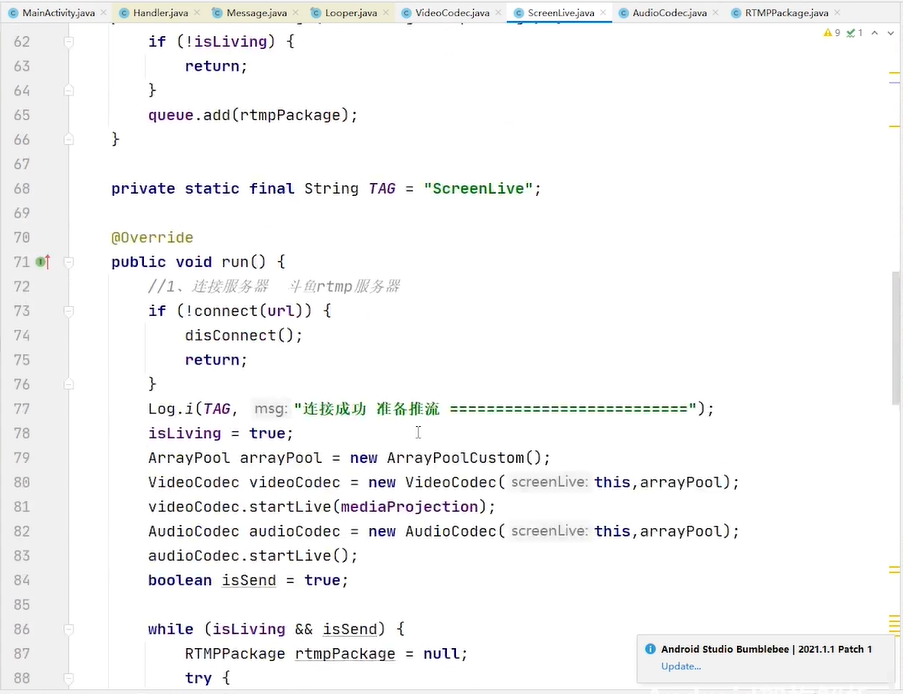
手机流推到斗鱼

生产者线程

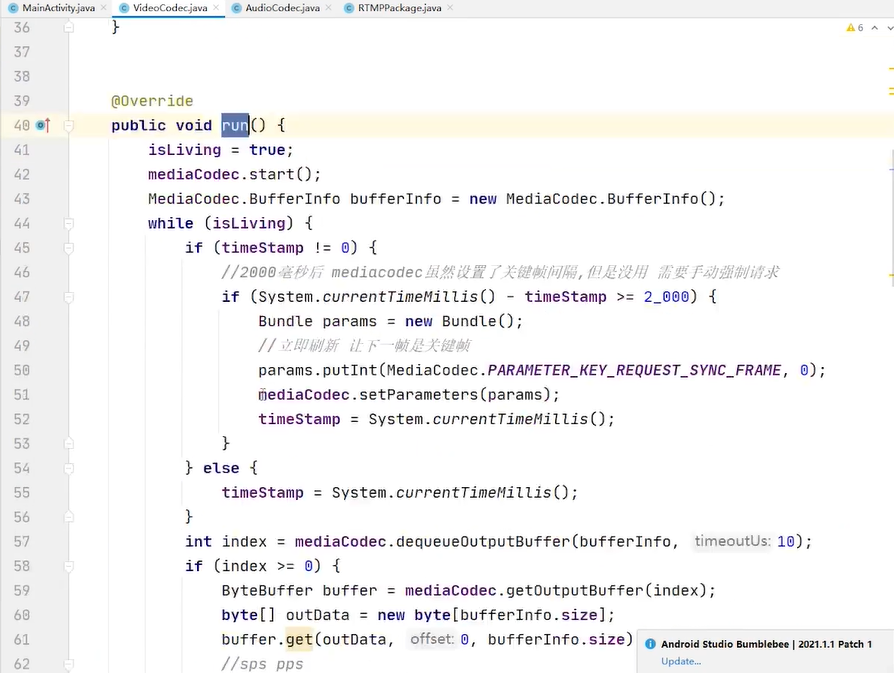
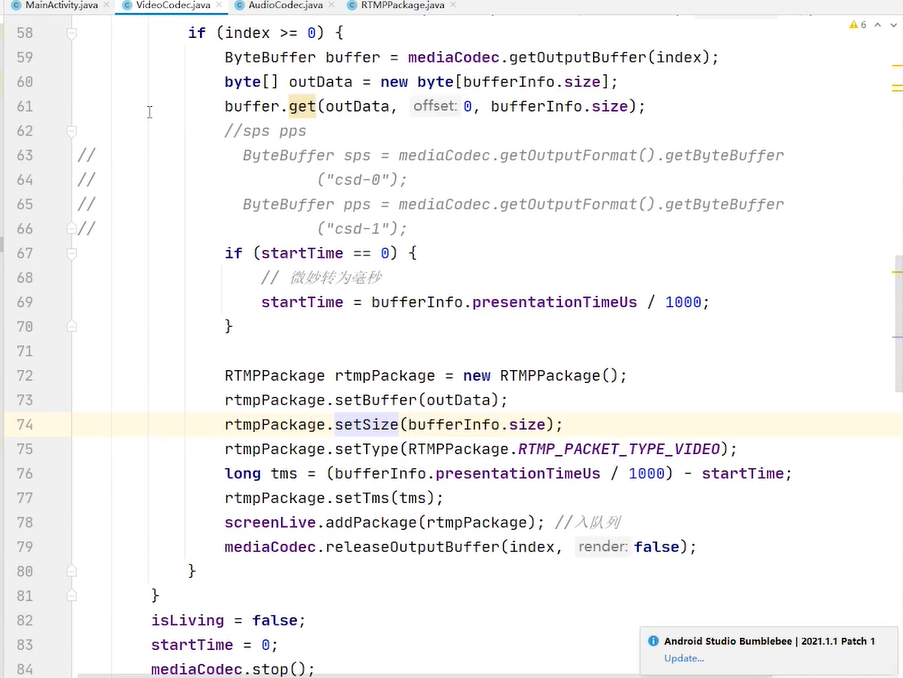
不断的在new 对象
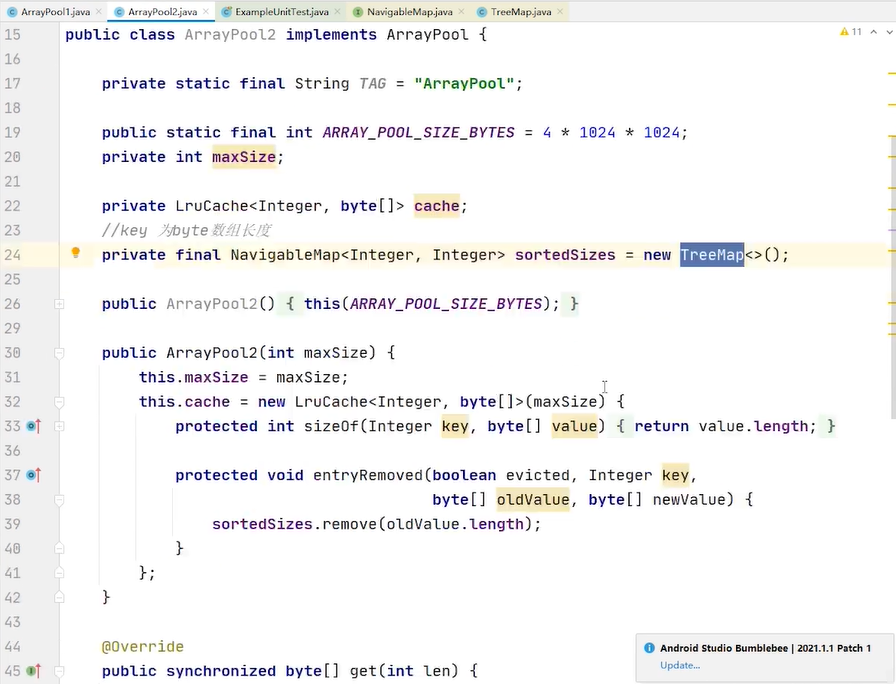
数据不是时时处理 是队列
处理的是同一个对象
用对象池

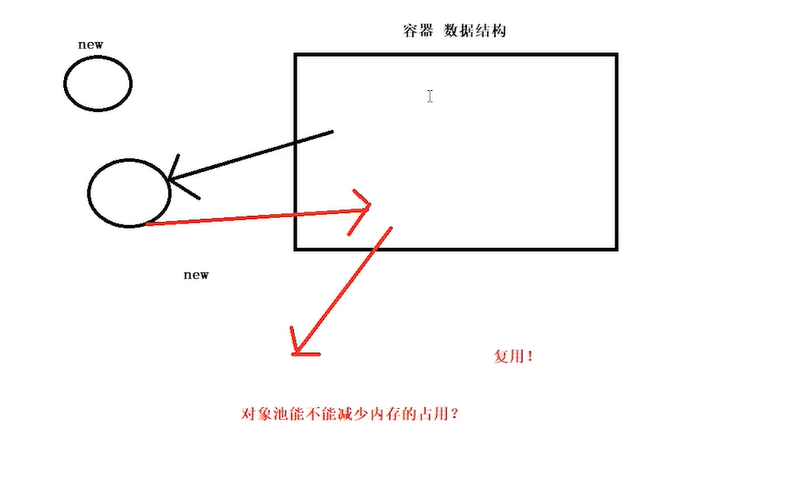
哪些用对象池 handlermsg glide okhttp
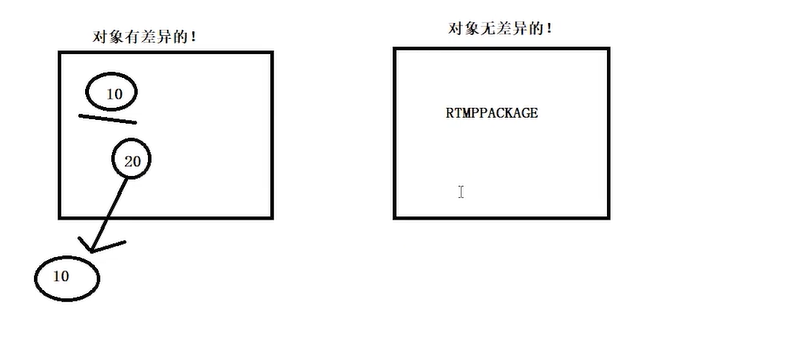
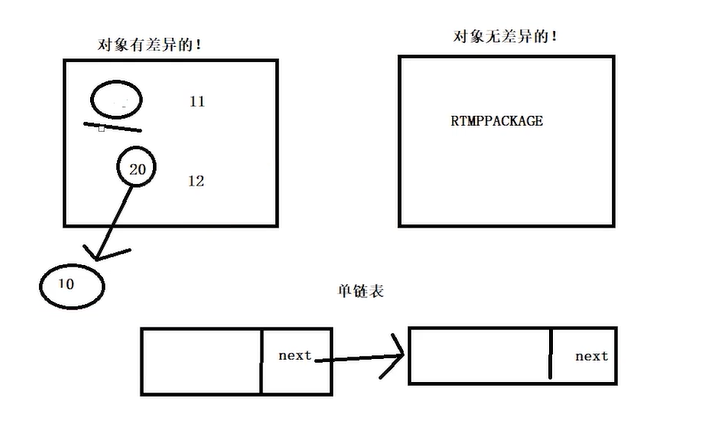
glide 是对bitmap复用 数组服用
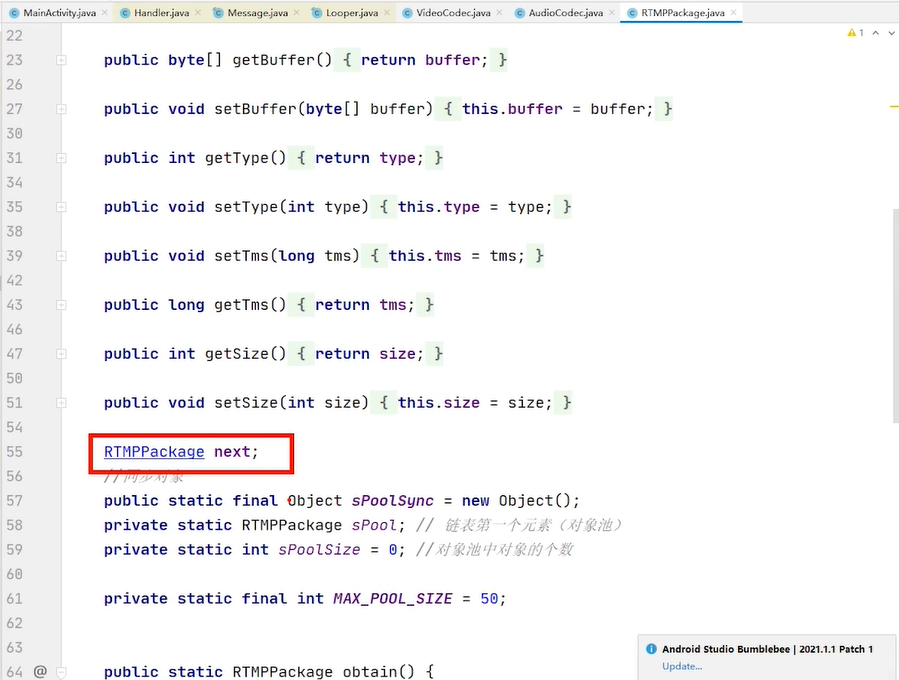
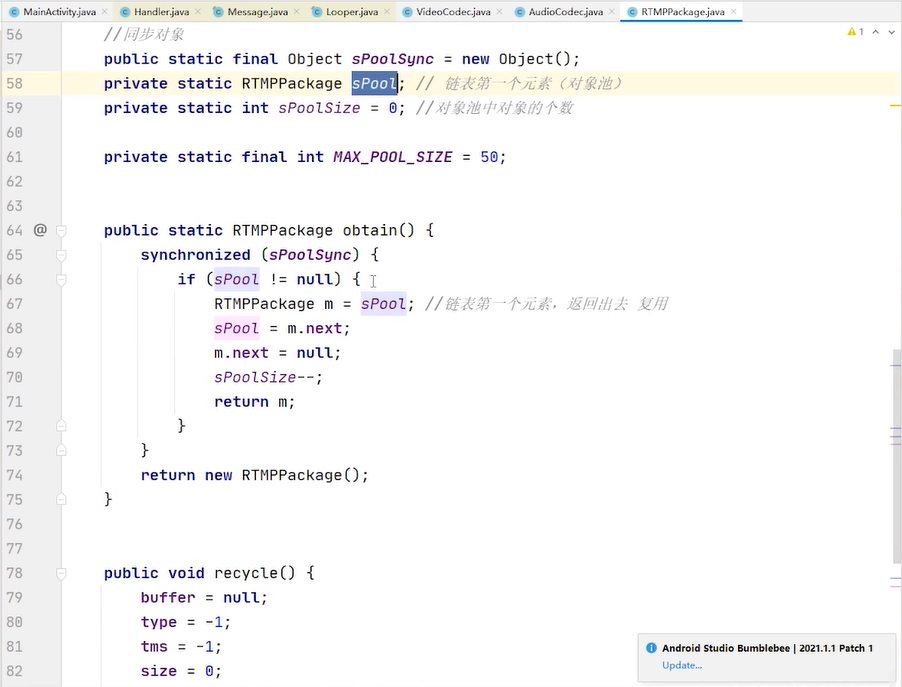
handlermsg 是对message的复用 不用关心拿的是哪个msg msg是一个单链表

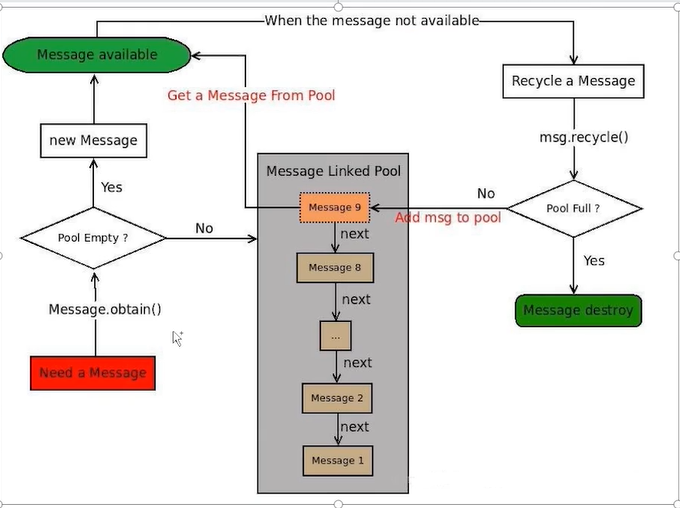
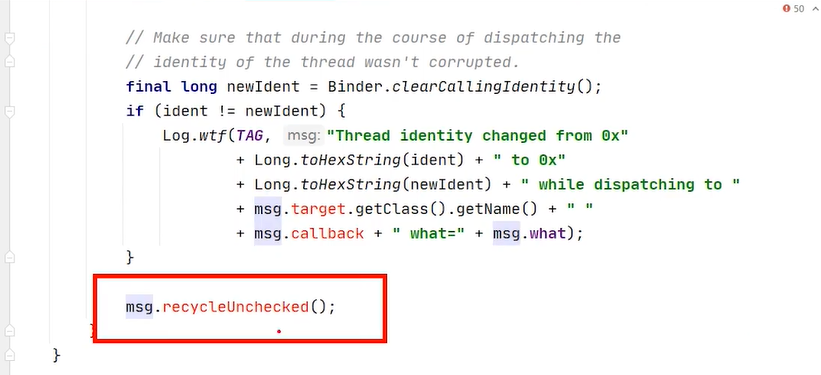
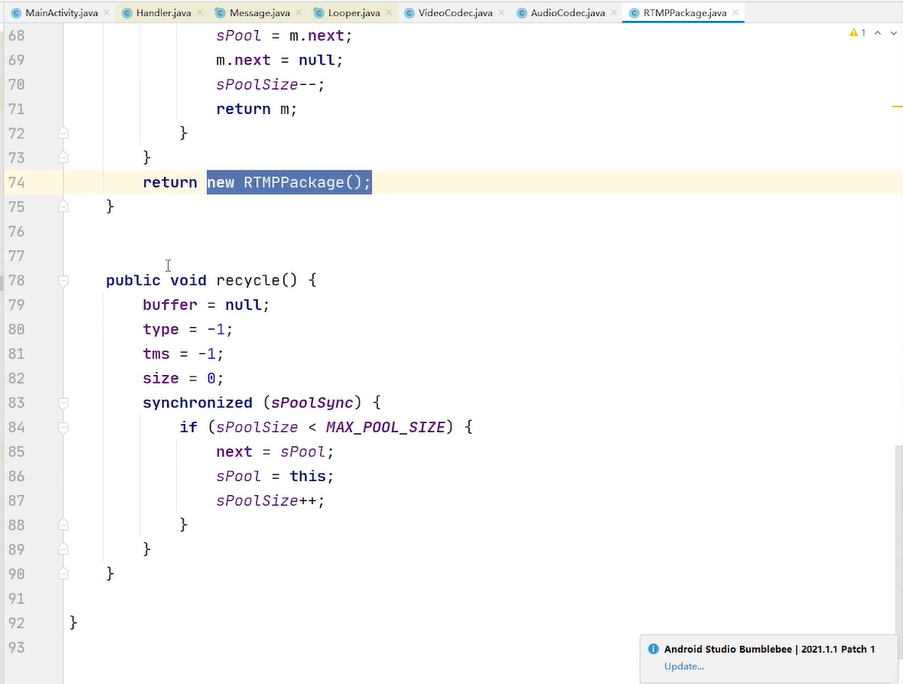
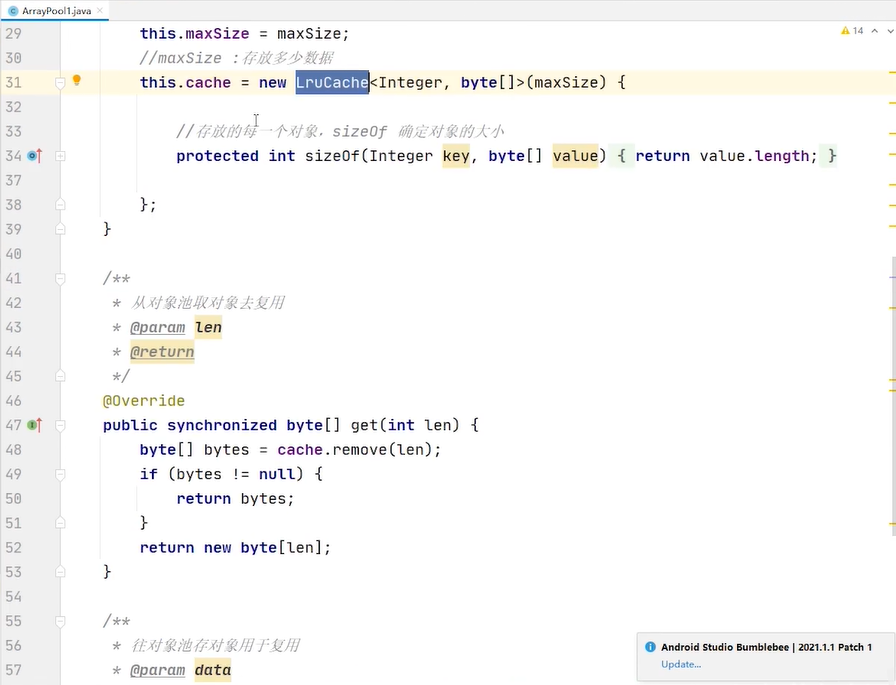
有就从对象池拿,没有的话就new 一个 msg 在looper里面进行的分发 looper 的loop方法去处理这个msg 处理完之后 执行msg的recycleunchecked方法 把msg还回到对象池当中去
改造

生产者线程👆
消费者线程👇
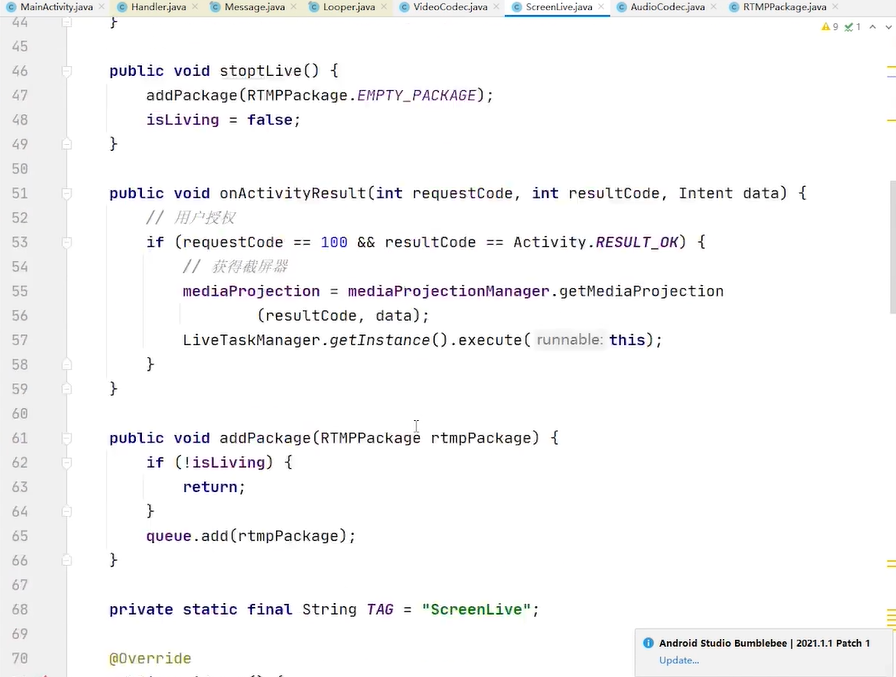
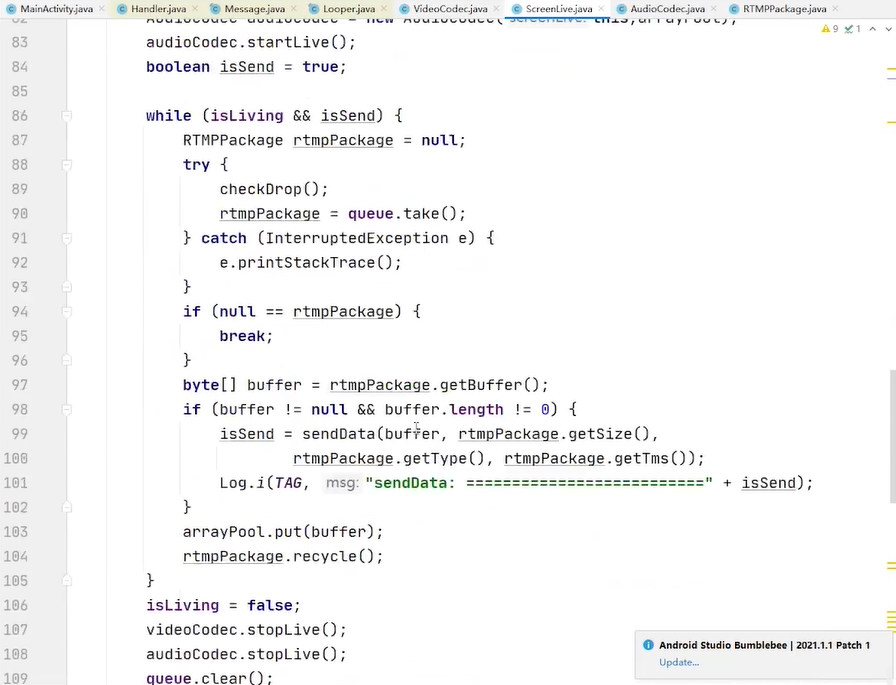
调一下rtmppackage.recycle(); 把对象还回到对象池里面
越接近10越好

8.优化实战二,基于LRU算法的对象池_哔哩哔哩_bilibili
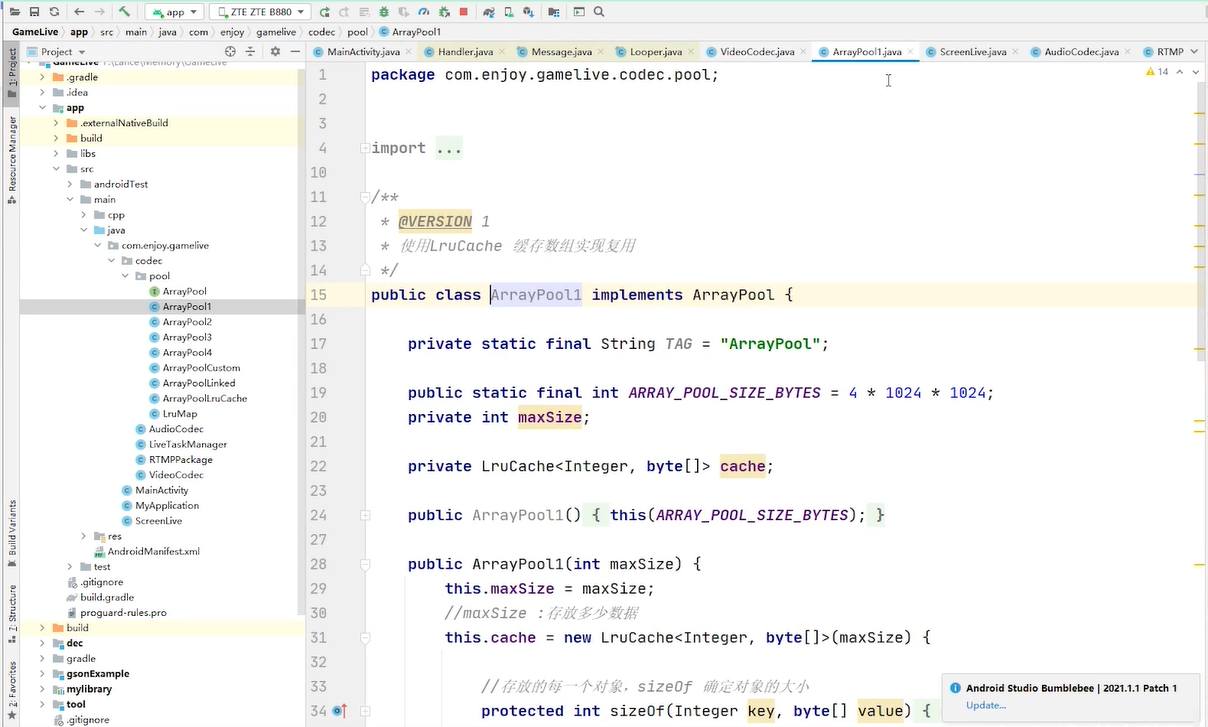
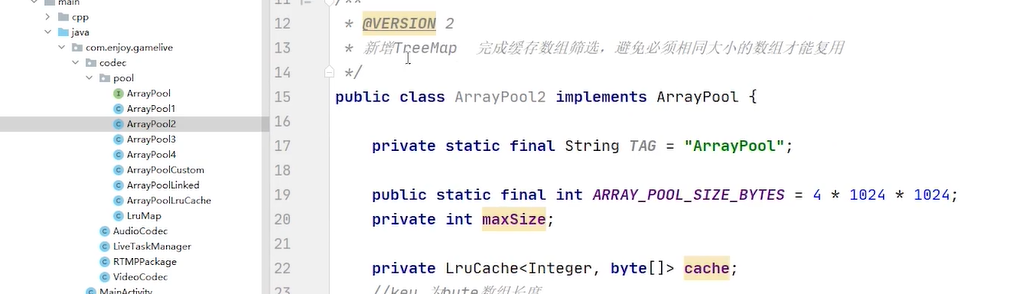
映射集合 需要10 给10 ,map无限扩展 限制
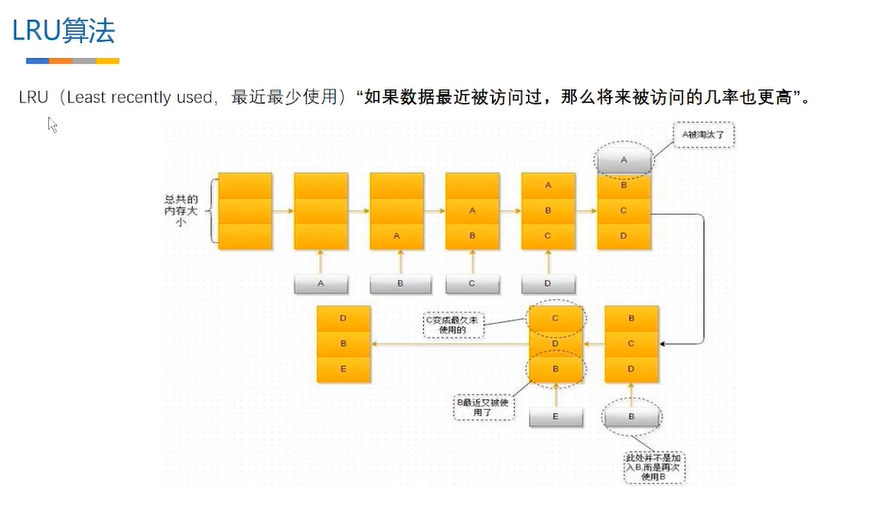
本质在于排序 最近使用的排在最前面 或者排在最后面
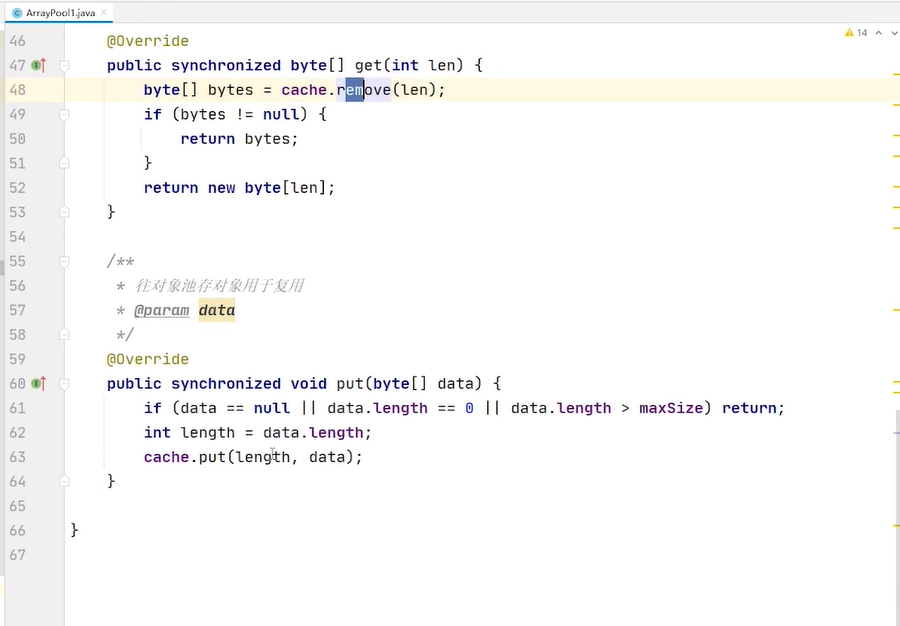
lrucache完全基于linkedhashmap实现的 accessorder =true 表示要排序
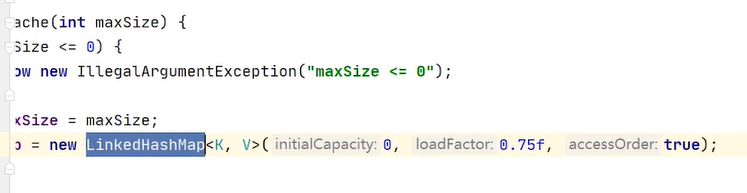
linkedhashmap基于hashmap实现
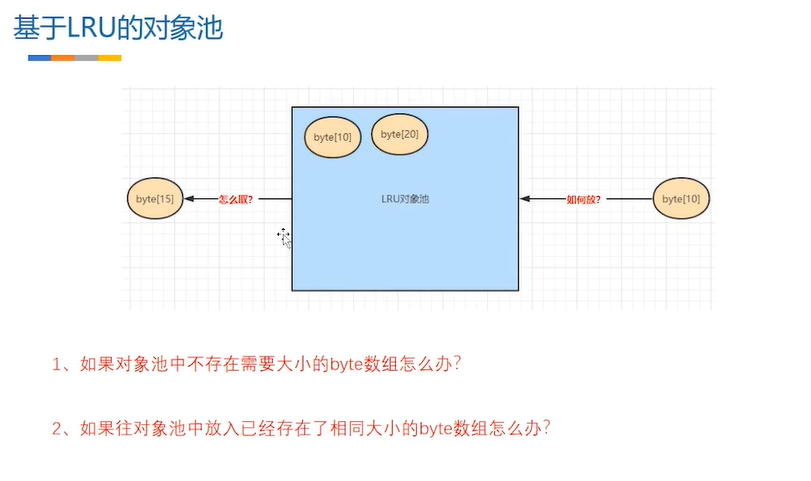
没有15的时候你给我一个最合适的byte数组复用
现在是一个key对应一个value 那有没有可能 一个10对应多个byte数组 如果我经常性的需要10 那最好做成一对多 ,而不是一对一

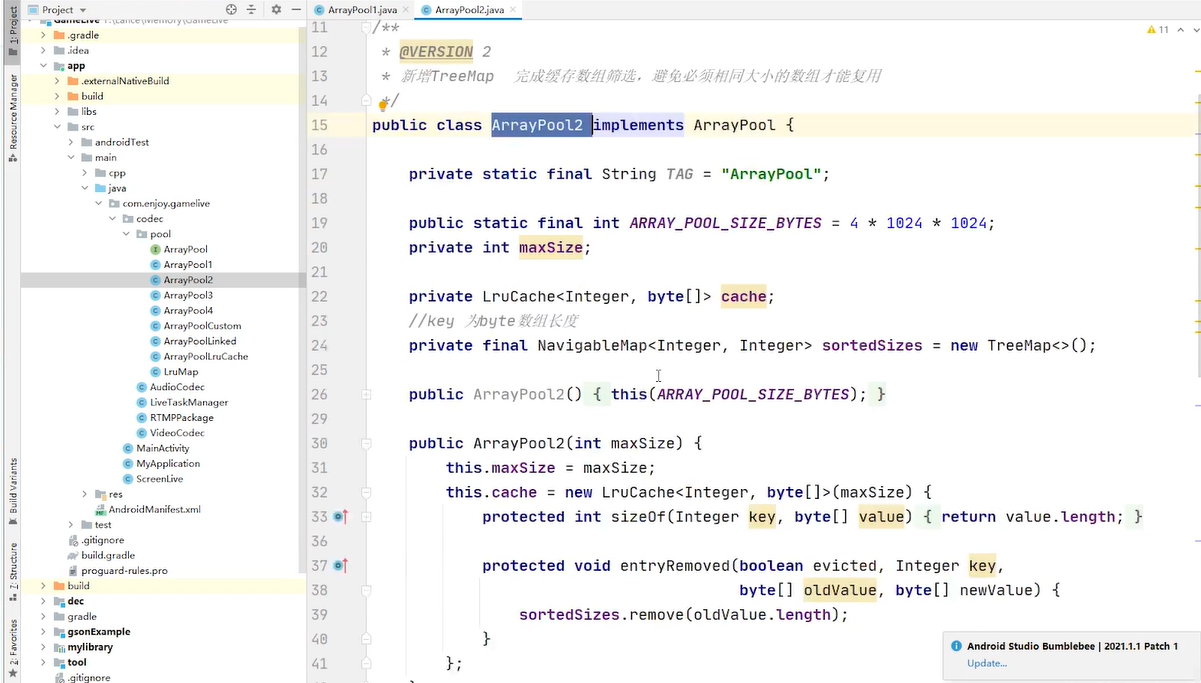
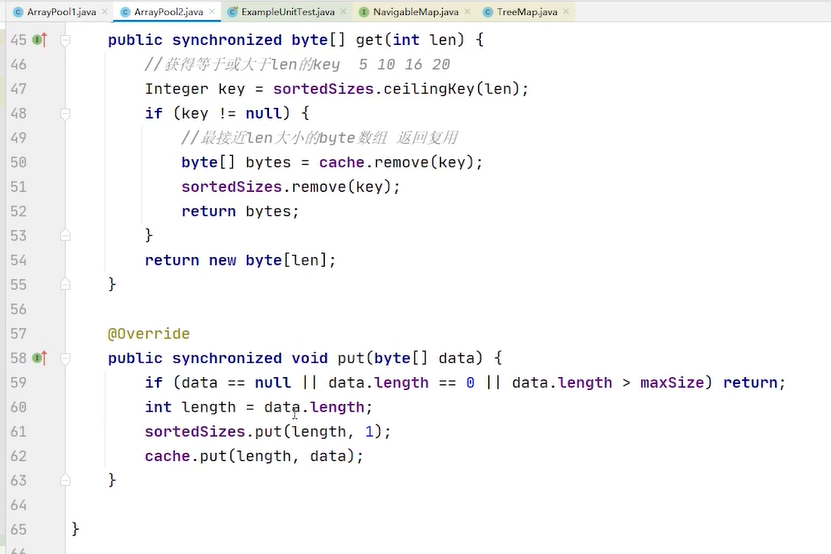

只要能够完成对key的增长排序 我就能够轻松找到我需要的key
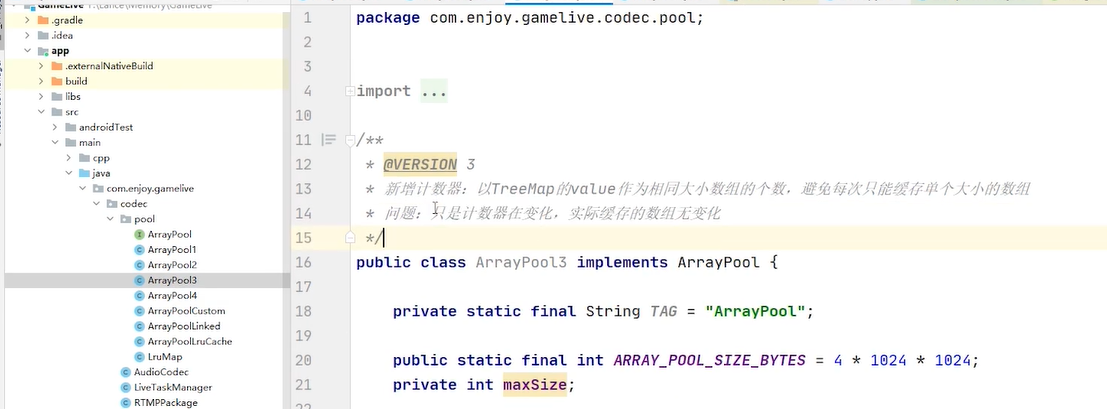
jdk提供了很多的数据结构 容器 有没有一款容器 能够帮助我们轻松的做到这个功能?有 treemap
会返回最接近14 大于14的key给我们 返回15给我们
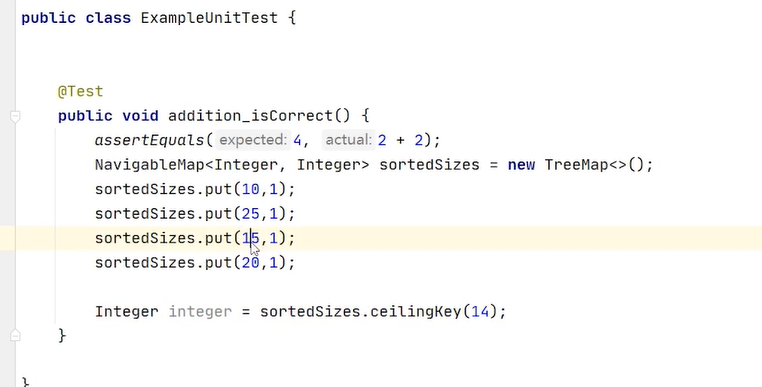
实际上就是排序
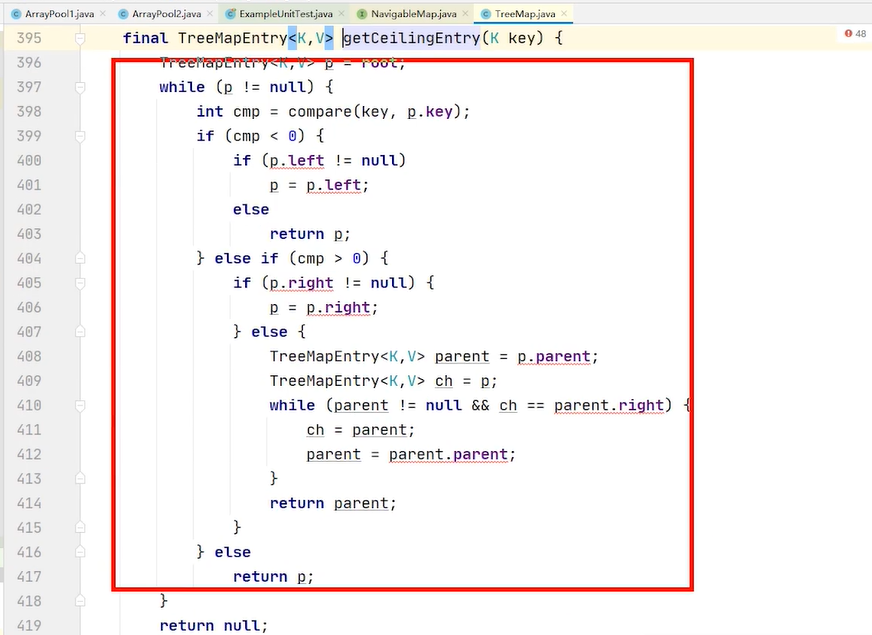
treemap完全跟cache联动的 cache有什么key treemap也有什么key 完成这两个容器联动之后 我在get的时候 我就可以先来从我的treemap中找到你需要的大小最接近的key 47行,key在 treemap存在,自然在 cache也存在 通过key返回对应的vlue 返回给你用
treemap 解决如何取 的问题
如何放?一对多 怎么放?
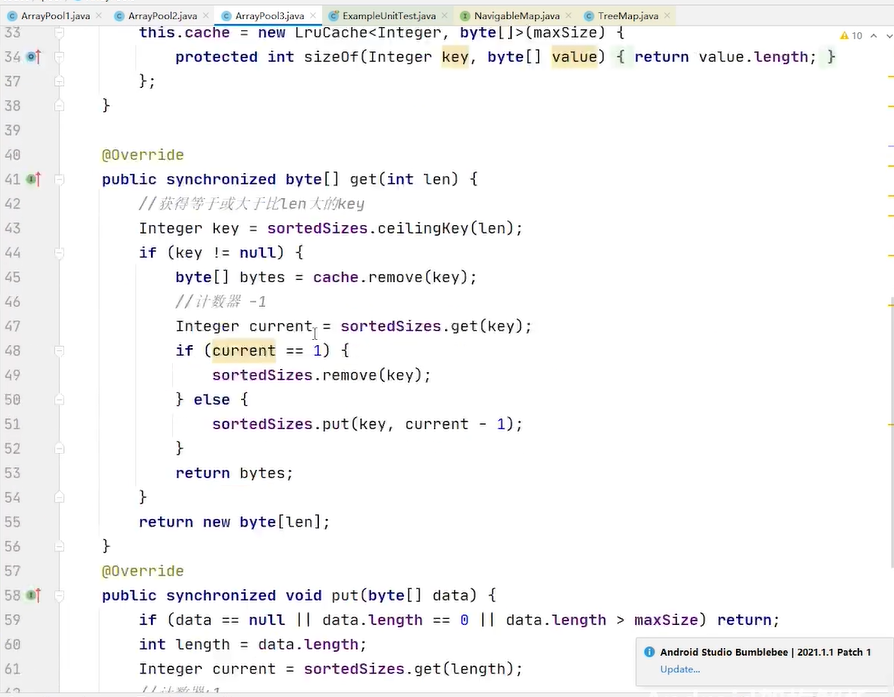
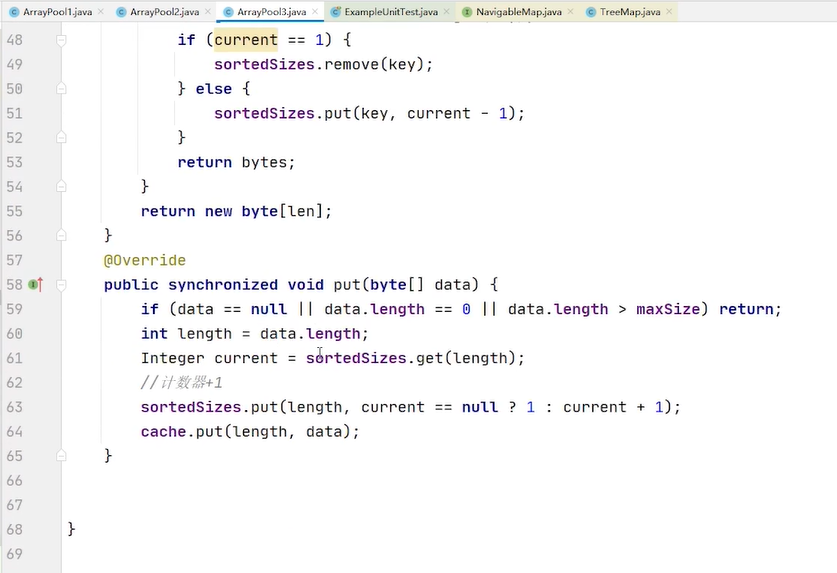
treemap每次put数据,我们key是长度 vlue 固定给了1 我们完全可以把treemap的vlue做成个数 把treemap的vlue做成计数器 每次put 我在treemap当中去找,有没有存过这么长的byte数组 如果有我就拿到 treemap的vlue 假设是1 那就表示我当前存了1个这样的byte数组,我现在又来存一个 我就要加1 只是计数器做了加一减一的变化 在cache里面的数据仍然是一对一的
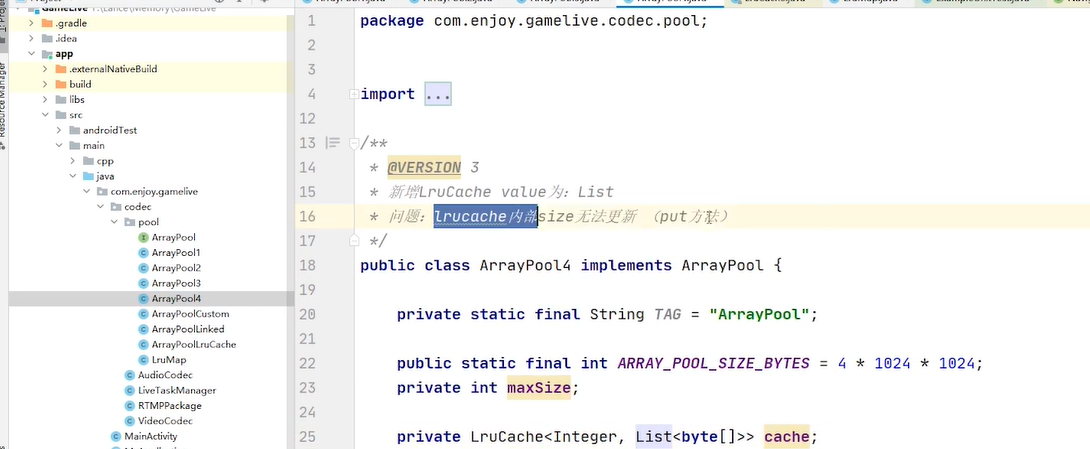
所以在arraypool4里面就把我们的vlue 改成了list集合能够表达一对多的关系

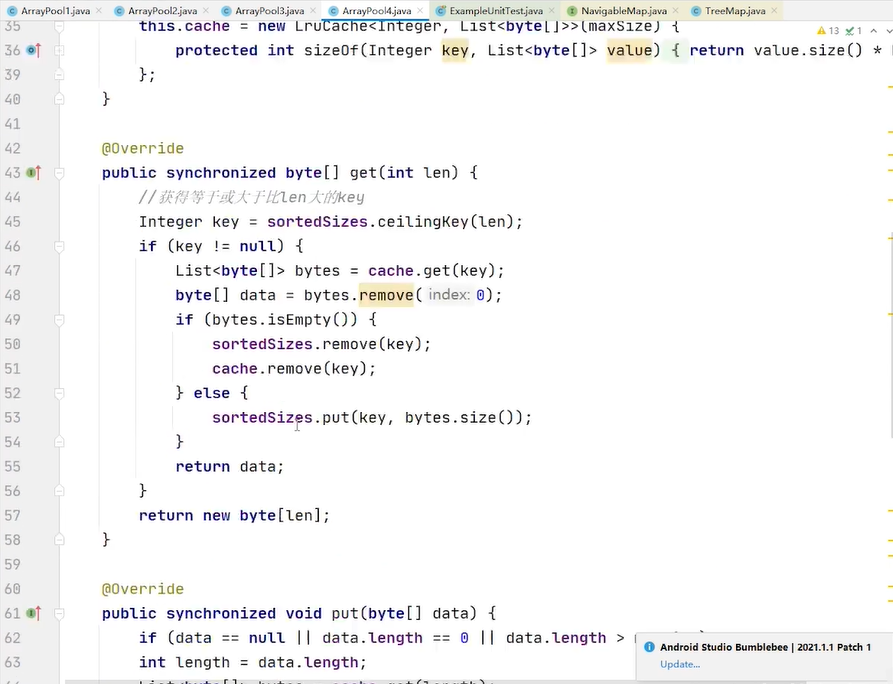

还会发生问题, 就是你的这个lru算法出现了问题 因为lru的实现不支持你把vlue改成list集合,为什么不支持 需要阅读lru的源码 需要自己实现 一对多关系的lur容器
所以glide源码会有一个arraypool的接口,lruarraypool就实现了这个接口,lruarraypool里面没有lru 也没有用到jdk的linkhasmap来实现lur算法
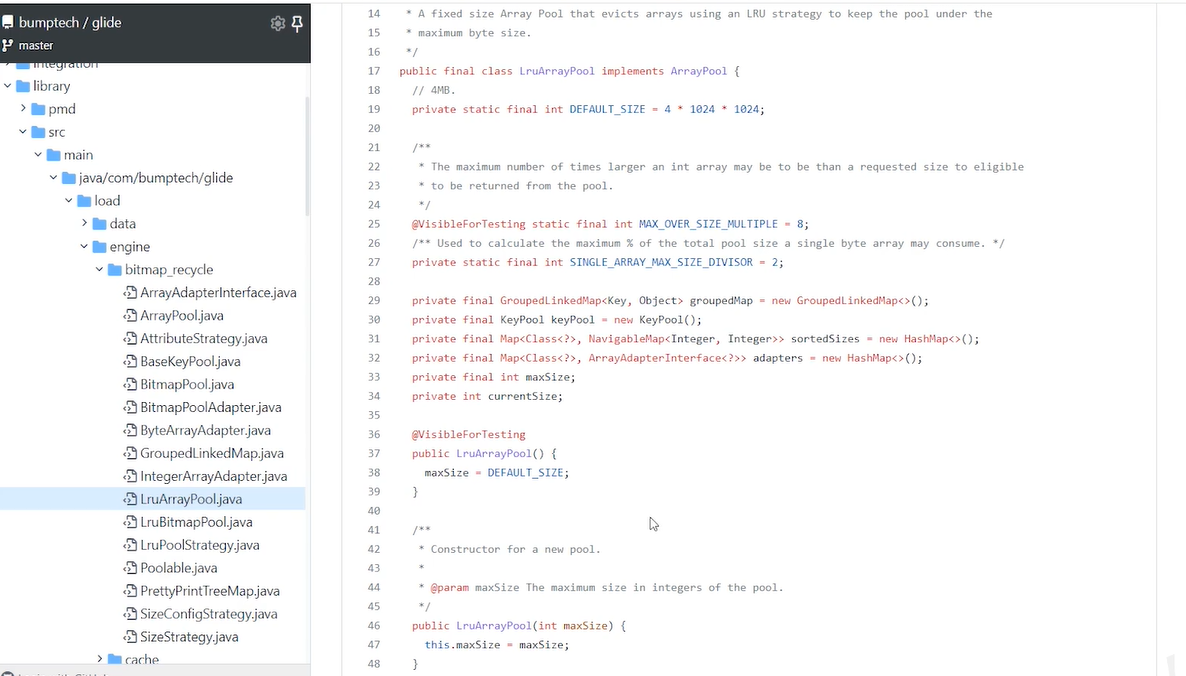
为什么? 自己实现grouplinkedmap自己实现了lru算法 目的就是实现一对多关系的lru容器

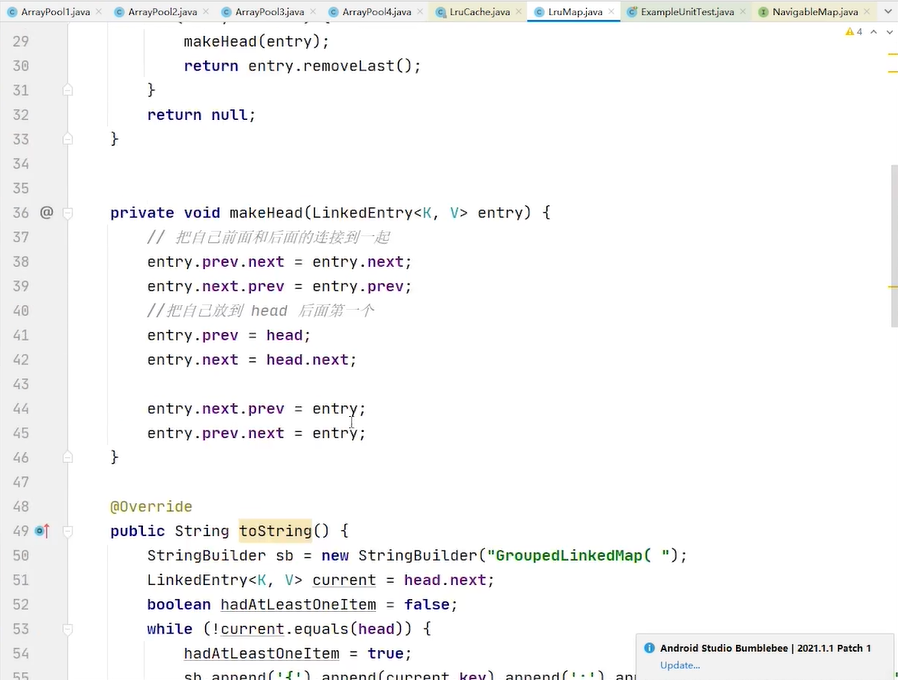
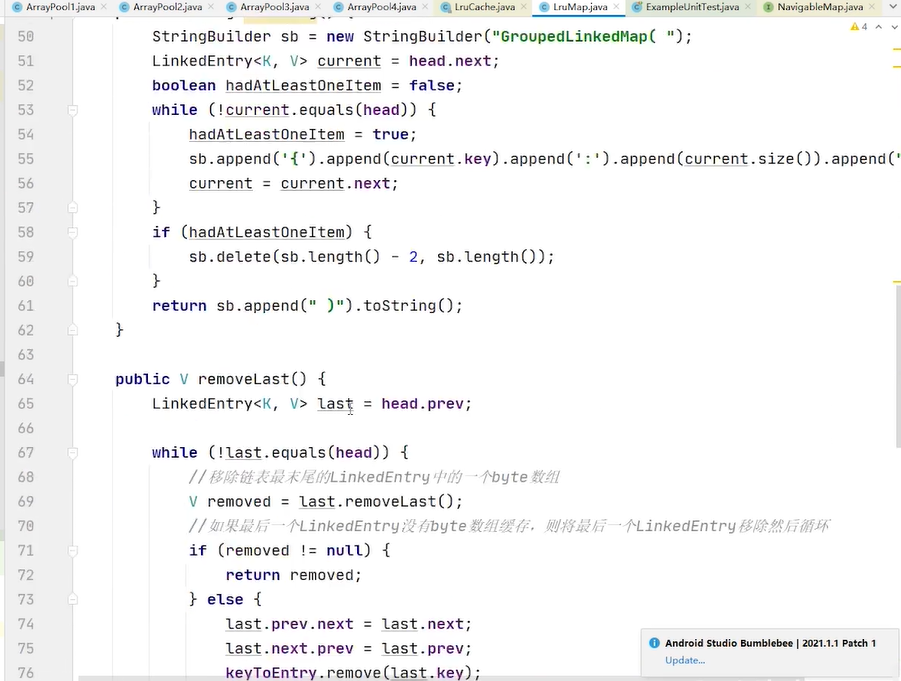

双链表,跟淘汰lru算法有关系, 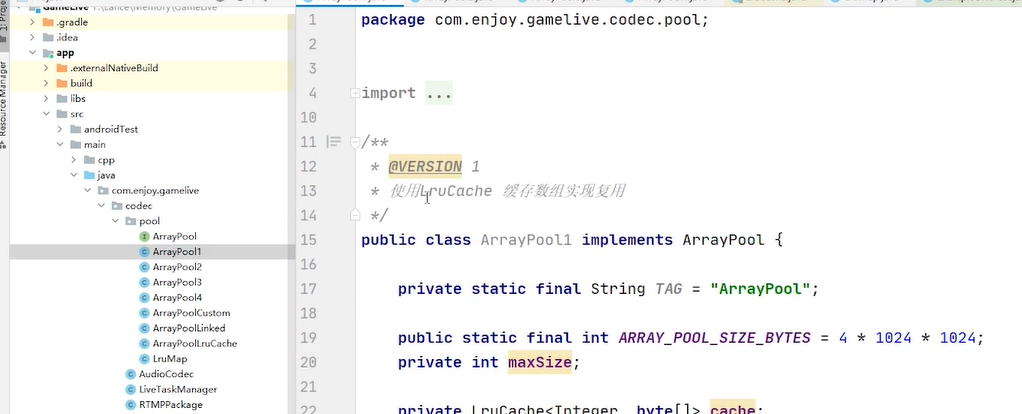
用自己封装的lrumap来完成自己封装的arraypoollrucache
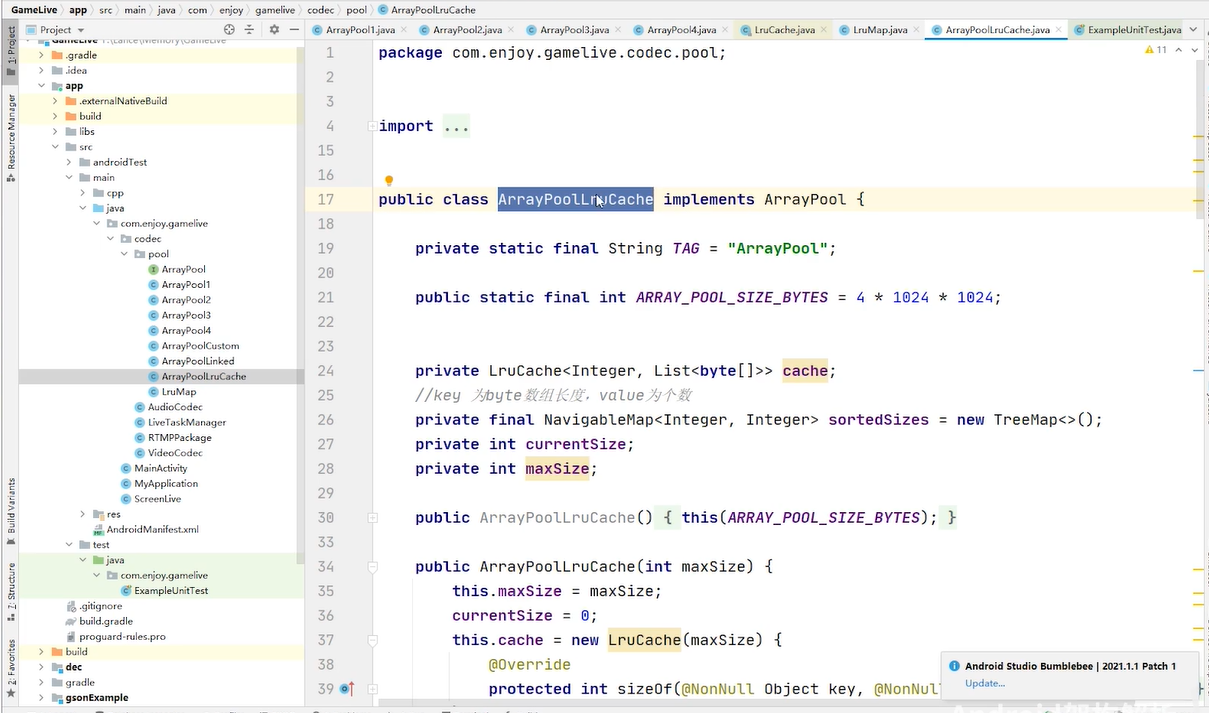
用它来作为我们byte数组的服用池 减少我们new的操作 避免内存抖动
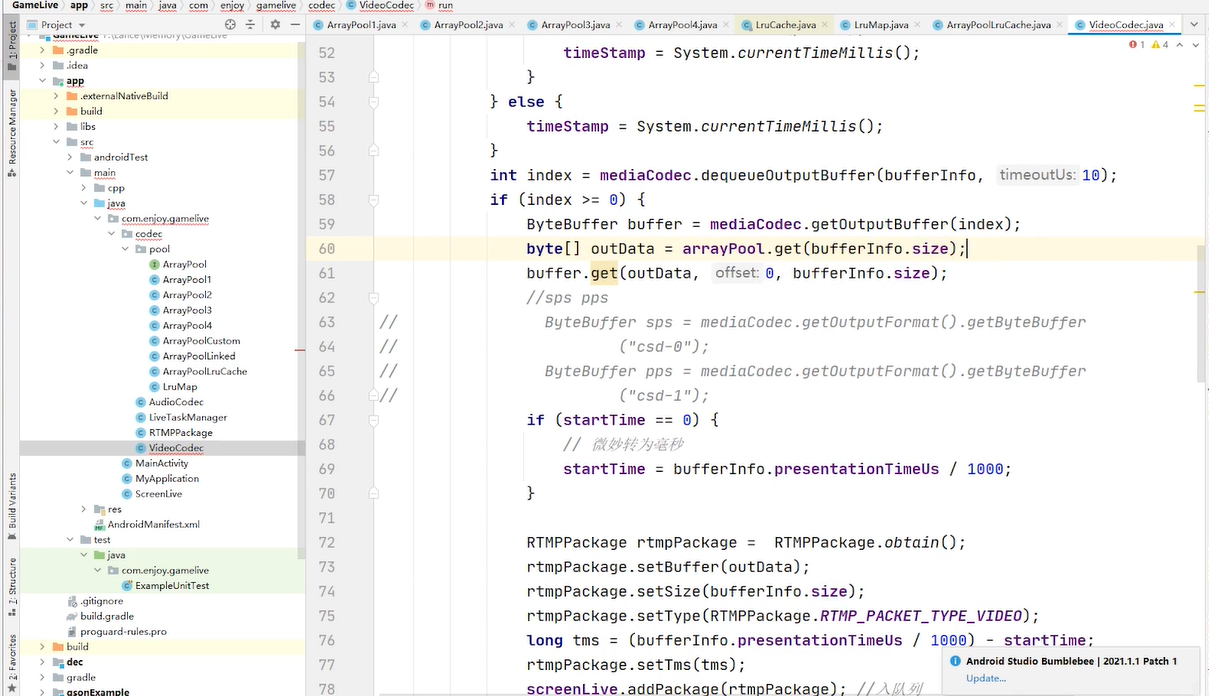
对应不同场景解决对象池设计的问题
卡顿 是否存在内存抖动的问题? cpu占用率 内存情况

多次长期的执行,
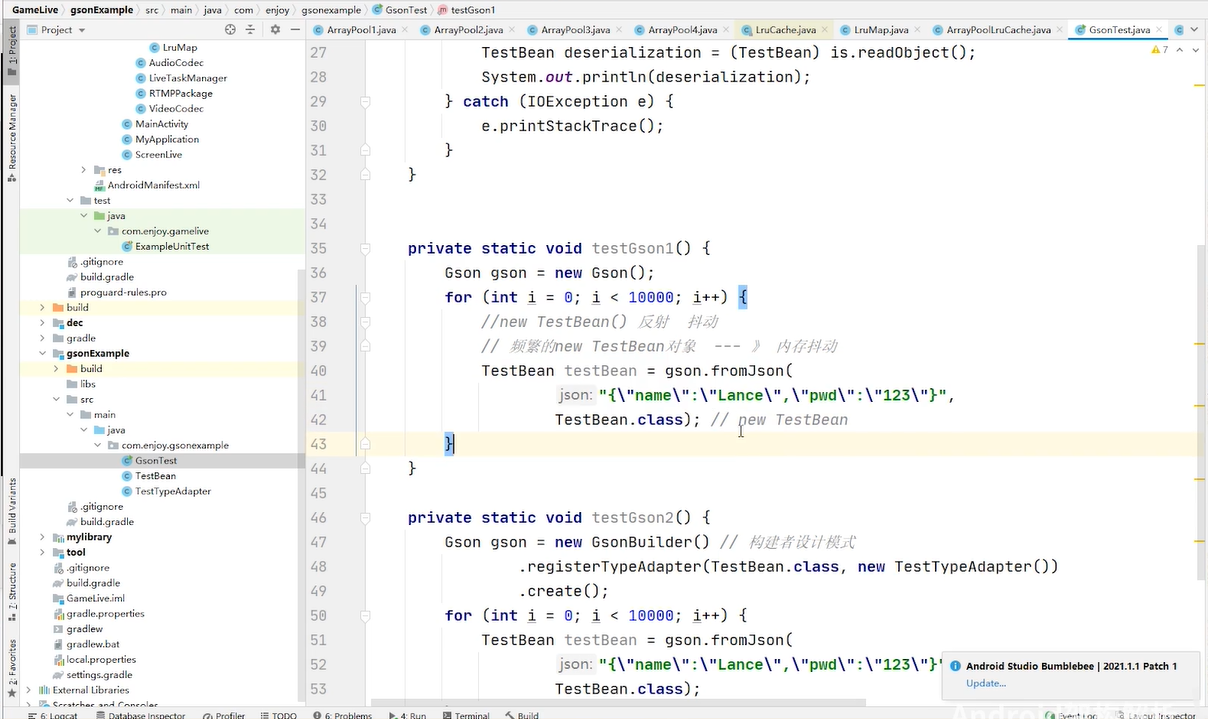
每次调用这段代码至少会产生一个testbean对象现在要做的就是减少testbean的创建 也要用到对象池 怎么把gson与对象池结合起来 怎么把gson把创建对象的权限交给我们让他别new 而是我们自己把testbean的对象构建出来,gson有个构件者模式支持你往gson当中支持adapter 类型适配器 new

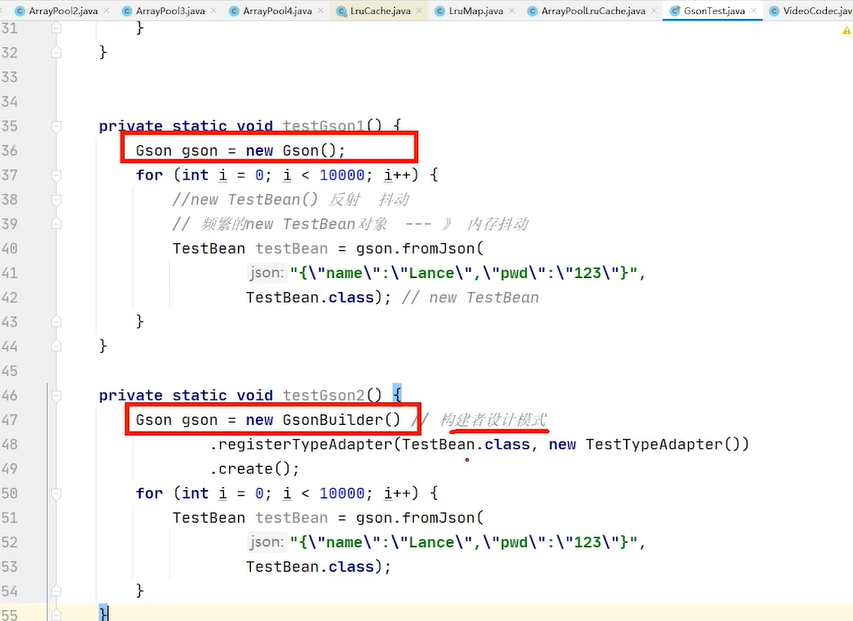
new gosn的时候,我们不直接去new ,我们是通过构建者的设计模式来new
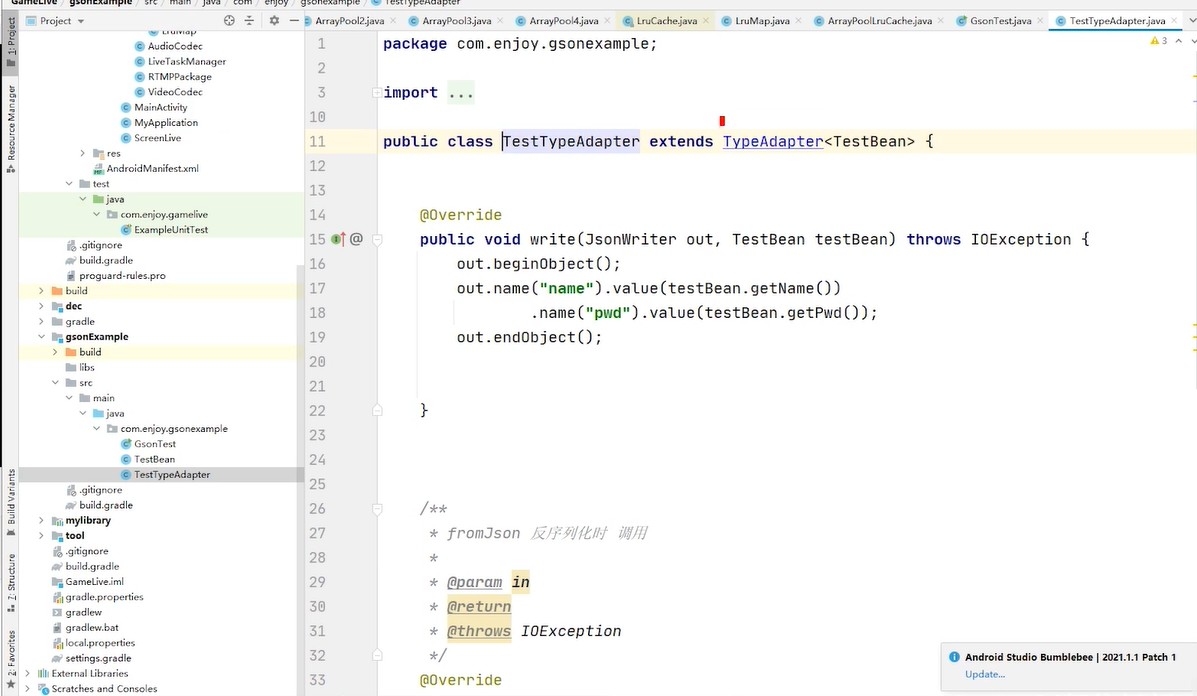
 write 是序列化
write 是序列化
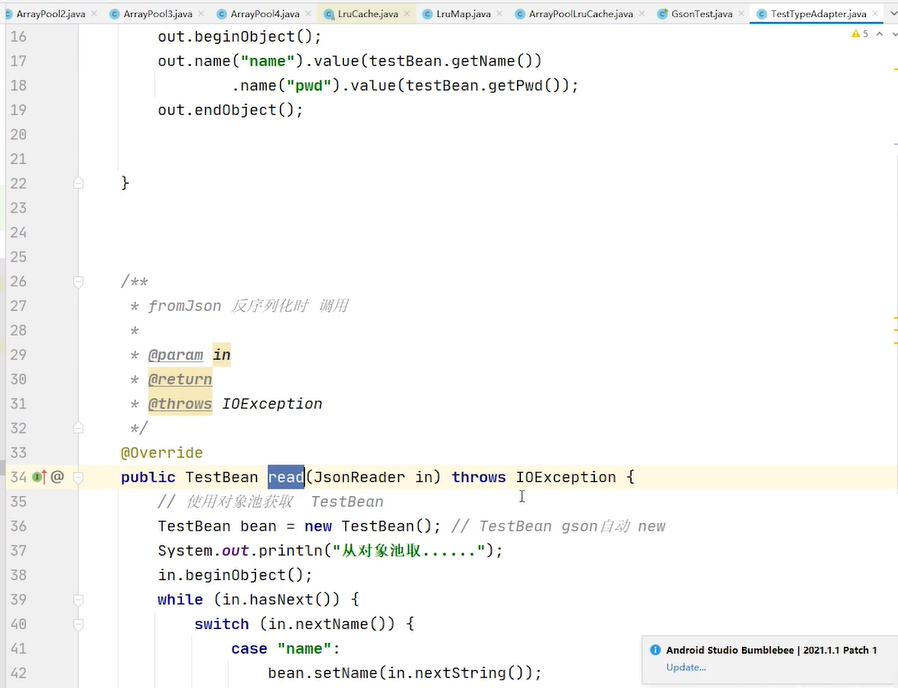
read是反序列化
把json转成对象是反序列化,把json反序列化成javabean

adapter的作用是当gson 反序列化javaben是testbean的时候,他会把反序列化的过程交给你的typeadapter 也就是说你是从这个gson fromjson的时候把数据交给你的 typeadapter的read方法 由你去反序列化,由你自己去处理这个过程 ,你自己处理这个过程你就去返回一个testbean 所以这时候你就把这个testbean的创建 由gson内部拿到自己手上, 这个时候可以不用new 而是从对象池里面去拿,















 1367
1367











 被折叠的 条评论
为什么被折叠?
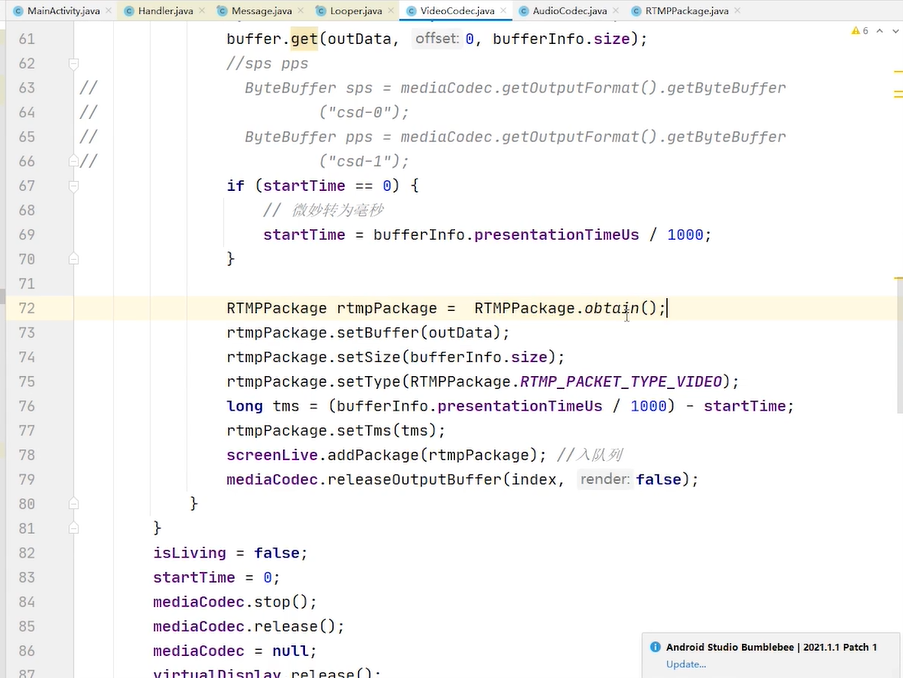
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









