







集群部署介绍
1.1Hadoop简介
(这部分先放着,环境搭好了再补上)
1.2环境说明
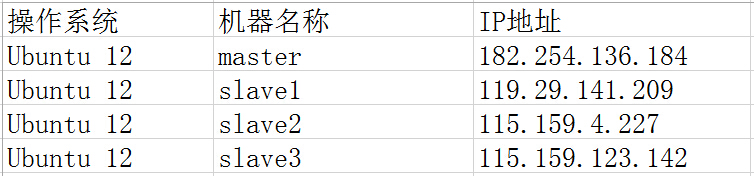
我的环境是在Ubuntu Server 12.04中配置的,Hadoop集群中包括4个节点:1个Master,3个Salve,节点之间可以相互ping通,节点IP地址分布如下:
Master机器主要配置NameNode和JobTracker的角色,负责总管分布式数据和分解任务的执行;3个Salve机器配置DataNode 和TaskTracker的角色,负责分布式数据存储以及任务的执行。
添加hadoop用户:
sudo adduser hadoop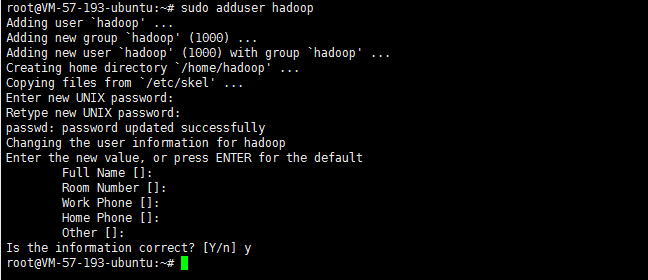
这里需要输入两次新用户的密码,其他选项默认即可。
1.3 环境配置
(1)修改当前机器名称
假定我们发现我们的机器的主机名不是我们想要的。修改文件/etc/hostname里的值即可,修改成功后用hostname命令查看当前主机名是否设置成功。
sudo vim /etc/hostname
这里提示了一个错误:hadoop is not in the sudoers file. This incident will be reported.因为我们现在不是在root用户下而是在hadoop用户下修改hostname,所以权限不够。我们可以在root下修改,但这里还是选择hadoop用户下,解决法办:
1)切换到root用户下
2)添加sudo文件的写权限,命令是:
chmod u+w /etc/sudoers
3)编辑sudoers文件
sudo vim /etc/sudoers
找到这行 root ALL=(ALL) ALL,在他下面添加xxx ALL=(ALL) ALL (这里的xxx是你的用户名)
ps:这里说下你可以sudoers添加下面四行中任意一条
youuser ALL=(ALL) ALL
%youuser ALL=(ALL) ALL
youuser ALL=(ALL) NOPASSWD: ALL
%youuser ALL=(ALL) NOPASSWD: ALL
第一行:允许用户youuser执行sudo命令(需要输入密码).
第二行:允许用户组youuser里面的用户执行sudo命令(需要输入密码).
第三行:允许用户youuser执行sudo命令,并且在执行的时候不输入密码.
第四行:允许用户组youuser里面的用户执行sudo命令,并且在执行的时候不输入密码.
4)撤销sudoers文件写权限,命令:
chmod u-w /etc/sudoers
切换到hadoop用户后再次执行
sudo vim /etc/hostname修改成功!
另外为了能正确解析主机名,最好也修改/etc/hosts文件里对应的主机名
sudo vim /etc/hosts修改完成后如果主机名没有变化,重启一下电脑
sudo shutdown -r now(2)配置hosts文件(必须)
“/etc/hosts”这个文件是用来配置主机将用的DNS服务器信息,是记载LAN内接续的各主机的对应[HostName IP]用的。当用户在进行网络连接时,首先查找该文件,寻找对应主机名对应的IP地址。
我们要测试两台机器之间知否连通,一般用”ping 机器的IP”,如果想用”ping 机器的主机名”发现找不见该名称的机器(这也就是为什么在修改主机名的同时最好修改该文件中对应的主机名),解决的办法就是修改”/etc/hosts”这个文件,通过把LAN内的各主机的IP地址和HostName的一一对应写入这个文件的时候,就可以解决问题。
例如:机器为”master:182.254.136.184”对机器为”salve1:119.29.141.209”用命令”ping”记性连接测试。测试结果如下:
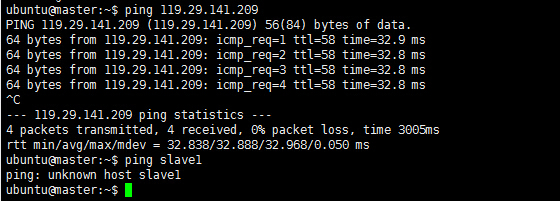
从上图中的值,直接对IP地址进行测试,能够ping通,但是对主机名进行测试,发现没有ping通,提示”unknown host——未知主机”,这时查看”master”的”/etc/hosts”文件内容会发现里面没有”119.29.141.209 slave1”内容,故而本机器是无法对机器的主机名为”slave1” 解析。
在进行Hadoop集群配置中,需要在”/etc/hosts”文件中添加集群中所有机器的IP与主机名,这样Master与所有的Slave机器之间不仅可以通过IP进行通信,而且还可以通过主机名进行通信。所以在所有的机器上的”/etc/hosts”文件中都要添加如下内容:
182.254.136.184 master
119.29.141.209 slave1
115.159.4.227 slave2
115.159.123.142 slave3
命令:sudo vim /etc/hosts,添加结果如下:
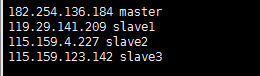
现在我们在进行对机器为”slave1”的主机名进行ping通测试,看是否能测试成功。
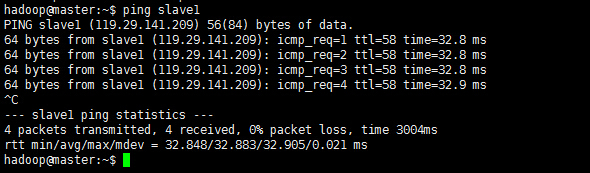
从上图中我们已经能用主机名进行ping通了,那么现在剩下的事儿就是在其余的Slave机器上进行相同的配置。然后进行测试。
2.SSH无密码验证配置
Hadoop运行过程中需要管理远端Hadoop守护进程,在Hadoop启动以后,NameNode是通过SSH(Secure Shell)来启动和停止各个DataNode上的各种守护进程的。这就必须在节点之间执行指令的时候是不需要输入密码的形式,故我们需要配置SSH运用无密码公钥认证的形式,这样NameNode使用SSH无密码登录并启动DataName进程,同样原理,DataNode上也能使用SSH无密码登录到 NameNode。
注意:如果你的Linux没有安装SSH,请首先安装SSH
Ubuntu下安装ssh:
sudo apt-get install openssh-server2.1SSH基本原理和用法
1)SSH基本原理
SSH之所以能够保证安全,原因在于它采用了公钥加密。过程如下:
(1)远程主机收到用户的登录请求,把自己的公钥发给用户。
(2)用户使用这个公钥,将登录密码加密后,发送回来。
(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
2)SSH基本用法
假如用户名为java,登录远程主机名为linux,如下命令即可:
ssh java@linux
SSH的默认端口是22,也就是说,你的登录请求会送进远程主机的22端口。使用p参数,可以修改这个端口,例如修改为88端口,命令如下:
ssh -p 88 java@linux
2.2 配置Master无密码登录所有Salve
1)SSH无密码原理
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,需要在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。这就是一个公钥认证过程,其间不需要用户手工输入密码。
2)Master机器上设置无密码登录
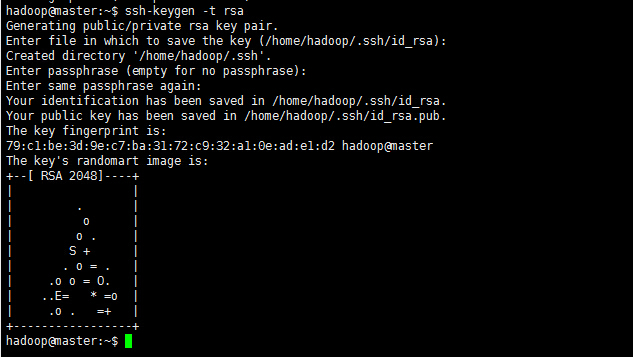
a. Master节点利用ssh-keygen命令生成一个无密码密钥对。
在Master节点上执行以下命令:
ssh-keygen -t rsa运行后询问其保存路径时直接回车采用默认路径。生成的密钥对:id_rsa(私钥)和id_rsa.pub(公钥),默认存储在”/home/用户名/.ssh”目录下。
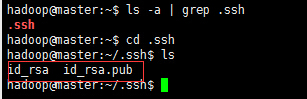
查看”/home/用户名/”下是否有”.ssh”文件夹,且”.ssh”文件下是否有两个刚生产的无密码密钥对。 ls -a | grep .ssh
b. 接着在Master节点上做如下配置,把id_rsa.pub追加到授权的key里面去。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
查看下authorized_keys的权限,如果权限不对则利用如下命令设置该文件的权限:
chmod 600 authorized_keys
c. 用root用户登录修改SSH配置文件”/etc/ssh/sshd_config”的下列内容。
检查下面几行前面”#”注释是否取消掉:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
sudo vim /etc/ssh/sshd_config
设置完之后记得重启SSH服务,才能使刚才设置有效。
然后退出root登录,使用普通用户验证是否设置成功。

从上图中得知无密码登录本级已经设置完毕,接下来的事儿是把公钥复制**所有的**Slave机器上。
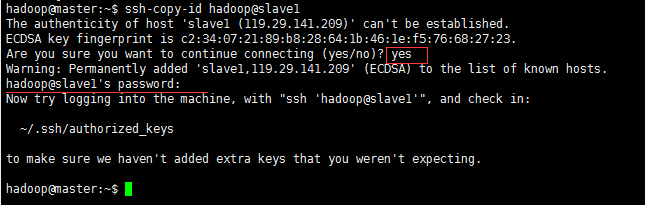
d.使用ssh-copy-id命令将公钥传送到远程主机上(这里以slave1为例)。
ssh-copy-id hadoop@slave1图中”hadoop@slave1’password:”处输入slave1的密码。
e. 测试是否无密码登录其它机器成功。

到此为止,我们经过5步已经实现了从”master”到”slave1”SSH无密码登录,下面就是重复上面的步骤把剩余的两台(slave2和slave3)slave服务器进行配置。这样,我们就完成了”配置master无密码登录所有的slave服务器”。
3、Java环境安装
jdk的安装在前面已经讲过了,详见:
http://blog.csdn.net/lweize325/article/details/50451859
4、Hadoop集群安装
所有的机器上都要安装hadoop,现在就先在Master服务器安装,然后其他服务器按照步骤重复进行即可。安装和配置hadoop需要以”root”的身份进行。
4.1 安装hadoop
首先用root用户登录”master”机器,将下载的”hadoop-2.6.0.tar.gz”复制到任一目录下,我这里是用xftp复制到/home/ubuntu目录下了。然后用下面命令把”hadoop-2.6.0.tar.gz”解压到/usr/local下,并将其重命名为”hadoop”,把该文件夹的读权限分配给普通用户hadoop。
sudo tar zxvf /home/ubuntu/hadoop-1.1.2.tar.gz -C /usr/local
cd /usr/local
sudo mv hadoop-1.1.2/ hadoop
chown -R hadoop:hadoop hadoopchown -R hadoop:hadoop(用户名:用户组) hadoop(文件夹)
最后在”/usr/local/hadoop”下面创建tmp (mkdir -p tmp),设 置可写权限:chmod -R 777 /usr/local/hadoop
把Hadoop的安装路径添加到”/etc/profile”中,修改”/etc/profile”文件,将以下语句添加到末尾,并使其生效(source /etc/profile):
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:HADOOP_HOME/bin:$PATH重新打开profile时或者执行其他命令是可能会有如下的错误

注意在设置环境变量时,尤其是linux系统中,你加入自己的环境变量,可还要附带上之前的变量。如最后加上:$PATH
4.2 配置hadoop
a) hadoop-env.sh
该”hadoop-env.sh”文件位于”/usr/local/hadoop/conf”目录下。
在文件中修改下面内容:
sudo vim /usr/local/hadoop/conf/hadoop-env.shexport JAVA_HOME=/usr/local/jdk8
b) core-site.xml 参考下面的内容修改:
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS master(即namenode)的地址和端口号。
sudo vim /usr/local/hadoop/conf/core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://182.254.136.184:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>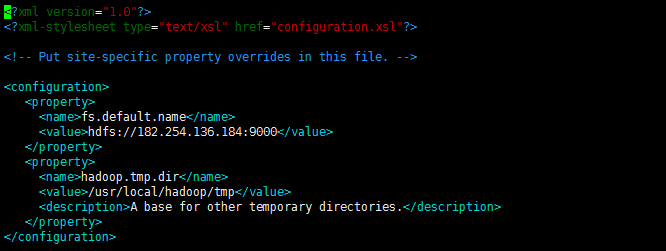
c) hdfs-site.xml
修改Hadoop中HDFS的配置,配置的备份方式默认为3。
sudo vim /usr/local/hadoop/conf/hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>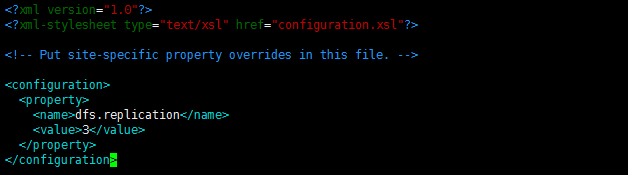
d) mapred-site.xml
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
sudo vim /usr/local/hadoop/conf/mapred-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://182.254.136.184:9001</value>
</property>
</configuration>e)配置masters文件
有两种方案:
(1)第一种
修改localhost为master
(2)第二种
去掉”localhost”,加入Master机器的IP:182.254.136.184
为保险起见,启用第二种,因为万一忘记配置”/etc/hosts”局域网的DNS失效,这样就会出现意想不到的错误,但是一旦IP配对,网络畅通,就能通过IP找到相应主机。
sudo vim /usr/local/hadoop/conf/masters
e)配置slaves文件(master主机特有)
有两种方案:
(1)第一种
去掉”localhost”,每行添加一个主机名,把剩余的Slave主机名都填上。
例如:添加形式如下:
slave1
slave2
(2)第二种
去掉”localhost”,加入集群中所有Slave机器的IP,也是每行一个。
例如:添加形式如下
119.29.141.209
115.159.4.227
115.159.123.142
原因和添加”masters”文件一样,选择第二种方式。
sudo vim /usr/local/hadoop/conf/slaves119.29.141.209 #slave1
115.159.4.227 #slave2
115.159.123.142 #slave3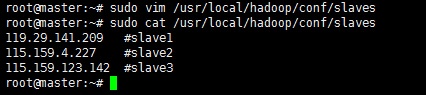
现在在Master机器上的Hadoop配置就结束了,剩下的就是配置Slave机器上的Hadoop。
4.3 启动及验证
(1)格式化HDFS文件系统
在”master”上使用普通用户hadoop进行操作。
cd /usr/local/hadoop
bin/hadoop namenode -format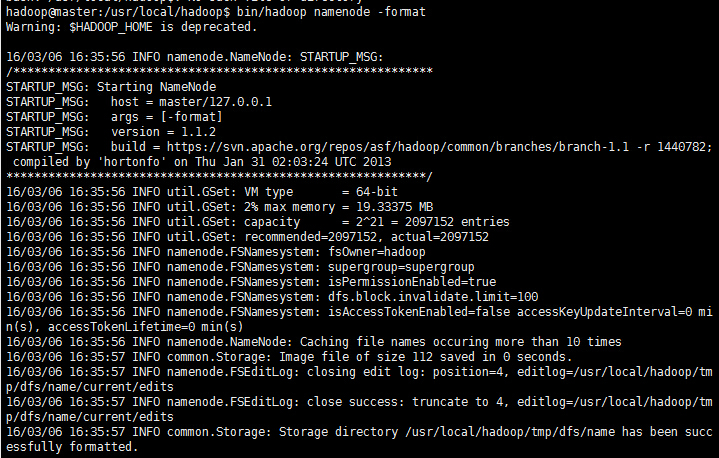

这里有一个警告,编辑”/etc/profile”文件,添加一个环境变量,之后警告消失:
export HADOOP_HOME_WARN_SUPPRESS=1
(2)启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
sudo ufw disable
sudo iptables -P INPUT ACCEPT
使用下面命令启动。
bin/start-all.sh
未完待续…















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









