






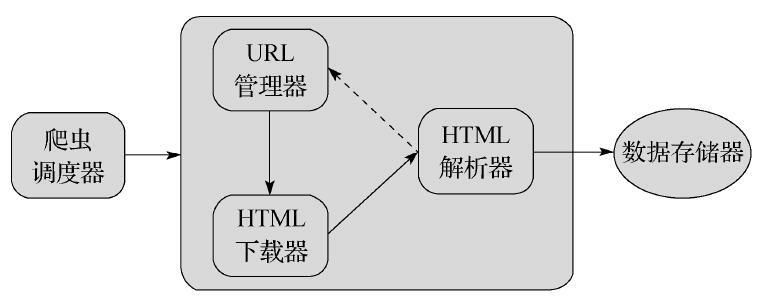
基础爬虫框架包含五大模块,分别为调度器,URL管理器,HTML下载器,HTML解析器,数据存储器
- 调度器:负责统筹管理其他四个模块
- URL管理器:复制URL的管理,维护已经爬取URL和未爬取的URL,URL去重,以及提供获取新URL的接口
- HTML下载器:将需要爬取URL界面下载
- HTML解析器:将下载的HTML进行数据提取和URL提取
- 数据存储器:将数据以数据库,文件等方式存储
URL 管理器
- 判断是否有待取的URL,方法定义为has_new_url()。
- 添加新的URL到未爬取集合中,方法定义为add_new_url(url), add_new_urls(urls)。
- 获取一个未爬取的URL,方法定义为get_new_url()。
- 获取未爬取URL集合的大小,方法定义为new_url_size()。
- 获取已经爬取的URL集合的大小,方法定义为old_url_size()。
URLManager.py:
class URLManager(object):
'''
url管理器, 主要包含两个集合,一个是已经爬取的url集合,另外一个是未爬取的url集合
'''
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def has_new_url(self):
'''
:return: 是否有未爬取的url
'''
return self.new_urls_size() != 0
def get_new_url(self):
'''
:return: 返回一个未爬取的url
'''
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
def add_new_url(self, url):
'''
:param url: 添加url到未爬取的urls集合
:return:
'''
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def new_urls_size(self):
'''
:return: 未爬取url集合大小
'''
return len(self.new_urls)
def old_urls_size(self):
'''
:return: 已爬取url集合大小
'''
return len(self.old_urls)
def get_old_ulrs(self):
return self.old_urls
HTML 下载器
HtmlDownloader.py:
import requests
class HtmlDownloader(object):
'''
html下载器,用来下载网页
'''
def download(self, url):
if url is None:
return None
headers = {
'user_agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:54.0) Gecko/20100101 Firefox/54.0',
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response.text
return None
HTML 解析器
HTML解析器主要提供一个parser对外接口,输入参数为当前页面的URL和HTML下载器返回的网页内容
from urllib.request import urljoin
from lxml import etree
from HtmlDownloader import HtmlDownloader
class HtmlParser(object):
def parser(self, page_url, html_content):
flag = page_url and html_content
if flag:
urls = self._get_new_url(page_url, html_content)
data = self._get_new_data(page_url, html_content)
return urls, data
return None
def _get_new_url(self, page_url, html_content):
'''
抽取当前界面的urls
:param page_url: 当前页面url
:param html_content: 当前html
:return: 抽取的urls集合
'''
html = etree.HTML(html_content)
links = html.xpath('//a/@href')
new_urls = set()
for link in links:
link = urljoin(page_url, link)
if 'item' in link or 'view' in link:
new_urls.add(link)
return new_urls
def _get_new_data(self, page_url, html_content):
'''
抽取当前界面数据
:param page_url: 当前页面url
:param html_content: 当前html
:return: 返回收取数据
'''
html = etree.HTML(html_content)
titles = html.xpath('//dd[@class="lemmaWgt-lemmaTitle-title"]//h1')
title = titles[0].text if titles else ''
summary_list = html.xpath('//div[@class="lemma-summary"]//*') # 提取摘要
summary = ''
for sum in summary_list:
sum.tail = sum.tail if sum.tail else ''
sum.text = sum.text if sum.text else ''
summary += sum.text + sum.tail
# print(title[0].text, text)
data = {}
data['url'] = page_url
data['title'] = title
data['summary'] = summary
return data
数据存储器
DataOutput.py:
import codecs
class DataOutput(object):
def __init__(self):
self.datas = []
def store_data(self, data):
if data is None:
return
print('store_data:', len(self.datas))
self.datas.append(data)
def output_html(self):
fout = codecs.open('baike.html', 'w', encoding='utf-8')
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
count = 0
for data in self.datas:
count += 1
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title'])
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
fout.write("<h1>{0}</h1>".format(count))
fout.write("</table>")
fout.write("</body>")
fout.write("</ht>")
调度器
调度 器用于统一协调管理其他四个模块,首先是初始化各个模块,然后通过crawl方法传递根url
SpiderSchedule.py:
from HtmlDownloader import HtmlDownloader
from Dataouput import DataOutput
from HtmlParser import HtmlParser
from URLManager import URLManager
class SpiderSchedule(object):
'''
爬虫调度器,负责初始化各个模块,然后通过crawl传递入口url
方法内部安卓运行流畅控制各个模块工作
'''
def __init__(self):
self.manager = URLManager()
self.downloader = HtmlDownloader()
self.parser = HtmlParser()
self.output = DataOutput()
def crawl(self, root_url):
# 添加入口url
self.manager.add_new_url(root_url)
# 判断是否有新的url,同时判断抓取url个数
while self.manager.has_new_url() and self.manager.old_urls_size() < 10:
try:
# 1.从URL管理器获取新的URL
new_url = self.manager.get_new_url()
# 2.将URL交给HtmlDownloader下载
html = self.downloader.download(new_url)
# 3.将下载的页面交给HtmlParser解析
urls, data = self.parser.parser(new_url, html)
# 4.将解析的数据存储,将重新抽取的URL交给URLManager
self.output.store_data(data)
for url in urls:
self.manager.add_new_url(url)
print('已经抓取{0}个链接:'.format(self.manager.old_urls_size()), new_url)
except Exception as e:
print(e.args)
print('crawl failed:', url)
self.output.output_html()
if __name__ == '__main__':
schedule = SpiderSchedule()
schedule.crawl('http://baike.baidu.com/view/284853.htm') # 爬取百度百科词条















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









