






环境配置信息:
Ubuntu:Ubuntu 14.04
Hadoop:hadoop-2.7.2
jdk:Java 1.8.0_73
配置步骤:
步骤1:将集群中的机器开启root登陆
步骤2:配置集群中的主机名和其对应的ip地址,修改/etc/hosts和/etc/hostname两个文件
| hosts 文件用于定义主机名与 IP地址之间的对应关系(三台主机配置相同 )。 命令:vim /etc/hosts
hostname这个文件用于定义Ubuntu的主机名(不同 ip对应的名字不同192.168.60.141对应 master,192.168.60.142对应slaver1,192.168.60.143 对应slaver2)。 命令:vim /etc/hostname 192.168.60.141
192.168.60.142
192.168.60.143
|

步骤3:jdk的安装与配置
步骤4:安装ssh,配置免密码登陆
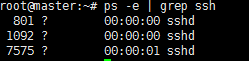
| 1、安装ssh: 命令:apt-get install ssh 2、查看是否安装成功: 命令:ps -e | grep ssh
3、更改sshd_config文件 命令:vim /etc/ssh/sshd_config
4、生成密钥 命令:ssh-keygen -t dsa 在此过程中,所有的操作全部默认回车。 5、生成密钥对及授权文件 命令:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 执行完这一步就可以在.ssh/文件夹下看到公钥文件 命令:ls .ssh/
6、将授权文件复制到其余节点相同目录下 命令:scp authorized_keys slaver1:~/.ssh 7、为了防止防火墙禁止一些端口的使用,所有的机子应该关闭防火墙 命令:ufw disable 8、测试是否安装成功 命令:ssh slaver1 如果在不用输入密码的情况下直接跳转到slaver1节点,说明安装成功,依次测试其他节点。 |

步骤5:Hadoop完全分布式安装部署
| 1、下载Hadoop二进制包 网址:http://hadoop.apache.org/releases.html
2、将Hadoop二进制包copy到master服务器中,并解压。 命令:tar -zxvf hadoop-2.7.2.tar.gz
3、配置hadoop-env.sh文件,修改文件中的JAVA_HOME
4、配置yarn-env.sh文件,修改文件中的JAVA_HOME
5、配置slaves文件,保存所有slaver节点的主机名
6、配置core-site.xml文件,添加如下内容: <configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hdfs_all/tmp</value> </property> </configuration>
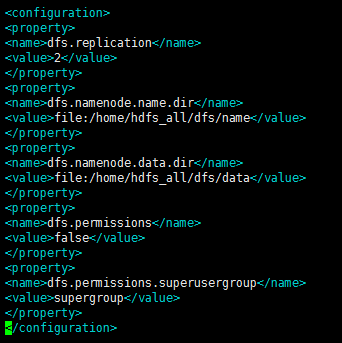
7、配置hdfs-site.xml文件,添加如下内容: <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hdfs_all/dfs/name</value> </property> <property> <name>dfs.namenode.data.dir</name> <value>file:/home/hdfs_all/dfs/data</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.permissions.superusergroup</name> <value>supergroup</value> </property> </configuration>
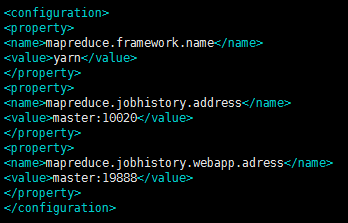
8、配置mapred-site.xml文件,添加如下内容 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.adress</name> <value>master:19888</value> </property> </configuration>
9、配置yarn-site.xml文件,添加如下内容 <configuration>
<!-- Site specific YARN configuration properties -->
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webaap.address</name> <value>master:8088</value> </property>
</configuration>
10、将上面配置好的Hadoop文件复制到剩余全部节点 命令: scp -r /root/u/hadoop/hadoop-2.7.2 slaver1:/root/u/hadoop/ |




步骤6:配置Hadoop环境变量
| 修改/etc/profile文件:
修改/etc/environment文件:
添加完成后生效两个文件: 命令:source /etc/environment |
步骤7:启动Hadoop,验证是否配置成功
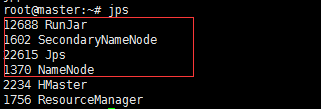
| 1、格式化namenode 命令:hadoop namenode -format 2、启动Hadoop 命令:start-all.sh 3、查看节点启动状况 命令:jps master节点:
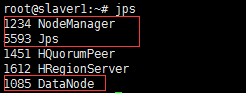
slaver节点:
|
附:
| 查看集群状态:hadoop dfsadmin -report 查看分布式文件系统: http://master:50070 查看 MapReduce:http://master:8088 如果此地址不能成功,将master换成ip地址 |















 196
196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









