







目录
5.datax同步成功,hive/impala上select不出来数据
一、背景
最近在测试同步数据到kudu,过程中一踩一个坑,记录一下踩过的坑,也避免之后有人也像我一样举步维艰。
工具:
dolphinscheduler的 [datax]组件
二、报错内容
1.json格式错误
报错
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误. 您提供的配置信息不是合法的JSON格式: syntax error, position at 1143, name kuduConfig . 请按照标准json格式提供配置信息

问题定位
可以知道是json文件配置有问题了,然后仔细看报错name kuduConfig,去json里在这里仔细排查错误即可,本次我的错误是多加了引号
解决
错误内容 "kuduConfig": "{"kudu.master_addresses":"ip:7051"}",
正确内容 "kuduConfig": {"kudu.master_addresses":"ip:7051"},
2.没有文件
报错
/usr/bin/python2.7: can't open file '/bin/datax.py': [Errno 2] No such file or directory
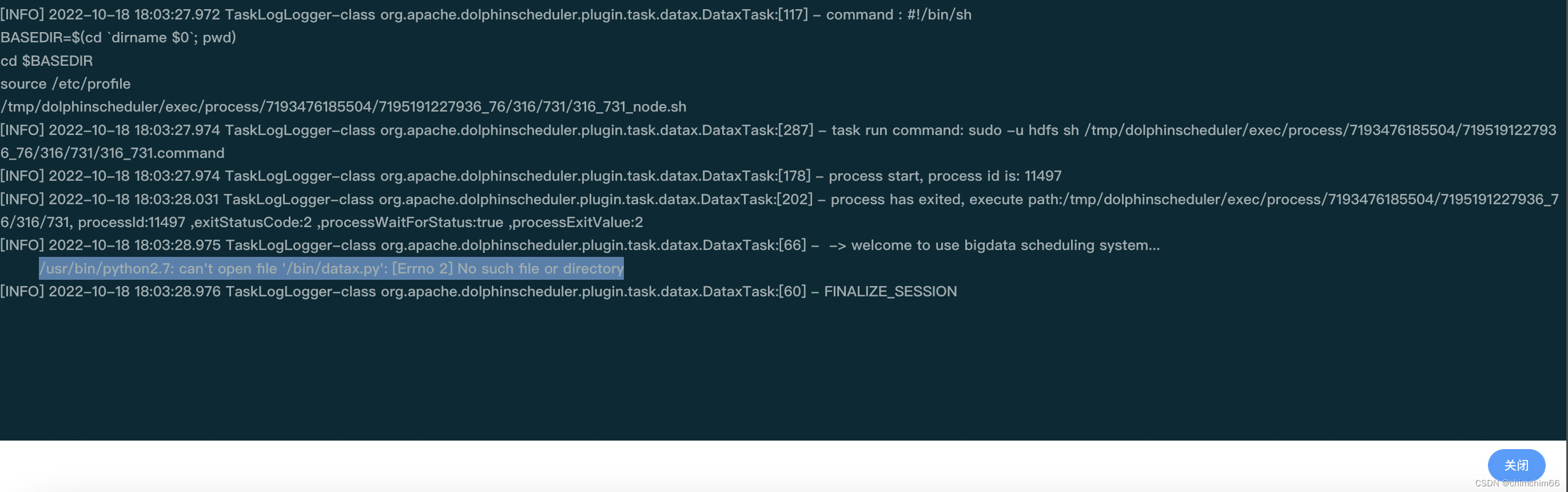
定位问题
无从下手,百度了一下,说是datax环境变量设置问题。datax的路径配置错误,找不到该文件。
解决
这个找不到的路径是之前官方默认的,现在看不需要指定到bin以及运行文件,只要到安装目录即可。
查看 vim /opt/soft/dolphinscheduler/conf/env/
将路径
export DATAX_HOME=/opt/soft/datax/bin/datax.py
改为
export DATAX_HOME=/opt/soft/datax
3.插件加载失败
报错
插件[postgresqlreader,kuduwriter]加载失败,1s后重试... Exception:Code:[Framework-12], Description:[DataX插件初始化错误, 该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 插件加载失败,未完成指定插件加载:[kuduwriter, postgresqlreader]
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Framework-12], Description:[DataX插件初始化错误, 该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 插件加载失败,未完成指定插件加载:[kuduwriter, postgresqlreader]

定位原因
居然根本没有安装kuduwriter插件,我真的哭了~
解决
跟开发小哥哥反馈,从github上下载一版集成到dolphinscheduler。
DataX/kuduwriter at master · alibaba/DataX · GitHub
4.必须指定主键
报错
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: GREATE_KUDU_TABLE_ERROR - org.apache.kudu.client.NonRecoverableException: must specify at least one key column
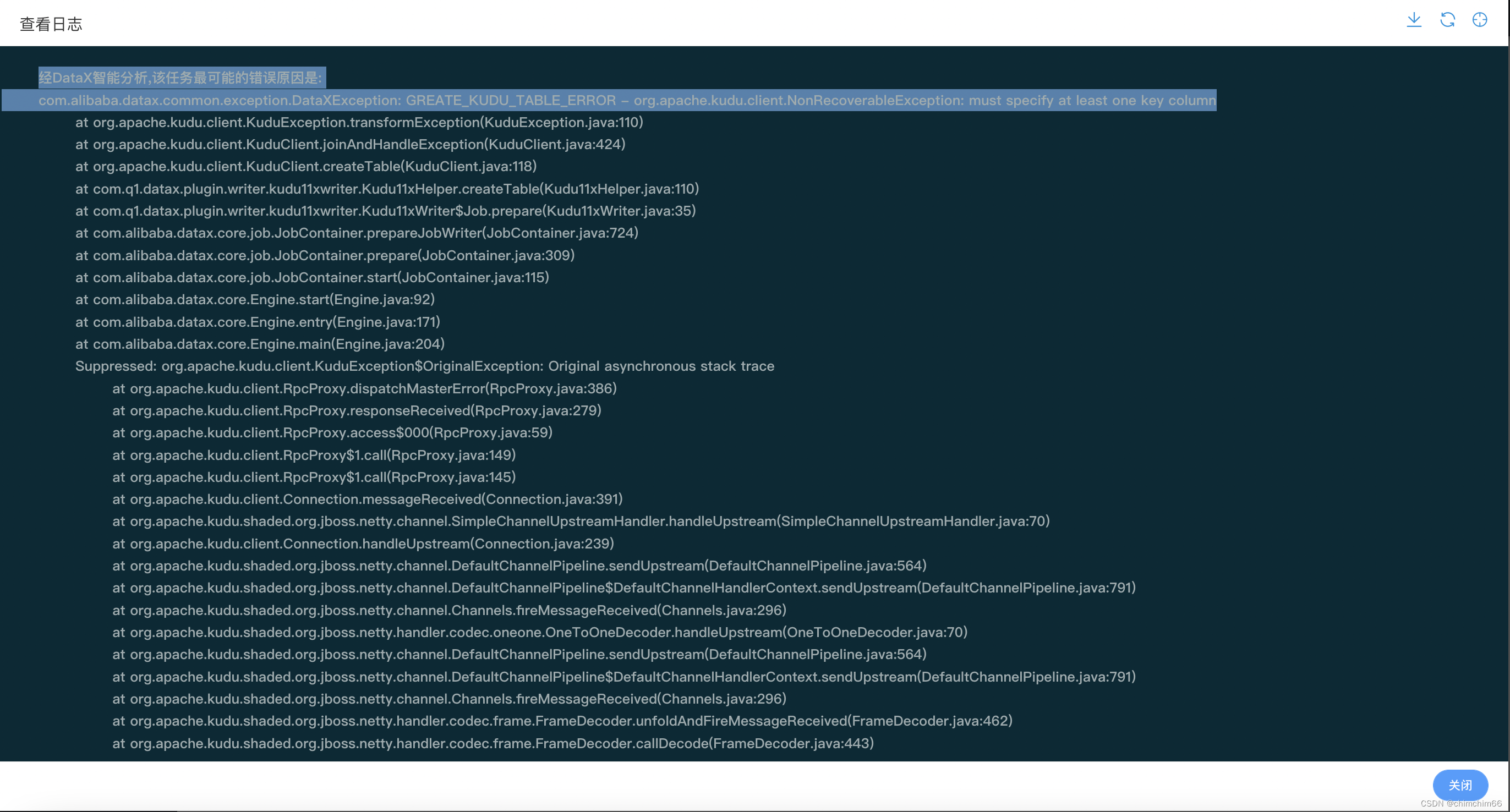
定位原因
一看就知道要指定主键,可是我明明指定了啊,结果仔细看了好几遍才发现是主键关键字大小写问题😓
解决
原来的
"primarykey": true
修改后
"primaryKey": true
另注意⚠️:主键列要放在最前面
5.datax同步成功,hive/impala上select不出来数据
问题
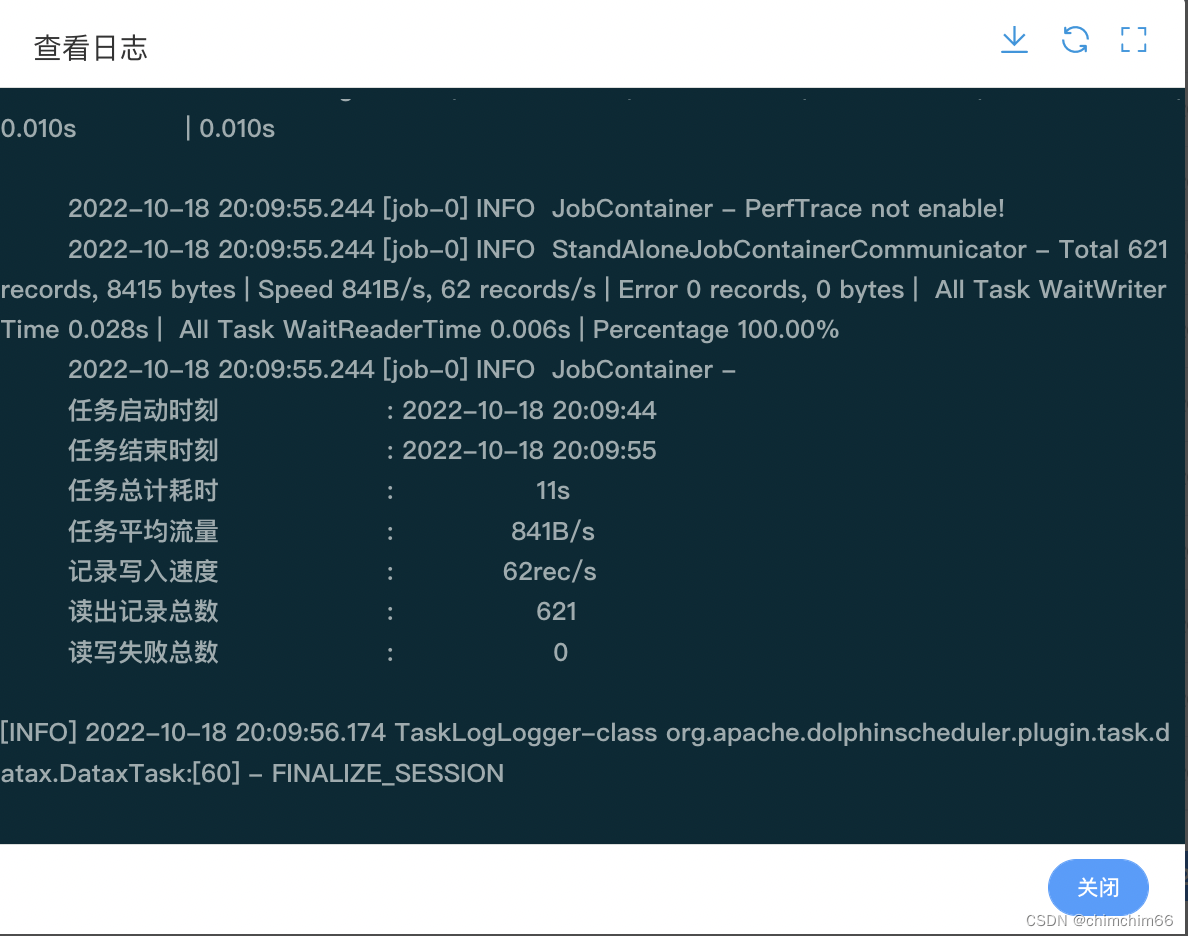
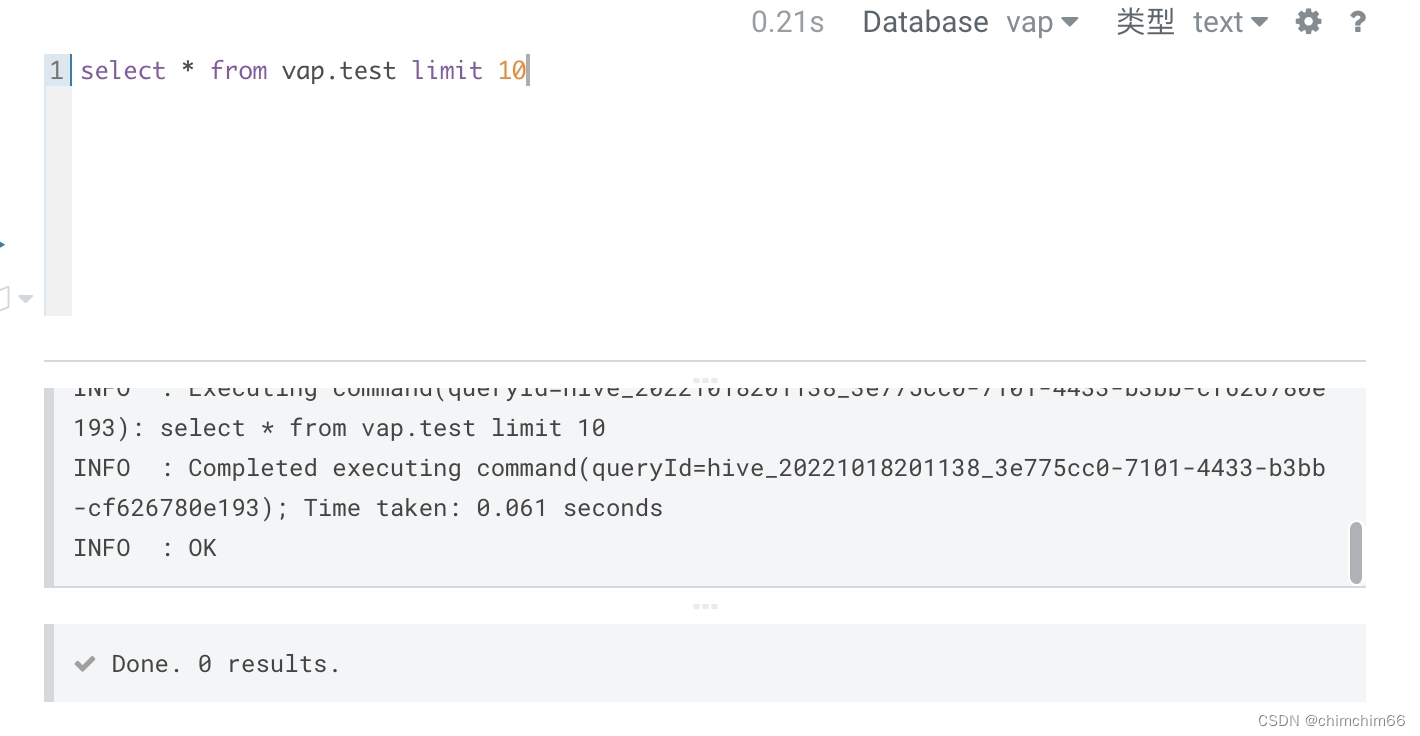
问题定位
json文件配置问题(首先主键一定要指定,然后字段名称和类型必须与建表语句一致,最后表名配置为 "table": "impala::db.table"
解决
修改前
{
"job": {
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:postgresql://ip:port/db"],
"querySql": ["select col1,col2 from public.table"],
}
],
"username": "use",
"password": "pwd"
}
},
"writer": {
"name": "kuduwriter",
"parameter": {
"kuduConfig": {"kudu.master_addresses":"ip:7051"},
"table": "db.test",
"replicaCount": 3,
"truncate": false,
"writeMode": "upsert",
"column": [
{"index": 0,"name":"col1","type":"string", "primaryKey": true},
{"index": 1,"name":"col2","type":"string"}
],
"batchSize": 1024,
"bufferSize": 2048,
"skipFail": true,
"encoding": "UTF-8"
}
}
}
],
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
}
}
}修改后
{
"job": {
"content": [
{
"reader": {
"name": "postgresqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:postgresql://ip:port/db"],
"querySql": ["select col1,col2 from public.table"],
}
],
"username": "use",
"password": "pwd"
}
},
"writer": {
"name": "kuduwriter",
"parameter": {
"kuduConfig": {"kudu.master_addresses":"ip:7051"},
"table": "impala::db.test",
"replicaCount": 3,
"truncate": false,
"writeMode": "upsert",
"column": [
{"index": 0,"name":"col1","type":"string", "primaryKey": true},
{"index": 1,"name":"col2","type":"string"}
],
"batchSize": 1024,
"bufferSize": 2048,
"skipFail": true,
"encoding": "UTF-8"
}
}
}
],
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
}
}
}三、参数配置说明
| name | default | description | 是否必须 |
|---|---|---|---|
| kuduConfig | kudu配置 (kudu.master_addresses等) | 是 | |
| table | 导入目标表名 | 是 | |
| partition | 分区 | 否 | |
| column | 列 | 是 | |
| name | 列名 | 是 | |
| type | string | 列的类型,现支持INT, FLOAT, STRING, BIGINT, DOUBLE, BOOLEAN, LONG。 | 否 |
| index | 升序排列 | 列索引位置(要么全部列都写,要么都不写),如reader中取到的某一字段在第二位置(eg: name, id, age)但kudu目标表结构不同(eg:id,name, age),此时就需要将index赋值为(1,0,2),默认顺序(0,1,2) | 否 |
| primaryKey | false | 是否为主键(请将所有的主键列写在前面),不表明主键将不会检查过滤脏数据 | 否 |
| compress | DEFAULT_COMPRESSION | 压缩格式 | 否 |
| encoding | AUTO_ENCODING | 编码 | 否 |
| replicaCount | 3 | 保留副本个数 | 否 |
| hash | hash分区 | 否 | |
| number | 3 | hash分区个数 | 否 |
| range | range分区 | 否 | |
| lower | range分区下限 (eg: sql建表:partition value='haha' 对应:“lower”:“haha”,“upper”:“haha\000”) | 否 | |
| upper | range分区上限(eg: sql建表:partition "10" <= VALUES < "20" 对应:“lower”:“10”,“upper”:“20”) | 否 | |
| truncate | false | 是否清空表,本质上是删表重建 | 否 |
| writeMode | upsert | upsert,insert,update | 否 |
| batchSize | 512 | 每xx行数据flush一次结果(最好不要超过1024) | 否 |
| bufferSize | 3072 | 缓冲区大小 | 否 |
| skipFail | false | 是否跳过插入不成功的数据 | 否 |
| timeout | 60000 | client超时时间,如创建表,删除表操作的超时时间。单位:ms | 否 |
| sessionTimeout | 60000 | session超时时间 单位:ms | 否 |
















 2718
2718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









