







文章目录
前言
如果你在查找一些redis最佳实践或者内存优化的解决方案时常常会在各种繁杂的文章中充斥着大key,热key等字眼,其中的内容也是大径相庭。但是却基本看不到一些实际案例或者代码让你看了之后也云里雾里毕竟喜欢借鉴是我们国人传承至今的优秀美德,今天这个文章就简单分享下我的解决方案跟脱敏代码希望给需要的同学一点帮助。
一、缓存到底是使用String还是hash我该如何选择
在使用什么类型作为缓存的问题上我想很难有一个标准的答案,因为string和hash可以说各有优点。并且影响我们做出选择的往往是多个方面包括有数据量的大小,代码复杂度,投入回报率等。下面我们简单对比下两者擅长的领域
1.适合用 String 存储的情况:
每次需要访问大量的字段,存储的结构具有多层嵌套的时候。对于缓存的读取缓存的场景更多,并且更新缓存不频繁(或者每次更新都更新json数据中的大多数key),那么选择string类型作为存储方式会比较好
2.适合用 Hash 存储的情况:
在大多数情况中只需要访问少量字段,自己始终知道哪些字段可用,防止使用 mget 时获取不到想要的数据。对于缓存的更新比较频繁(特别是每次只更新少数几个键)时, 或者我们每次只想取json数据中的少数几个键值时,我们选择hash类型作为我们的存储方式会比较好。
在经过测试我们发现虽然hash一些情况下确实能减少内存占用,但是与String相比节省的内存微乎其微并没有想象中那么大影响。所以为了避免代码的复杂度我全部都使用了String类型作为缓存,具体选择还需要根据项目实际情况来应对很多时候我们需要避免过度设计。
下面向推荐两个有用的链接有兴趣的同学可以自行研究:
https://segmentfault.com/a/1190000019552836
https://stackoverflow.com/questions/16375188/redis-strings-vs-redis-hashes-to-represent-json-efficiency
二、什么是大key及其影响
下面我将使用脱敏代码进行演示,这里说明下为了代码的自由度和可控制性实际操作中我并没有采用被很多人推崇的spring cache来进行整合而是采用自定义注解 + AOP的方式进行了一些定制化的开发。
2.1 什么是 Redis 大 key?
对于大Key的定义你如果到网上搜或许能看到许多如下答案:

-===========================================================================================

-====================================================================================================

-============================================================================================================
其实对于大key的定义在不同的机器配跟业务场景下都是灵活的,这个要在实际环境中亲自去验证。如果数据量不大内存不是很吃紧阈值就可以放宽松些,如果内存比较吃紧string类型10k-xxk要根据响应实践数据处理跟网络传输时间来判断。Redis大key问题的定义及评判准则并非一成不变,而应根据Redis的实际运用以及业务需求来综合评估。例如,在高并发且低延迟的场景中,仅10kb可能就已构成大key;然而在低并发、高容量的环境下,大key的界限可能在100kb。因此,在设计与运用Redis时,要依据业务需求与性能指标来确立合理的大key阈值。
2.2 大key带来的影响
-
内存占用过高。大Key占用过多的内存空间,可能导致可用内存不足,从而触发内存淘汰策略。在极端情况下,可能导致内存耗尽,Redis实例崩溃,影响系统的稳定性。
-
性能下降。大Key会占用大量内存空间,导致内存碎片增加,进而影响Redis的性能。对于大Key的操作,如读取、写入、删除等,都会消耗更多的CPU时间和内存资源,进一步降低系统性能。
-
阻塞其他操作。某些对大Key的操作可能会导致Redis实例阻塞。例如,使用DEL命令删除一个大Key时,可能会导致Redis实例在一段时间内无法响应其他客户端请求,从而影响系统的响应时间和吞吐量。
-
网络拥塞。每次获取大key产生的网络流量较大,可能造成机器或局域网的带宽被打满,同时波及其他服务。例如:一个大key占用空间是1MB,每秒访问1000次,就有1000MB的流量。
-
主从同步延迟。当Redis实例配置了主从同步时,大Key可能导致主从同步延迟。由于大Key占用较多内存,同步过程中需要传输大量数据,这会导致主从之间的网络传输延迟增加,进而影响数据一致性。
-
数据倾斜。在Redis集群模式中,某个数据分片的内存使用率远超其他数据分片,无法使数据分片的内存资源达到均衡。另外也可能造成Redis内存达到maxmemory参数定义的上限导致重要的key被逐出,甚至引发内存溢出。
-
内存分布不均。集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大。
-
刷盘当使用 Always 策略的时候,如果写入是一个大 Key,主线程在执行 fsync() 函数的时候,阻塞的时间会比较久,因为当写入的数据量很大的时候,数据同步到硬盘这个过程是很耗时的。当 AOF 日志写入了很多的大 Key,AOF 日志文件的大小会很大,那么很快就会触发 AOF 重写机制。AOF 重写机制和 RDB 快照(bgsave 命令)的过程,都会分别通过 fork() 函数创建一个子进程来处理任务。在创建子进程的过程中,操作系统会把父进程的「页表」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,而不会复制物理内存,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。这样一来,子进程就共享了父进程的物理内存数据了,这样能够节约物理内存资源,页表对应的页表项的属性会标记该物理内存的权限为只读。随着 Redis 存在越来越多的大 Key,那么 Redis 就会占用很多内存,对应的页表就会越大。在通过 fork() 函数创建子进程的时候,虽然不会复制父进程的物理内存,但是内核会把父进程的页表复制一份给子进程,如果页表很大,那么这个复制过程是会很耗时的,那么在执行 fork 函数的时候就会发生阻塞现象。而且,fork 函数是由 Redis 主线程调用的,如果 fork 函数发生阻塞,那么意味着就会阻塞 Redis 主线程。由于 Redis 执行命令是在主线程处理的,所以当 Redis 主线程发生阻塞,就无法处理后续客户端发来的命令。
三、大key压缩
首先我们没必要对每个缓存值都做压缩,因为在压缩和解压缩的过程中也会消耗cpu同时也会增加数据处理时间,而且在我之前接触的业务中大key占比相对较小大概只站2百分之10不到。同时压缩后也会破坏数据的可读性,所以没有必要尽量不要对数据压缩处理。
3.1 注解标记可能需要压缩的数据
我们只需要对已知可能出现大key的地方进行是否需要压缩处理的判断
@cache(expire = 60 * 15, isDetectionReduce = true, reduceThresholdValue = 15)
isDetectionReduce为true则开启压缩检测,在注入缓存的时候会判断当前对象是否达到自定义的内存占用阈值,达到则进行压缩处理
reduceThresholdValue 这里是压缩判断阈值,默认单位为kb,意味着当前对象占用内存达到20kb则进行压缩
3.2 获取注解信息判断内存占用大小
Object target = proceedingJoinPoint.getTarget();
Method method = target.getClass().getMethod(signature.getName(), signature.getParameterTypes());
RedisCache annotation = method.getAnnotation(RedisCache.class);
int reduceThresholdValue= annotation.reduceThresholdValue();
boolean isDetectionReduce = annotation.isDetectionReduce ();
3.2 判断对象占用内存
这里我判断的是在java中的内存占用并不是存储在redis后的内存,在转为json后占用空间会有些偏差这里需要大家自行转换。判断内存占用我们可以使用jdk8为我们提供的ObjectSizeCalculator.getObjectSize(result),其实简单点也可以将对象string作为判断依据。这里我选择了ObjectSizeCalculator它本身的效率也是比较高的,如果你没用过可以试着打印下一个int占用的内存空间,它的默认输出单位为byte。一个对象对象头,对齐填充跑去data外的其他部分在64位系统下会占用12byte,所以一个int数据的内存占用是16。
补充:在我后续将jdk版本升级为dk17时发现 nashorn包被移除,并且nashorn-core:15.4也删除了该类。及决方案可以切换为jol-core来获取对象内存占用,具体使用方法自信查找
int memoryUsage = ObjectSizeCalculator.getObjectSize(result) - 12
// 如果内存大小大于15k则进行压缩
实际对象如果是15k的话如果转换为json内存会上升一些,因为一些换行对齐等都会占用空间。大概思路就是这样具体操作根绝业务来调整
3.2 gzip压缩json
楼主推荐使用jackson作为序列化框架,切记要配置让jackson携带类信息,否则反序列化可能会出现class java.util.LinkedHashMap cannot be cast to class异常
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance,ObjectMapper.DefaultTyping.NON_FINAL
, JsonTypeInfo.As.PROPERTY);
String json = objectMapper.writeValueAsString(result);
Gzip压缩工具使用jdk自带的就好
提示:我们知道在计算机中任何数据都是按ascii码存储的,而ascii码的128~255之间的值是不可见字符。 而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备, 由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。 所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
/**
* 使用gzip压缩字符串
* GZip压缩 256字节以上才有压缩效果
* @param str 要压缩的字符串
* @return 压缩后的字符串
*/
public static String compress(String str) {
if (str == null || str.length() <= 0) {
return str;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
try (GZIPOutputStream gzip = new GZIPOutputStream(out)) {
gzip.write(str.getBytes(StandardCharsets.UTF_8));
} catch (IOException e) {
log.error("字符串压缩失败str:{},错误信息:{}", str, e.getMessage());
throw new RuntimeException("字符串压缩失败");
}
return Base64.encodeBase64String(out.toByteArray());
}
/**
* 使用gzip解压缩
*
* @param compressedStr 压缩字符串
* @return 解压后的字符串
*/
public static String uncompress(String compressedStr) {
if (compressedStr == null || compressedStr.length() <= 0) {
return compressedStr;
}
ByteArrayOutputStream out = new ByteArrayOutputStream();
ByteArrayInputStream in;
GZIPInputStream gzip = null;
byte[] compressed;
String decompressed;
try {
compressed = Base64.decodeBase64(compressedStr);
in = new ByteArrayInputStream(compressed);
gzip = new GZIPInputStream(in);
byte[] buffer = new byte[1024];
int offset;
while ((offset = gzip.read(buffer)) != -1) {
out.write(buffer, 0, offset);
}
decompressed = out.toString(StandardCharsets.UTF_8.name());
} catch (IOException e) {
log.error("字符串解压失败compressedStr:{},错误信息:{}", compressedStr, e.getMessage());
throw new RuntimeException("字符串解压失败");
} finally {
if (gzip != null) {
try {
gzip.close();
} catch (IOException ignored) {
}
}
try {
out.close();
} catch (IOException ignored) {
}
}
return decompressed;
}
将压缩后的数据存储到redis就可以了
String gzip = CompressUtil.compress(json);
redisTemplate.opsForValue().set(key,gzip,expire, timeUnit);
原来一个10k出头的json压缩后大概只有2k可以看到gzip的效率还是相当高的
3.2 判断当前缓存是否为压缩json并对压缩数据进行解压
起初在网上搜寻到gzip的魔术判断为,把字符串转换成byte数组 判断该文件的文件头 GZIP文件头是0x1F 0x8B,也就是bytes[0] == 0x1F&& bytes[1] == 0x8B ,就像我们使用传说中的咖啡baby魔术判断是否为一个java文件一样gzip也有它的标识魔术。但是最终发现经过1f8b并不能用来判断字符串,只能用来判断以.gz结尾的文件。经过我不断验证发现gzip在字符串编码下开头是0x1f 0x75,但是我们忽略了如果要在网上传输为了避免不同系统之间造成数据丢失一般需要使用base64编码,在经过base64编码后gzip的魔术就无法使用了。经过我不断验证发现,好在gzip经过base64编码的前几位字符串是固定的我们可以根据字符串开头来判断当前压缩字符串是否使用了gzip6压缩从而确定后续要不要进行解码操作。
在经过很多在线gzip网站与自己随机生成上千个字符串测试后发现gzip经过base64编码后都是以H4sIAAAAAAAAA开头的所以我们可以使用
startsWith(“H4sIAAAAAAAAA”)来进行判断,如果后续有更好的方案我会来此更新。
String uncompress = CompressUtil.uncompress(cacheData.toString());
cacheData = objectMapper.readValue(uncompress,Object.class);
最后将解压后的字符串反序列化为java对象返回即可
总结
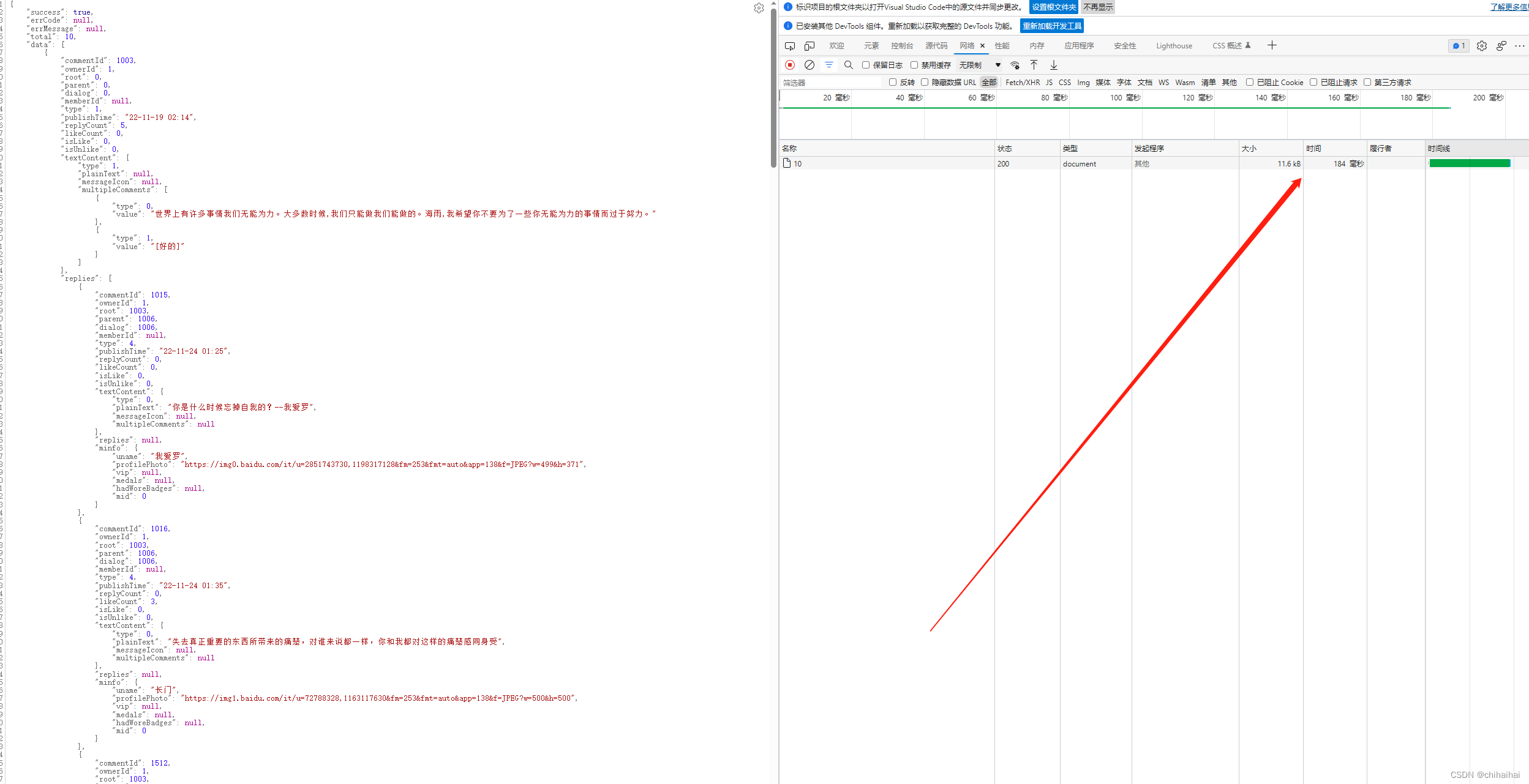
在测试环境下可能由于我使用的是mongodb本身性能就不错并且数据量并不多的背景下,对大key进行压缩后我发现并没有减少接口响应时间,一个10kb左右的数据最终响应耗时缩短了200-300ms。网络传输节省的时间被解压缩的消耗抵消了一小部分,不过我们的主要目的已经达到,节省了redis的内存消耗并且消除了大key带来的各种隐患。大概的流程就上文都有提到。有问题或不同见解欢迎留言或者私信交流。

















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









