






概述
FM (Factorization Machine) 算法可进行回归和二分类预测,它的特点是考虑了特征之间的相互作用,是一种非线性模型,目前FM算法是推荐领域被验证的效果较好的推荐方案之一,在诸多电商、广告、直播厂商的推荐领域有广泛应用。
PAI平台的FM算法基于阿里内部大数据的锤炼,具备性能优越、效果突出的特点。具体使用方式可以参见首页模板:
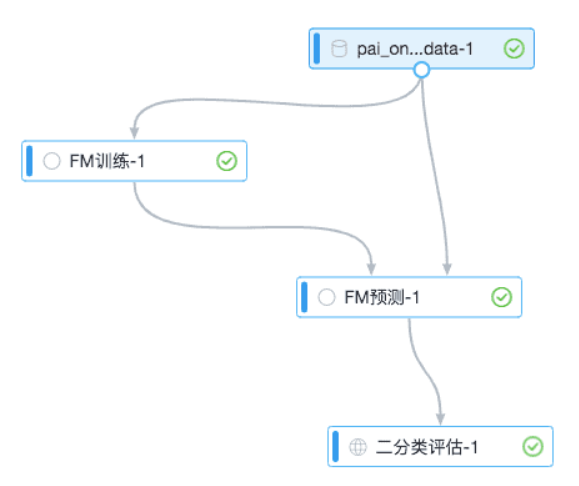
使用FM算法整体流程需要包含FM训练和FM预测组件,可以搭配评估组件使用。
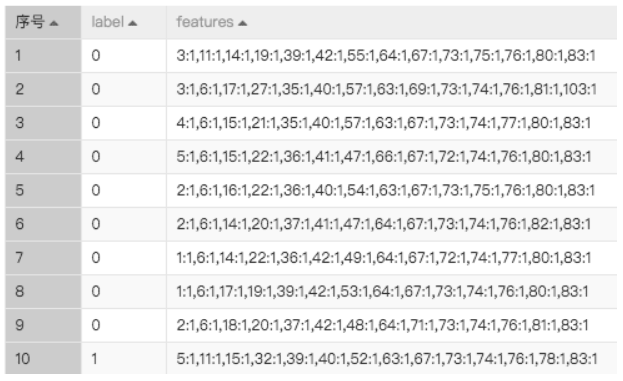
输入数据要求
目前PAI的FM算法只支持libsvm格式的数据,数据需要包含两列,分别是特征列和目标列。
- 目标列:Double类型
- 特征列:String类型,特征要以k:v格式输入,特征直接以逗号分隔
如图:
组件说明
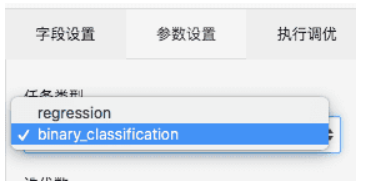
1.FM训练
在“参数设置”中可以设置回归或者分类两种模式:
PAI命令
| 参数 | 解释 | 取值 |
|---|---|---|
| tensorColName | 训练的特征列名 (kv格式的字符串,例如"1:1.0,3:1.0",特征的id必须是非负整数,取值范围是[0,Long.MAX_VALUE),可以不连续) | 必选 |
| labelColName | label列名 (要求是数值类型,如果任务类型是binary_classification,那么label值必须是0或1) | 必选 |
| task | 任务类型 | 必选,"regression" or "binary_classification" |
| numEpochs | 迭代数 | 可选,默认值10 |
| dim | 因子数,字符串,用逗号分隔的三个整数,表示0次项、线性项、二次项的长度 | 可选,默认值 "1,1,10" |
| learnRate | 学习率 | 可选, 默认值 0.01 |
| lambda | 正则化系数,字符串,用逗号分隔的三个浮点数,表示0次项、线性项、二次项的正则化系数 | 可选, 默认值 "0.01,0.01,0.01" |
| initStdev | 参数初始化标准差 | 可选, 默认值0.05 |
备注1:
- 如遇到训练发散,可适当降低学习率的值
2.FM预测
PAI命令
| 参数 | 解释 | 取值 |
|---|---|---|
| predResultColName | 预测结果列名 | 可选,默认"prediction_result" |
| predScoreColName | 预测得分列名 | 可选,默认"prediction_score" |
| predDetailColName | 详细预测信息列名 | 可选,默认"prediction_detail" |
| keepColNames | 保持到输出结果表的列 | 可选,默认全选 |
评估结果
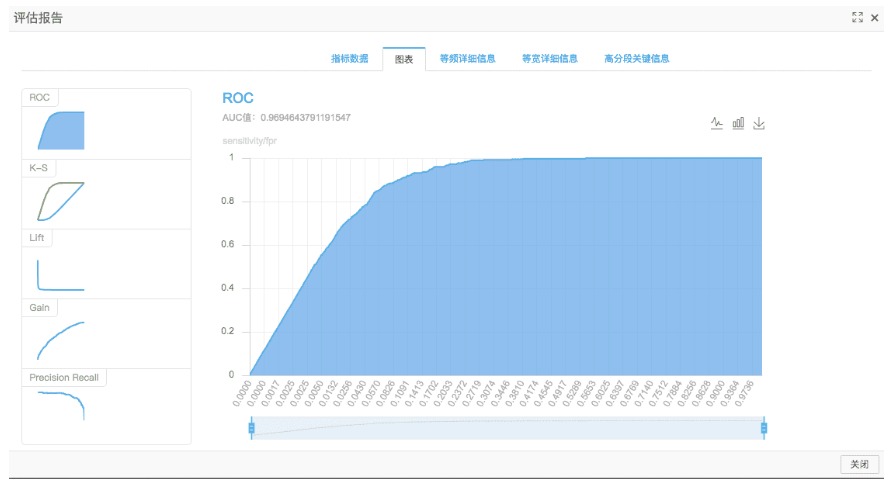
在首页模板案例的数据情况下,使用PAI FM生成的模型可以达到接近0.97的AUC
原文链接
本文为云栖社区原创内容,未经允许不得转载。















 5275
5275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









