







爬取福大教务通知
效果展示


实现细节
0x01 获取总页数
观察页面url,发现规律
第一页 https://jwch.fzu.edu.cn/jxtz.htm
第二页 https://jwch.fzu.edu.cn/jxtz/163.htm
第三页 https://jwch.fzu.edu.cn/jxtz/162.htm
最后一页 https://jwch.fzu.edu.cn/jxtz/1.htm

def get_page_num(url):
"""获取总页数"""
html = requests.get(url) # 获取页面html
html.encoding = 'utf-8'
all_page_num = re.search(r'<a href="jxtz/1.htm">(\d{3})</a>', html.text, re.S).group(1)
print("总页数为:", all_page_num)
return all_page_num
0x02 获取每篇文章的基本信息
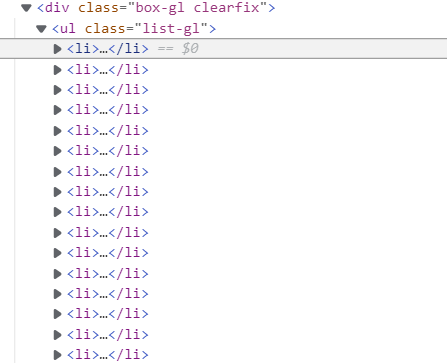

查看源代码发现
- 所有文章信息均存放在
class=“box-gl clearfix”的<div>标签 的<ul><li>列表中 - 时间信息存放在
<span>标签中 - 通知人信息为
<li>标签文本内容,由【】包括 - 详情链接为
<a>标签的href - 文章标题为
<a>标签的文本内容
info_time = re.search(r'(\d\d\d\d-\d\d-\d\d)', str(li.span)).group(1)
info_author = re.search(r'【(.*?)】', str(li)).group(1)
info_title = li.a.string
# 文章链接有多种格式
if li.a['href'][0] == '.':
info_link = "https://jwch.fzu.edu.cn" + li.a['href'][2:]
elif li.a['href'][0] == 'i':
info_link = "https://jwch.fzu.edu.cn" + li.a['href']
else:
info_link = li.a['href']
0x03 获取附件信息

def get_file(article_url):
"""获取附件名称和附件下载次数"""
file_list = []
try:
html = requests.get(article_url)
html.encoding = 'utf-8'
if re.search(r'附件【', html.text): # 判断是否存在附件
soup = BeautifulSoup(html.text, 'html.parser').find(name='ul', attrs={'style': 'list-style-type:none;'})
for li in soup.find_all(name='li'): # 存在多个附件
name = li.a.string
num = li.span.string
wbnewsid = re.search(r'getClickTimes\((\d*?),', num).group(1)
url = f'https://jwch.fzu.edu.cn/system/resource/code/news/click/clicktimes.jsp?wbnewsid={wbnewsid}&owner=1744984858&type=wbnewsfile&randomid=nattach'
num = requests.get(url).json().get('wbshowtimes')
file_list.append({"文件名称": name, "下载次数": num})
return file_list
except(requests.exceptions.ConnectionError):
return file_list
0x04 获取附件下载次数
如果只是爬取页面源代码,会只出现这个

又是个 Ajax
找啊找(一般会放在Ajax.js)
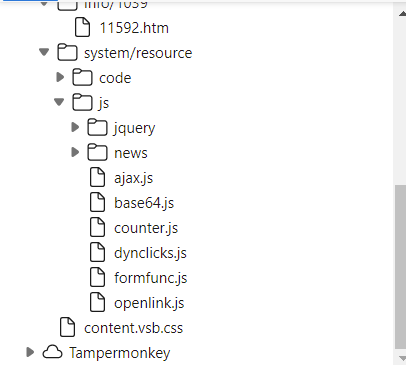

可以看出向这个url发起异步请求
url = f'https://jwch.fzu.edu.cn/system/resource/code/news/click/clicktimes.jsp?wbnewsid={wbnewsid}&owner=1744984858&type=wbnewsfile&randomid=nattach'
查看网络包也可以看到

返回 json格式下载数

num = requests.get(url).json().get('wbshowtimes')
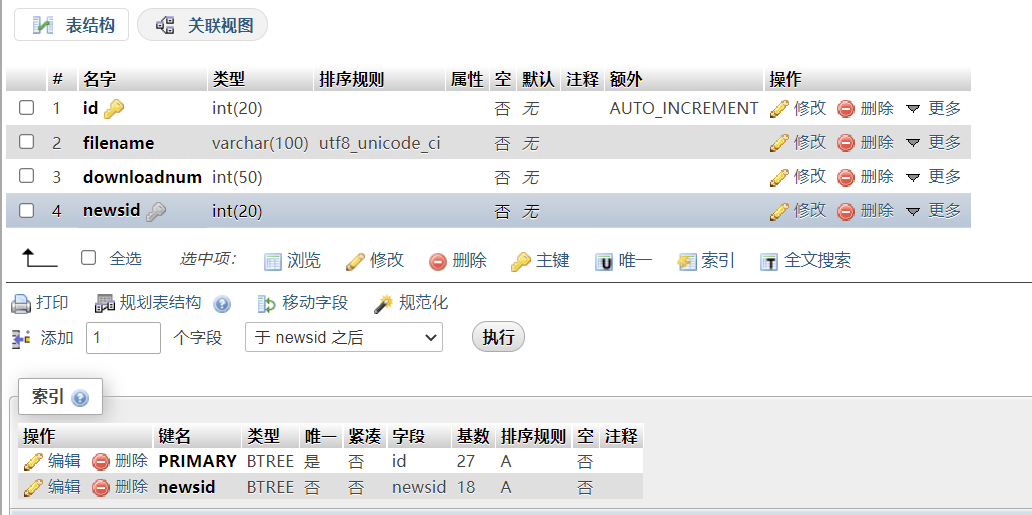
0x05 插入数据库
数据库结构
基本信息表
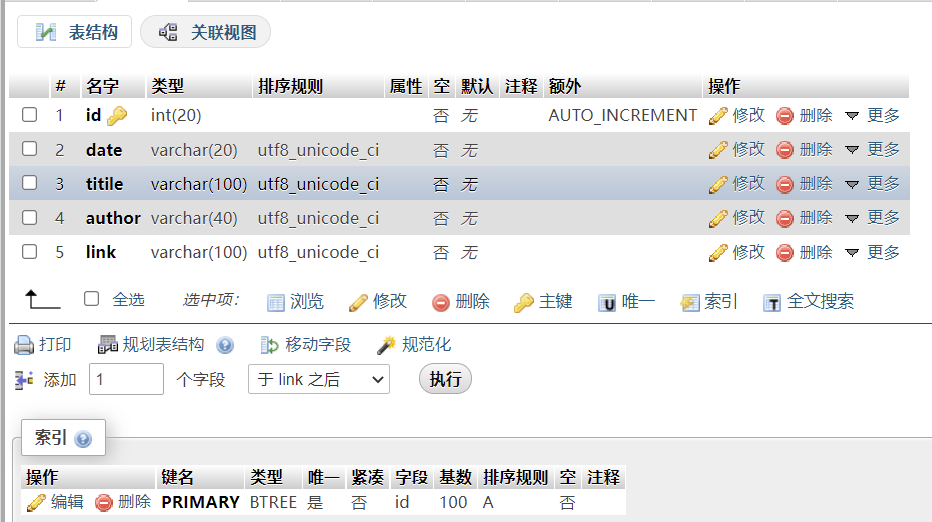
附件信息表
def insert_db(info_list):
conn = pymysql.connect(host="127.0.0.1", user="root", password="root", database="fzunews", charset='utf8') # 连接数据库
cursor = conn.cursor()
insert_news_sql = "INSERT INTO `news` (`date`, `titile`, `author`, `link`) VALUES(%s, %s, %s, %s);"
insert_file_sql = "INSERT INTO `files` (`id`, `filename`, `downloadnum`, `newsid`) VALUES(NULL, %s, %s, %s);"
select_sql = "SELECT id FROM `news` WHERE link=%s"
for info in info_list:
cursor.execute(insert_news_sql, (info["日期"], info["标题"], info["通知人"], info["链接"])) # 插入基本信息
conn.commit()
cursor.execute(select_sql, info["链接"]) # 获取信息id
insert_id = cursor.fetchall()[0][0]
conn.commit()
for file in info["附件下载"]:
cursor.execute(insert_file_sql, (file["文件名称"], file["下载次数"], insert_id)) # 插入附件信息
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭数据库连接
0x06 数据库外键设置
由于一条信息可能对应多个附件,因此在files表设置一个newsid字段作为 news表 id字段的外键,方便查询
先将数据库的存储引擎设置为InnoDB,这里使用 phpmyadmin
到结构的关联视图设置外键(外键应设置在多的一边)

注:某个表已经有记录了,添加外键失败,这时候只需要将两个要关联的表中的数据清空再从新添加外键关系即可
0x07 多线程
manager = Manager()
workQueue = manager.Queue(1000)
workQueue.put("https://jwch.fzu.edu.cn/jxtz.htm") # 第一页
for i in range(1, 5):
url = f"https://jwch.fzu.edu.cn/jxtz/{page_num-i}.htm"
workQueue.put(url)
pool = Pool(processes=10)
for i in range(11):
pool.apply_async(crawler, args=(workQueue, i))
注:我也不太了解,仅做尝试,而且效果似乎并不好。
import re
from bs4 import BeautifulSoup
import requests
import json
import pymysql
from multiprocessing import Manager, Pool, Queue
import time
def get_file(article_url):
"""获取附件名称和附件下载次数"""
file_list = []
try:
html = requests.get(article_url)
html.encoding = 'utf-8'
if re.search(r'附件【', html.text):
soup = BeautifulSoup(html.text, 'html.parser').find(name='ul', attrs={'style': 'list-style-type:none;'})
for li in soup.find_all(name='li'):
name = li.a.string
num = li.span.string
wbnewsid = re.search(r'getClickTimes\((\d*?),', num).group(1)
url = f'https://jwch.fzu.edu.cn/system/resource/code/news/click/clicktimes.jsp?wbnewsid={wbnewsid}&owner=1744984858&type=wbnewsfile&randomid=nattach'
num = requests.get(url).json().get('wbshowtimes')
file_list.append({"文件名称": name, "下载次数": num})
return file_list
except(requests.exceptions.ConnectionError):
return file_list
def insert_db(info_list):
conn = pymysql.connect(host="127.0.0.1", user="root", password="root", database="fzunews", charset='utf8') # 连接数据库
cursor = conn.cursor()
insert_news_sql = "INSERT INTO `news` (`date`, `titile`, `author`, `link`) VALUES(%s, %s, %s, %s);"
insert_file_sql = "INSERT INTO `files` (`id`, `filename`, `downloadnum`, `newsid`) VALUES(NULL, %s, %s, %s);"
select_sql = "SELECT id FROM `news` WHERE link=%s"
for info in info_list:
cursor.execute(insert_news_sql, (info["日期"], info["标题"], info["通知人"], info["链接"]))
conn.commit()
cursor.execute(select_sql, info["链接"])
insert_id = cursor.fetchall()[0][0]
conn.commit()
for file in info["附件下载"]:
cursor.execute(insert_file_sql, (file["文件名称"], file["下载次数"], insert_id))
conn.commit()
cursor.close() # 关闭游标
conn.close() # 关闭数据库连接
def getinfo(url):
"""获取每篇文章的通知人、标题、日期、详情链接"""
html = requests.get(url) # 获取页面html
html.encoding = 'utf-8'
soup = BeautifulSoup(html.text, 'html.parser') # BeautifulSoup对象的初始化
info_list = []
for li in soup.find(name='div', attrs={'class': 'box-gl clearfix'}).find_all(name='li'):
info_time = re.search(r'(\d\d\d\d-\d\d-\d\d)', str(li.span)).group(1)
info_author = re.search(r'【(.*?)】', str(li)).group(1)
info_title = li.a.string
if li.a['href'][0] == '.':
info_link = "https://jwch.fzu.edu.cn" + li.a['href'][2:]
elif li.a['href'][0] == 'i':
info_link = "https://jwch.fzu.edu.cn" + li.a['href']
else:
info_link = li.a['href']
file_list = get_file(info_link)
info_dict = {"日期": info_time, "通知人": info_author, "链接": info_link, "标题": info_title, "附件下载": file_list}
info_list.append(info_dict)
print(json.dumps(info_dict, indent=4,ensure_ascii=False, sort_keys=False, separators=(',', ':')))
print(info_dict)
insert_db(info_list)
def get_page_num(url):
"""获取总页数"""
html = requests.get(url) # 获取页面html
html.encoding = 'utf-8'
all_page_num = re.search(r'<a href="jxtz/1.htm">(\d{3})</a>', html.text, re.S).group(1)
print("总页数为:", all_page_num)
return all_page_num
def crawler(q, index):
while not q.empty():
url = q.get()
getinfo(url)
if __name__ == '__main__':
start = time.time()
page_num = int(get_page_num("https://jwch.fzu.edu.cn/jxtz.htm")) # 获取总页数
manager = Manager()
workQueue = manager.Queue(1000)
workQueue.put("https://jwch.fzu.edu.cn/jxtz.htm") # 第一页
for i in range(1, 5):
url = f"https://jwch.fzu.edu.cn/jxtz/{page_num-i}.htm"
workQueue.put(url)
pool = Pool(processes=10)
for i in range(11):
pool.apply_async(crawler, args=(workQueue, i))
# 在全部进程都放入pool之后再调用pool.close()关闭进程池,然后使用poll.join()运行
pool.close()
pool.join()
end = time.time()
print("总用时:", end-start)
















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











