






前言
我们之前利用 fork()函数来创建子进程,这种方式是 父子进程 共用一个代码,只是在代码当中使用了 if-else 语句来分流,达到父子进程运行不同的代码块的目的。但是其实本质上,还是父子共用一个代码和数据,只不过,如果父子进程 其中某一个先对某一个变量数据进程修改的话,那么,操作系统就会为这个 先修改变量数据的进程,在内存当中新开辟一块空间,然后,这个进程就会使用这个新的空间来修改数据,这是我们之前说过的写时拷贝;具体可以看上几篇文章:
Linux - 进程地址空间-CSDN博客
Linux - 进程控制(上篇)- 进程创建 和 进程终止-CSDN博客
那么有没有方式可以达到 父子进程运行不同的代码的效果呢?
答案是有的。就是我们这篇博客的主题 -- 进程程序替换。
进程程序替换
单进程的程序替换
我们先来简单实现一个 单进程的进程替换,先看看进程替换可以达到什么效果:

利用上述这个函数就可以实现,在程序当中的调用到另一个 可执行程序文件,如上就是各个参数的使用方式,最后是一个 "..." 是 可变参数,我们可以输入任意数量的 参数实现不同的调用效果,而其中会自己解析这个可变参数列表。
那么,在了解上述函数的作用之后我们就来,调用 bin 目录当中的 ls 这个命令的可执行文件(需要注意的是 ,execl ()函数当中的 可变参数列表在传参之时,最后要传入一个 NULL,表示这个参数列表到此为止。):

程序输出:

发现,程序在执行 “before:” 打印之后,就执行了 “ls” 这个命令,但是,程序最后的 “after” 没有的打印。
我们自己的程序,可以把系统当中的命令封装起来,有我们自己的程序,跑起来变成进程之后,就可以直接调用 系统命令。这种调用,我们就称之为 -- 程序替换。
而实现程序替换呢,有很多的接口(如下图所示),上述只是演示用一种接口的一种用法:

简单叙述,程序替换原理
那么为什么会出现上述的问题呢?为什么后面的 “after” 没有打印的呢?
我们知道,当我们运行一个可执行程序,这个程序就变成了一个进程, 既然是一个进程,操作系统一定会为这个进程创建一个 PCB 对象,用于维护这个进程;
而在 PCB 当中的代码区是一个虚拟地址,通过页表 把这个虚拟的一直映射到 内存当中的 物理地址。此时这个程序就跑起来了。
当这个程序执行到 excel()这个函数的时候,它的做法非常的简单粗暴,直接拿 excel 第一个 参数(路径位置)指向的 可执行程序当中的代码 和 数据,直接替换掉 本来在 内存当中原本 进程的 代码 和 数据。

在 text 这个 可执行文件生成的进程开始运行之时,或者说是 还没有运行到 excel()这个函数之时,PCB 当中映射的 代码 是 text 这个可执行文件当中 拷贝到内存当中代码。
当执行 当前程序执行到 excel()这个函数之时,此时, PCB 映射的 代码 就是 ls 这个可执行程序当中代码了;而且,此时不仅仅是 代码,数据也跟着一起替换了。注意这里的操作是直接替换。
简单来说,就是用 新的 可执行文件当中的代码和数据,替换掉 自己的代码和数据。然后,从0开始执行。
而,上述只是 进行了 内存当中 代码 和数据的替换,并没有创建新的PCB结构体,也并没有创建新进程。-- 这种就叫做程序替换。
而,发生程序替换之后,来程序当中的原本的代码就被新可执行文件当中的代码给替换了,所以上述例子当中才会被不会执行 excel()函数之后的代码,但是,如果 发生替换失败了,依然会按照老程序当中的老代码进行执行(也就是继续执行)
而且,exce*(* 代表所以 exce 系列的函数)这些函数,这有失败才会有返回值,成功是没有返回值的。
可执行程序的表头 (深层理解 程序替换原理)
在可执行程序编译时期,cpu 是如何知道各个区当中的入口的,也就是各个区的起始地址的?
其实,在 Linux 当中,可执行程序是有 格式的,一般是 ELF。
而,在可执行程序的最开始,有一个区专门存储这些程序 的 各个区的起始地址,我们把这个 可执行程序当中的这可以快空间称之为 -- 表头。
所以,在加载这个可执行程序之时,就算不加载这个程序的 代码和数据,都要先把这个程序的 表头加载到内存当中。
所以,再把编译时期,cpu 是如何拿到 代码的起始地址的,就是从这个可执行程序的表头当中获取到 各个区的起始地址。
当cpu 把表头加载到内存当中之后,既可以通过这个表头读取到这个可执行程序的 入口。加载到内存当中运行。
换句话说,如果某一个进程发生了程序替换,那么新的可执行程序当中一定是有表头的,那么。cpu就可以通过这个 表头来获取到 这个可执行程序的 入口,从而替换到 原来的 代码区当中。
多进程的程序替换
在上述单进程的例子的基础之上,创建子进程,在子进程当中 调用 excel()函数 调用 ls 这个可执行文件,(子进程在开始和结束的时候都打印上 开始和结束的 提示),当上述子进程的操作执行完毕之后,就直接 终止掉这个子进程:

输出:

发现,程序在执行子进程之后,当调用的到 excel()函数之后,调用到了 ls 这个可执行文件替换过来的代码,而且,子进程打印了 开始提示语句,但是没有打印结束语句,这也就印证了子进程PCB 指向的代码和数据已经被 ls 替换了。最后,父进程等待 子进程的退出。打印了父进程打印的 提示语句。
现在就出现了一个问题了,我们之前说过,子进程开始是直接继承了父进程的 代码和数据,如果 父子进程都没有修改数据的话,父子进程甚至连 数据都是 共用了。但是 ,父子进程代码是共用的啊?
上述,子进程调用 excel()函数,那么,按道理来说,子进程修改了代码,就会影响到 父进程,因为我们现在的理解是,父子进程是共用代码区当中的代码的。
但是,按照上述多进程的 例子的输出来说,父进程在最后的等待 子进程退出是正常输出的,没有收到影响。
所以我们得出结论,子进程当中发生了进程替换是不会影响到 父进程的。
但是,为什么会发生上述的输出结果呢?
因为进程之间是有独立性的,虽然父子进程之间共用 一个 代码和数据,当中如果其中的一方 对某一项是数据进行了修改,那么操作系统就会对这个修改的变量的进程,新开辟一个空间,用于存储这个进程修改的数据,这叫做写时拷贝。
但是,上述是对 代码进行修改,代码在此时也是发生了写时拷贝吗?
答案是的。写时拷贝不仅仅会发生在 父子进程 的数据修改当中,代码修改也是会 发生写时拷贝的。
所以,读到现在你应该就可以回答一个问题了:程序替换到底有没有创建一个新的进程?
答案肯定是没有的,只是发生 代码 和 数据 的写时拷贝(在单进程当中是直接进行 数据 和 代码的替换)
像上述是使用了 ls 这个系统当中实现的 可执行程序来替换当前程序的,我们不仅仅可以替换系统当中的,只要是可执行程序,不管是官方的,第三方的,还是自己实现的可执行程序都是可以进程替换的。
比如下面这个程序,我们在上述的 text 这个可执行文件的目录下创建一个新的文件 -- mycommand 这个可执行文件,然后再 text 运行之时替换为 mycommand 执行。
此时,在 text 可执行文件的当前目录下,有一些文件:

text 可执行程序代码:

mycommand 可执行程序的代码:

此时,text 当中执行了 excel()函数,替换为了 mycommand 当中的代码,运行text 的结果输出:

发现,也是成功把 text 当中的子进程部分的代码 替换成功了。

我们上述在调用 excel()函数之时,也是先确定 要替换的 新可执行文件在哪(像上述给的是 相对路径),然后在确定 调用的方式。
而且,上述的调用方式是直接 输入了 "mycommand" 调用了这个程序,和我们在命令行当中类似于 "./mycommand" 的方式调用不一样,没有带上路径;这是因为,在第一个参数就已经知道了这个可执行程序的路径位置了,所以就不用在调用方式当中再带上路径,直接调用即可。
而且,我们上述是在 C 的可执行程序当中调用 exce*()系列的函数,这系列的函数是可以调用 所有的可执行程序,不管是用什么语言写的可执行程序,都是可以调用的,因为 exce*()是系统调用层面的函数。
同样的,脚本文件也是可以 被替换到 其中来执行的。
text.sh 脚本文件如下:

脚本的调用方式 和 上述脚本的结果输出:

然后,我同样在 text 这个可执行文件当中利用 excel()函数调用上述脚本文件:

需要注意的是,上述第一个参数,也就是要运行的 可执行程序的 位置,不是 text.sh 所在的位置,因为我们不是运行脚本文件,而是运行这个 bash 来解释 text.sh 当中内容,来一个一个命令的执行。
./text 输出:

那么为什么 各种不同类型的语言都可以通过 C/C++ 当中 exec*()系列的函数 所替换调用呢?其实,不管是哪一种语言写出来的语言,本质上 最后运行都是变成了进程,而上述 exec*()系列的函数,就是系统调用层面的函数,他是在运行的程序当中进行代码和数据的替换。
另外,基本上,各个语言都会给我们提供 类似 C 当中的 exec*()类似的接口。
execle()接口,putenv()函数,替换当中的环境变量的变化
在 text 的 execl()当中传入的各个参数,如 "-a" 这些参数,都是可以在 mycommand 当中的main()函数的参数进行 接收同样,环境变量也是可以接收的:

输出:

在 mycommand 的main函数当中,把text 传入的 参数 "-a" 和 "-b" 都接受到了,而且环境变量也收到了默认的。
环境变量在 text 当中没有传入到 mycommand 当中,那 mycommand 是如何得到 环境变量的呢?
首先我们要明确的时,环境变量也是数据,在进程地址空间当中也是有 虚拟地址的,既然虚拟地址,那么一般都会通过页表 来映射到 内存当中的物理空间,也就是说,环境变量 和 命令行参数实际上,各个进程之间都有存储。

所以,在text 当中刚开始创建子进程,就已经从父进程当中复制好了 进程地址空间当中数据,即:子进程进程了父进程当中 数据(包括环境变量),父进程又是从哪里来的 环境变量数据呢?当然是 bash啦。
就算再程序替换当中替换了 代码 和 数据,就算替换了数据,环境变量信息不会被替换。
如果想在代码当中 添加一个 环境变量的话,可以使用 putenv()函数:


使用这样的方式就可以在当前进程之下,添加一个 环境变量,但是这个环境变量,当前进程的父进程是不能接收的,只能是这个进程的子进程可以接收;你可以理解为 类似于 C/C++ 当中的继承关系,子类有父类的属性,但是子类独有的属性,父类是没有的。
所以,如果你想添加一个 环境变量,让子进程接收到 话,直接在父类当中 putenv()就可以了。替换完的进程也是可以继承替换之前进程的环境变量的。
如果你是在像在 进程当中传入 当前进程的环境变量的话,可以使用 带 "e" 字母的 exec*()函数,比如 execle()函数:


像上述传入的是 父进程当中 ,或者是当前进程 当中环境变量,如果想自定义的话,可以自己定义一个数据传入(彻底替换环境变量列表):

程序替换的各种接口介绍
上述所说的 excel ()函数只是其中之一,实现进程替换的 exce*() 系列的函数还有很多:
上述七个是在 3 号手册当中的,在 2 号手册的当中还有一个 函数被单独拿出来了:

这些函数都是以 exec 开头的。
execl()接口
比如像上述的 excel()这个函数,最后是一个 "l" 这个字母,"l" 代表的意思就是 list 的意思,在我们上述传入在excel()这个函数当中传入参数的时候你可以发现,从第二个参数开始,我们给 对应的可执行文件当中传入的参数是 一个一个传入的,最后一个指向NULL,看起来就就像是 list 链表一样。

在上述的七个函数当中,函数名 带 "l" 的,说明这个函数可以 像链表一样一个一个传。
在命令行当中我们如何给这个可执行程序 的 main 函数传入参数的,就怎么样给这个 execl()函数传入参数:

返回来看第一个参数,我们看到是上述传入的是一个绝对路径,其实整个 exec*()系列的 函数的第一个参数都是要传入 对应要替换的可执行程序的 路径,函数通过这个 路径来找到 这个可执行程序。这个路径可以是 绝对路径 也可以是 相对路径。
总结:

通过上诉的传入 excel()函数的参数,可以知道 这个 新的 可执行程序在哪? 如何执行?带不带参数?
execlp()接口
![]()
上述在 "l" (list) 的基础之上,还带上了 p 这个字母,"p" 这个字母代表的意思是 "PATH" 。
execlp()这个函数除了在 可以像 list 一样指定新的程序的如何传入参数之外,它会自己从 默认的 系统当中 PATH 环境变量 保存的默认目录当中去 查找 第一个参数传入的 文件名。
比如上述的 ls 这个命令,我们使用 execl()函数是带上了绝对路径的,但是如果 你使用的是 execlp()这个函数的话,因为我当前被的 PATH 环境变量是保存了 ls 这个命令所在位置路径的。
所以,execlp()可以直接通过 PATH这个变量保存的 默认路径 找到 ls 这个可执行程序,所以,代码可以这样写(注:下述程序和上述的多进程例子一样,只是改变了 execlp()这个函数):

输出:
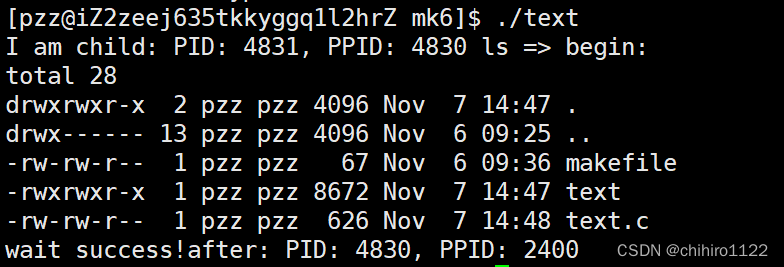
虽然传入的第一个参数,不是绝对路径,也不是相对路径,但是只要是在PATH 环境变量当中存储的 默认路径 是存在 ls 这个可执行文件的,那么execlp()这个函数就可以找到,发现和之前多进程这个例子的输出是一样的。
ececv()接口
![]()
"v" : vector;可以理解为数组,顺序表。
从参数当中你也可以发现,带 "v" 字母的 exec*()系列函数,第二个参数都是 一个 char* 数组,也就是 字符串指针数组。
所以,"v" 和 "l" 的区别就在于 带"v" 系列函数 在传入 新程序的调用方式的时候,使用的是 数组的方式来传入的:
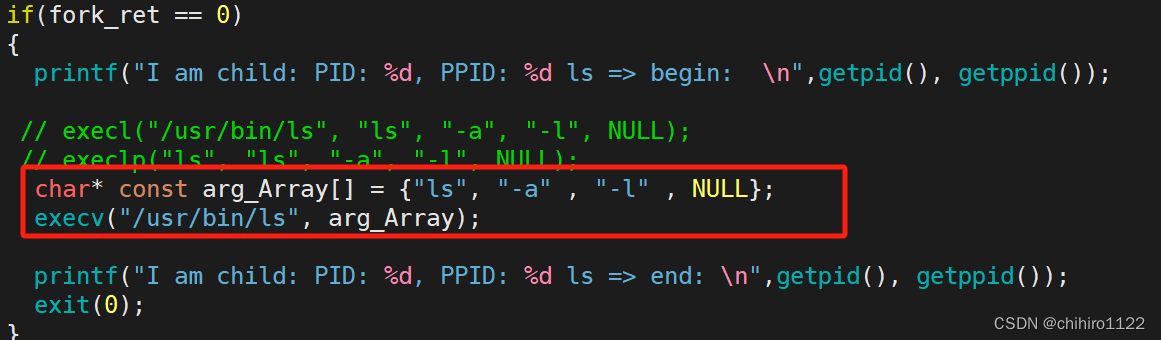
如上,定义一个 字符串指针数组 ,然后以传入这个数组方式传入这个 新程序的调用方式。
注: 这个 字符串指针数组 的最后一个参数必须是 NULL。
exeve()接口
之前说过,这个接口是 没有在之前的 6 大接口当中,这个 exeve()接口被单路拎出来的 放在 2 号手册当中,那么 这个 exeve()接口 和 上述的 6大接口有什么关系呢?
其实,上述的 6 大接口是 C 库函数,是 C 语言层面帮我们在操作系统之上封装的一个 库函数;而 execve()这个函数是 真正的 操作系统当中的系统调用函数。
可以说是,上述的 6 大函数 就是用 execve()函数来实现的;所以,在上述的 6 大函数当中不管是你调用那一个函数,最终都是调用了 execve()这个系统调用函数;这 6 大函数本质上就是对 execve()这个函数的 在语言层面上的封装。
比如:你传入可能只是文件名,可能是带有绝对路径 或者 相对路径,又或者是以 list 方式传入 新程序的调用方式(传入参数的方式),也可能是使用 vector 数组的方式来传入 命令行参数。
这些不同的传入方式在底层都是在进行各自函数的处理,然后调用 execve()这个操作系统层面的 系统调用函数。
总结
其实 在 exec*()系列的 函数当中,"l" , "v" , "p" , 这些后面的不同组合的名字就代表了不同的 使用方式,一个字母代表的是一种使用方式。所以,对于这七个函数的使用,只需要按照这些不同的 字母 代表的意思来使用即可。
bash 当中 进程替换 系列函数的使用
我们知道,我们在命令行当中运行的一个个进程,都是bash 为我们创建的子进程,而,为什么bash 实现的代码当中创建的进程,会执行我们所书写的程序,其实就是使用了上述所示的 进程替换的原理。
在 bash 当中,创建子进程,操作系统先为这个 子进程 创建一个PCB 对象,跟着这个PCB对象一起创建的还有,进程地址空间等等 用于维护 这个子进程的 信息。然后,此时 子进程和 bash 是共用一个 数据 和 代码的;
但是,在 bash 当中会使用 exec*()系列的函数,把 bash 创建的子进程当中的 代码 和 我们写的代码的进行替换,也就发生了 子进程 存储 新代码的 写时拷贝。
此时,在子进程当中,原本的 bash 的代码就被替换为了 我们所书写的新代码。
所以,exec*() 系列的函数,它承担的是一个 加载器的效果。
exec*()系列函数,就是代码级别的 加载器,把 参数当中指向的 新的 代码 ,加载到 当前进程的 代码 当中,然后按照 exec*() 参数当中传入的 新程序的调用方式来调用这个新的程序。这个调用方式也相当于是 命令行参数了。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











