









爬虫的基础架构及常用的工具
写在前面
爬虫和页面解析都是实操性非常强的技能,需要分析待爬取的网站和信息,过程中不乏需要很多尝试和调整。
爬虫的基础架构
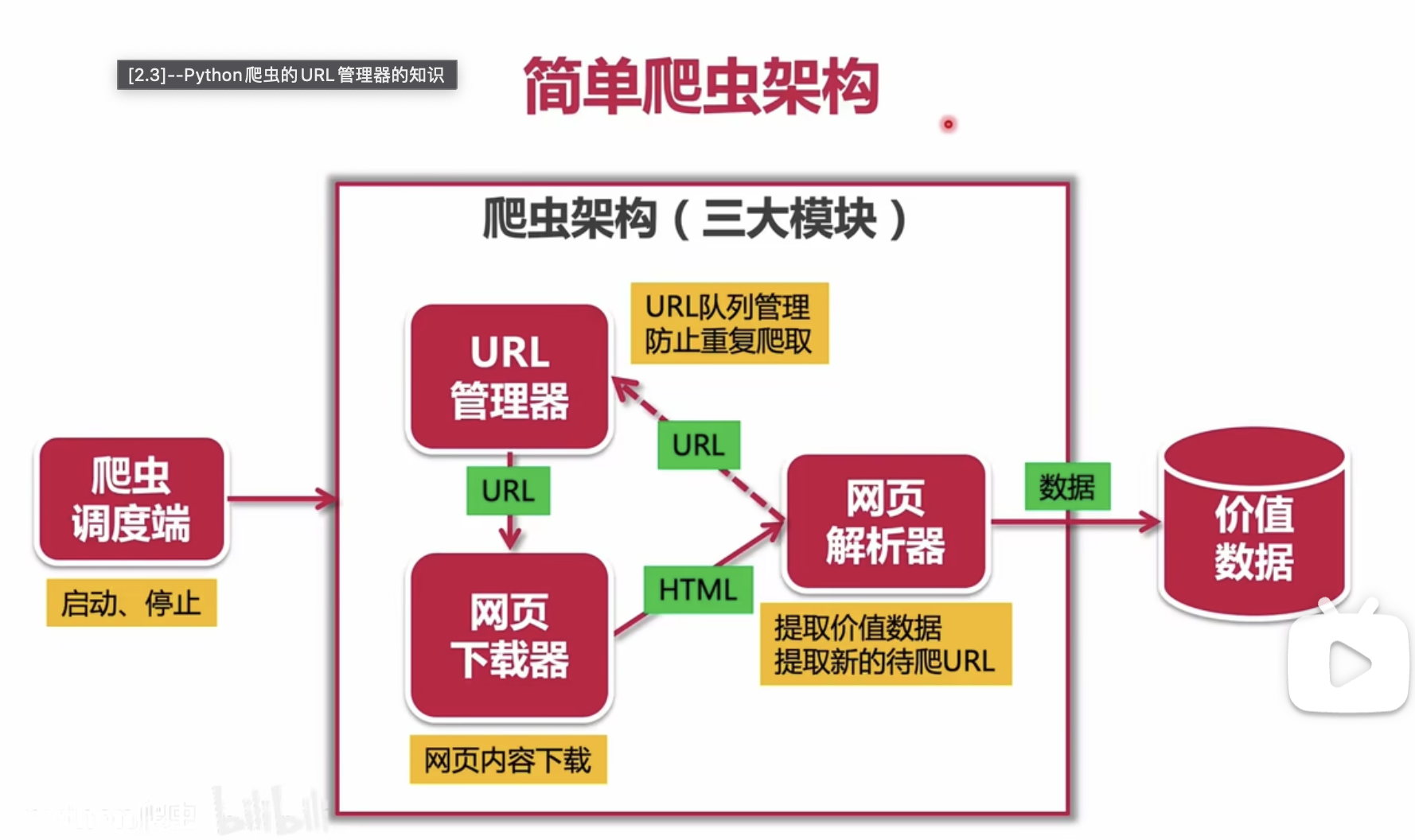
基础架构方面主要分为 3 个部分,分别是 URL 管理器、网页下载器以及网页解析器。
- URL 管理器:维护需要爬取的 URL,遇到新的 URL 就加入进去,爬取过的 URL 需要标记为已爬取,如此实现 URL 的管理,不重复爬取。一般构建一个类来管理,其中常用的数据结构主要是集合,也可以用队列来辅助维护顺序。
- 网页下载器:也就是获取网页的 html,静态网页一般用 requests 就可以,动态的需要其他工具如 selenium 等暂不介绍。
- 网页解析器:对于获取的 html 文件,一方面需要解析获取其中有价值的内容,另一方面其中包含的 URL 可以补充到 URL 管理器中。解析 html 前就需要对其有基本的了解,知道自己的想要获取的内容在哪个位置或部分,用什么方式提取想要的信息。了解基本的 html 语言,弄清楚目标信息之后,可以借助很多网页解析工具来辅助完成,可以选择正则表达式 re,但是某些功能不够灵活,常用的还有 BeautifulSoup/bs4,xpath 等。
常用的爬虫工具介绍
本部分就网页获取及解析两方面做重点介绍。
requests
记得很早我第一次接触这个模块包的时候,有一个小乌龙,千万注意最后是 s 结尾,不要漏打……
官方文档:https://requests.readthedocs.io/en/latest/
安装方式:pip install requests
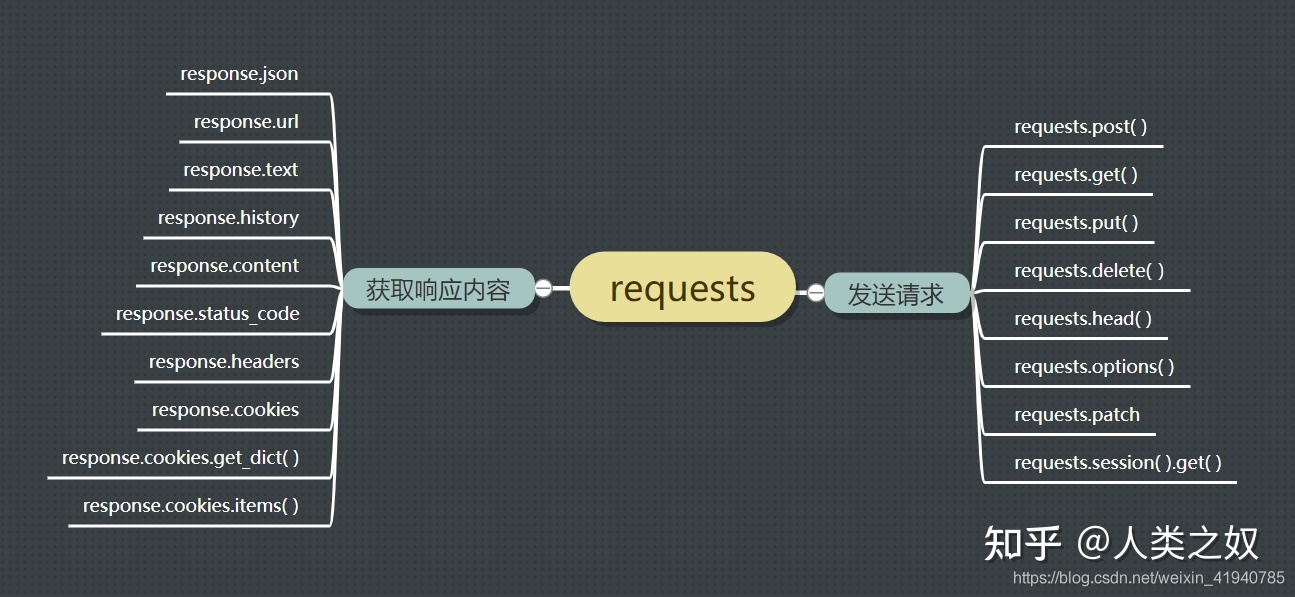
(1)requests 有很多不同的请求方式,都可以携带参数。以最常用的 get/post 请求方式举例,携带的参数及意义如下:

其中 headers 和 cookies 等在爬虫中需要特别注意,某些网站会有很多检测爬虫的方法,所以需要以各种方式模拟成真人通过浏览器的方式才能成功访问和获取到网页的页面信息。
(2)requests 发出请求之后得到的对象中包含了当次请求的返回信息。status code 代表了请求的成功及问题,encoding 对于包含中文的网页比较重要,如果编码和网页中实际使用的不一致,则会出现乱码的情况。

BeautifulSoup/bs4
一般的 html 页面都有很多嵌套结构,非常符合树的特点,而 Bs4 正是通过将 html 构建成一棵树来实现内容的遍历和搜索。
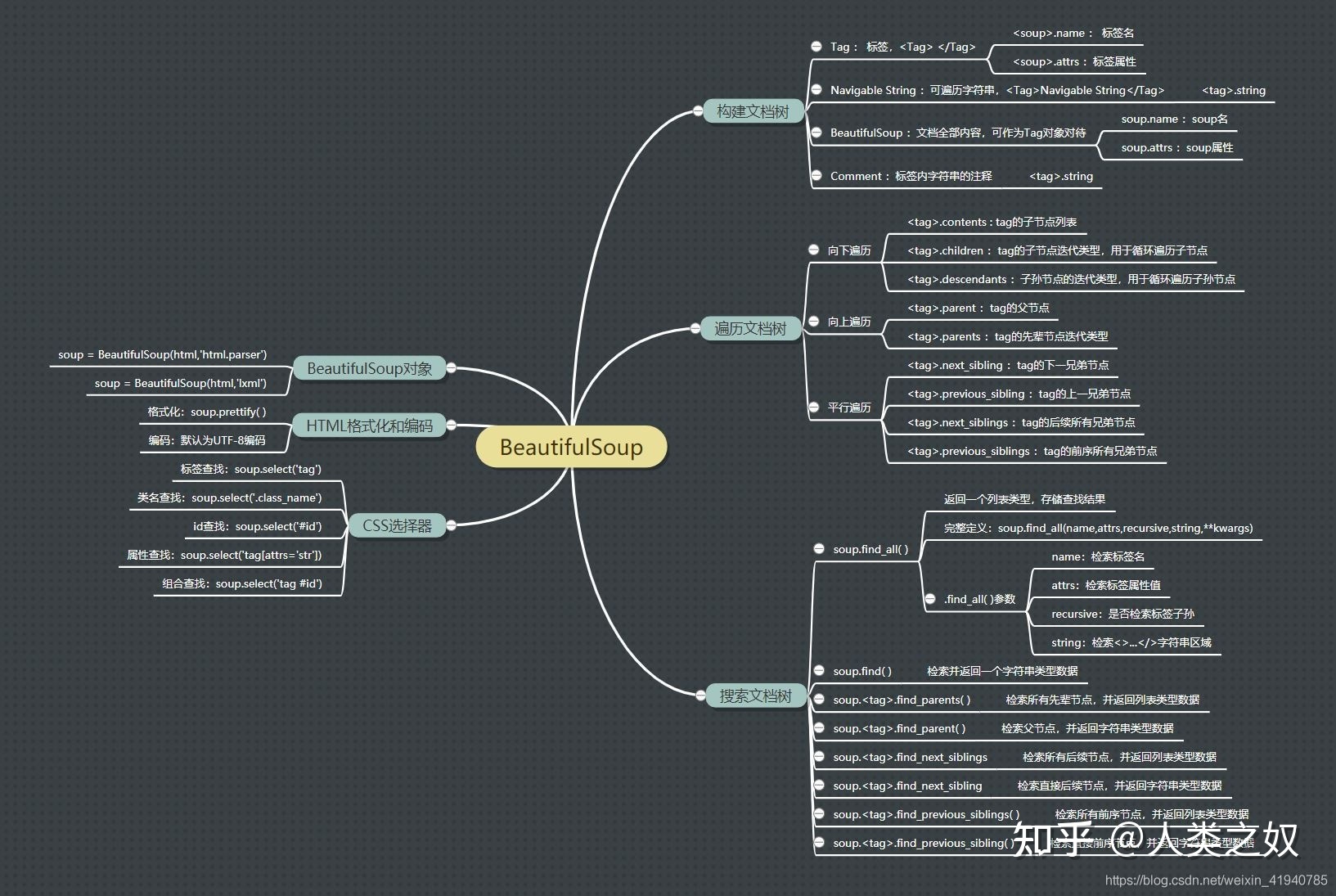
-
bs4 中对象的种类:Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag,NavigableString,BeautifulSoup,Comment. -
文档树的遍历:树中的每个节点,都有其父、子、兄弟等节点的信息,能够实现很自由的访问和遍历。
| 向下遍历方法 | 描述 |
|---|---|
| tag.contents | tag标签子节点 |
| tag.children | tag标签子节点,用于循环遍历子节点 |
| tag.descendants | tag标签子孙节点,用于循环遍历子孙节点 |
| 向上遍历方法 | 描述 |
|---|---|
| tag.parent | tag标签父节点 |
| tag.parents | tag标签先辈节点,用于循环遍历先别节点 |
| 平行遍历方法 | 描述 |
|---|---|
| tag.next_sibling | tag标签下一兄弟节点 |
| tag.previous_sibling | tag标签上一兄弟节点 |
| tag.next_siblings | tag标签后续全部兄弟节点 |
| tag.previous_siblings | tag标签前序全部兄弟节点 |
- 文档树的搜索:主要有 find() 和 find_all(),这点很像正则库,并且还支持参数。
| 遍历方法 | 描述 |
|---|---|
| soup.find_all( ) | 查找所有符合条件的标签,返回列表数据 |
| soup.find | 查找符合条件的第一个个标签,返回字符串数据 |
| soup.tag.find_parents() | 检索tag标签所有先辈节点,返回列表数据 |
| soup.tag.find_parent() | 检索tag标签父节点,返回字符串数据 |
| soup.tag.find_next_siblings() | 检索tag标签所有后续节点,返回列表数据 |
| soup.tag.find_next_sibling() | 检索tag标签下一节点,返回字符串数据 |
| soup.tag.find_previous_siblings() | 检索tag标签所有前序节点,返回列表数据 |
| soup.tag.find_previous_sibling() | 检索tag标签上一节点,返回字符串数据 |
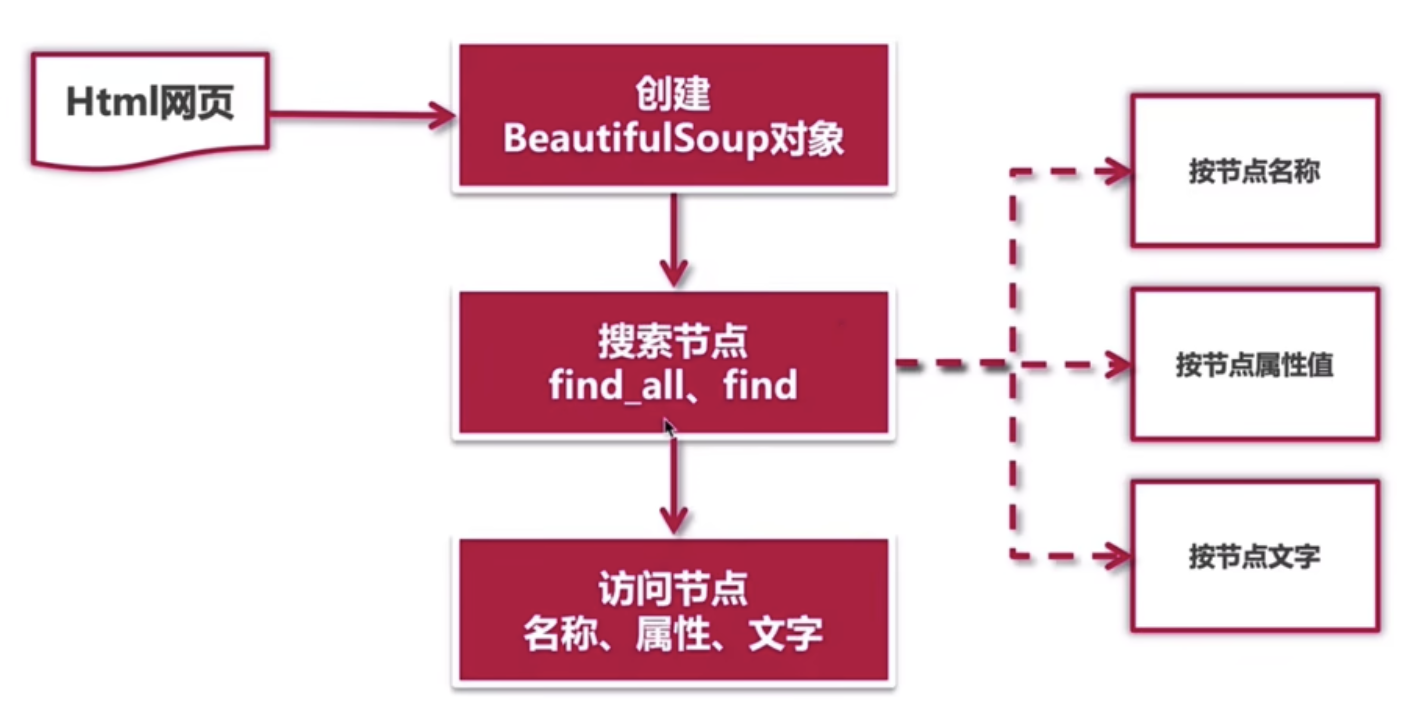
用 bs4 解析 html 时,一般都是先构建 bs4 对象,然后根据目标信息在 html 中的位置、特点等搜索对应的节点,再获取相关节点的属性信息等。
参考:
强大的 python 包系列作者的介绍及图表都很清晰易懂。推荐~
功能强大的python包(六):Requests(网络爬虫)















 5144
5144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









