







前言
这篇文章主要帮大家绕开一些本地使用spark调试获取远程hdfs数据的坑,个人在使用时也是基本把这些坑踩了一遍。希望下面的内容能给到其它人一些帮助,少走弯路减少不必要的时间损耗。
一、Hadoop配置注意事项
配置项我只贴出关键点
1.1 core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhostx:9000</value>
</property>
这里注意nameNode不要使用localhost,使用localhost后使用netstat -anp | grep 9000查看端口监听你会发现无法监听本机外的请求,当我们本地与远程服务器跨域时是访问不到的。

vim /etc/hosts ,自己设定一个域名配置为0.0.0.0。同时云服务器记得开放端口。
提示:如果没有开启安全验证的话服务器尽量不要对所有IP开放,因为hadoop很容易被端口扫描植入木马
1.2 core-site.xml
不要直接使用ip配置这样会导致namenode返回本机内网Ip远程无法访问
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>frue</value>
</property>
<property>
<name>dfs.datanode.use.datanode.hostname</name>
<value>true</value>
</property>
同时切记,其他所有配置项涉及到主机的,都不能再出现ip,必须用相应ip对应的域名来代替。
示例:
0.0.0.0 localhostx
17x.1xx.10x.194 hadoop
二、本地hadoop环境配置注意事项
面对如下错误
Exception in thread "main" java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Caused by: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
配置一个伪hadoop环境变量(不需要在本地真是安装hadoop),HADOOP_HOME指向下面文件夹,并将箭头中的两个文件放入system32下(需重启电脑生效)
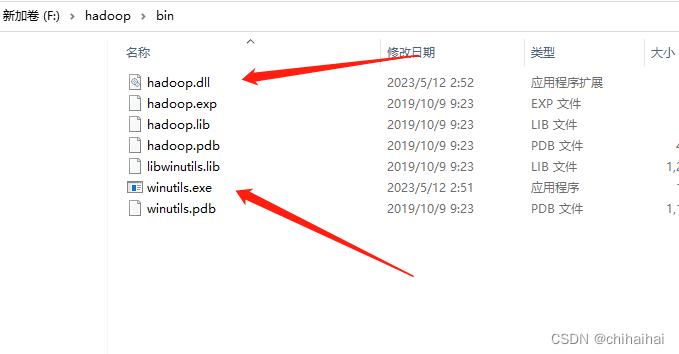
下载地址
https://gitcode.net/mirrors/steveloughran/winutils?utm_source=csdn_github_accelerator
如果是较新版本hadoop可以异步下面的地址尝试
https://raw.githubusercontent.com/cdarlint/winutils/master/hadoop-3.2.2/bin/winutils.exe
https://raw.githubusercontent.com/cdarlint/winutils/master/hadoop-3.2.2/bin/hadoop.dll
三、本地scala项目spark代码调试
脱敏代码,关键点
val sc = new SparkContext(conf)
sc.hadoopConfiguration.set("dfs.client.use.datanode.hostname", "true")
sc.hadoopConfiguration.set("dfs.datanode.use.datanode.hostname", "true")
System.setProperty("hadoop.home.dir", "F:\\hadoop\\bin")
System.setProperty("HADOOP_USER_NAME", "hdfs")
val rdd:RDD[String] = sc.textFile("hdfs://hadoop:9000/spark/七界武神.txt")
一定要配置dfs.client.use.datanode.hostname开启域名访问,否则会无法连通hdfs
提示:记得本地windows下hosts文件也要配置域名解析

成功拿到hdfs下数据
总结
常见的坑大致就以上几点,配置环境时仔细一些基本不会有其它坑了。如果遇到其它无法解决的问题欢迎私信讨论。















 4774
4774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









