







诞生的契机
故事从LR模型说起,传统的LR模型每个特征都是相互独立的,但是我们要处理的情况往往没有这么理想,当需要考虑到特征之间的关系时,得要通过人工的方式对这些特征进行组合。除此之外,非线性SVM可以对特征进行kernel映射,但是在特征高度稀疏的情况下,学习效果并不好。其他的可以学习到特征之间关系的算法都受限于输入和使用场景,因此FM(Factorization Machine)诞生了。
来一个贴合的小栗子,比如要根据用户的各种行为特征来预测对于某部电影的喜爱程度(评分)。如下图:
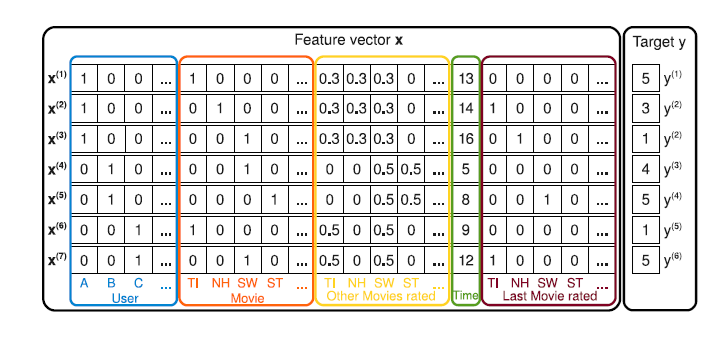
User、Move、Last Move rated这三项都经过one-hot编码,所以本身是高度稀疏的。并且仔细查看这几项特征可以发现,其中有可能存在相关联的特征,比如当前当前打分的电影和上一步看过的电影,以及这两部提到的电影在图中黄框都有对应的评分。这样的例子屡见不鲜,有两个突出特点:特征高度稀疏且特征之间可能存在关联,这正是FM的使用范畴。
算法模型
y ( x ) : = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = 1 + 1 n < v i , v j > x i x j y(x):=w_0+\sum_{i=1}^{n}{w_ix_i}+\sum_{i=1}^{n}{\sum_{j=1+1}^{n}{<v_i,v_j>x_ix_j}} y(x):=w0+i=1∑nwixi+i=1∑nj=1+1∑n<vi,vj>xixj
w 0 ∈ R , w ∈ R n , V ∈ R n × k w_0\in{\mathbb{R}},\textbf{w}\in{\mathbb{
{R}^n}},\pmb{V}\in{\mathbb{
{R}^{n\times{k}}}} w0∈R,w∈Rn,VVV∈Rn×k
< v i , v j > : = ∑ f = 1 k
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1617
1617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









