









目录
一、什么是损失函数
什么是损失函数:简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失。
为什么引入损失函数:通过对比计算网络的前向传播结果和真实结果,计算出来的用于衡量两者之间差距的函数值。
二、经验风险与结构风险
经验风险
机器学习模型关于训练数据集的平均损失称为经验风险。
结构风险
结构风险是在经验风险的基础上加上表示模型复杂度的正则项(罚项)。
三、分类损失函数
| 代表算法 | 说明 | |
| 1.Hing-Loss |
| 当用于标准SVM时,损失函数表示线性分隔符与其中任一类中的最近点之间的边距长度。 只有在p = 2时处处可导。 |
| 2.Log-Loss | Logistic回归 | 机器学习中最受欢迎的损失功能之一,因为它能输出概率 |
| 3.Exponential Loss | Adaboost | 错误预测的丢失随着值的增加呈指数增长 −hw(xi)yi−hw(xi)yi |
| 4.Zero-One Loss | 实际分类损失 | 不连续,不容易优化 |
| 5 Cross Entropy Loss
| 交叉熵是用来度量两个概率分布的差异性的,用来衡量模型学习到的分布和真实分布的差异。 |

四、回归损失函数及其特点
| 1.Squared Loss | 也被称为均分误差| 二次损失 | L2损失 | 普通最小二乘法(OLS) | Mean Square Error, Quadratic Loss, L2 Loss 优点:处处可导 缺点:对异常值敏感 |
| 2.Absolut Loss | 优点:对噪音不敏感 缺点:0点不可导 |
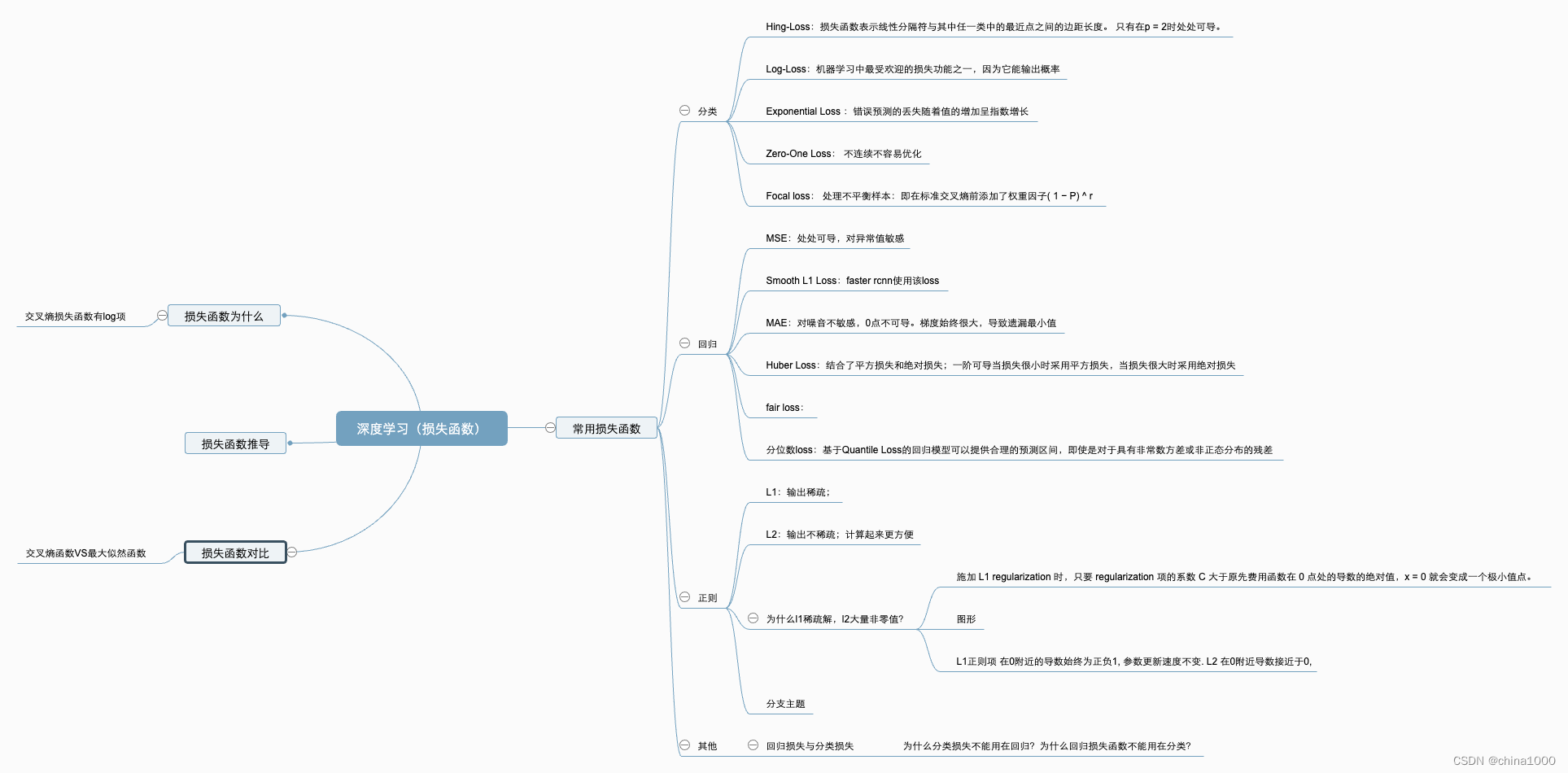
| 3 huber loss
| 平滑绝对损失 优点:结合了平方损失和绝对损失;一阶可导 当损失很小时采用平方损失(梯度小不会错过最小值),当损失很大时采用绝对损失(梯度大快速收敛) |
| 4.fair loss | |
| 5.Log-Cosh Loss
| 优点:与Huber损失类似,但处处二阶可导 缺点:对于误差很大的预测,其梯度和hessian是恒定的 |
| 6.Quantile Loss(分位数损失)
| 优点:基于Quantile Loss的回归模型可以提供合理的预测区间,即使是对于具有非常数方差或非正态分布的残差aaaa |
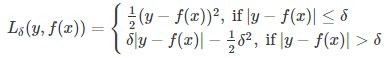
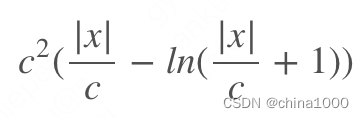
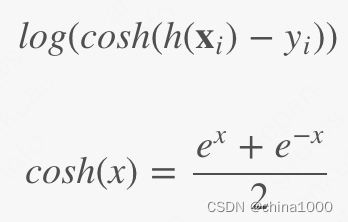
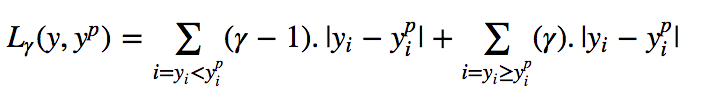
五、正则化
目的:防止过拟合、提高模型泛化能力。通过在经验风险项后加上表示模型复杂度的正则化项或惩罚项,达到选择经验风险和模型复杂度都较小的模型目的。
| L1 防止过拟合、提高模型泛化能力。 | 输出稀疏,原因: 1) 施加 L1 regularization 时,只要 regularization 项的系数 C 大于原先费用函数在 0 点处的导数的绝对值,x = 0 就会变成一个极小值点。 2) 图形 3)在0附近的导数始终为正负1, 参数更新速度不变. L2 在0附近导数接近于0, |
| L2 | 输出不稀疏;计算起来更方便 |
| dropout | 输入的特征都存在被随机清除的可能,所以该神经元不会再特别依赖于任何一个输入特征,也就是不会给任何一个输入特征设置太大的权重。通过传播过程,dropout 将产生和 L2 正则化相同的收缩权重的效果。 |
| early stop |
六、损失函数深入理解
1 分类问题可以使用MSE(均方误差)作为损失函数吗
2 MSE VS Cross Entrono
1). 从损失函数本身看:
a. 交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。MSE衡量的是预测值和目标值的欧式距离。分类问题中label的值大小在欧氏空间中是没有意义的。
例如:在一个三分类模型中,模型的输出结果为(a,b,c),而真实的输出结果为(1,0,0),那么MSE与cross-entropy相对应的损失函数的值如下:
MSE: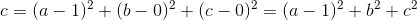
cross-entropy: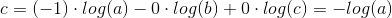
b. 交叉熵的损失函数只和分类正确的预测结果有关系,而MSE的损失函数还和错误的分类有关系。强行使用的话:除了让正确的分类尽量变大,还会让错误的分类变得平均,
2). 从优化角度看:
a. 分类问题是逻辑回归,必须有激活函数这个非线性单元在,比如sigmoid(也可以是其他非线性激活函数),此时mse有多个极值点,所以不适用做损失函数了。
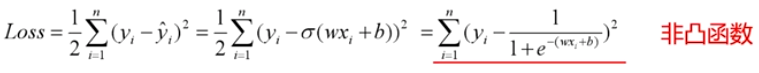
b. mse作为损失函数,求导的时候都会有对激活函数的求导连乘运算,对于sigmoid、tanh,有很大区域导数为0的。
2 softmax loss vs 交叉熵 loss
softmax是激活函数,交叉熵是损失函数,softmax loss是使用了softmax funciton的交叉熵损失。
3 为什么交叉熵损失函数有log项?
第一种:因为是公式推导出来的,比如第六题的推导,推导出来的有log项。极大似然取对数,再加上负号取最小值。
第二种:通过最大似然估计的方式求得交叉熵公式,这个时候引入log项。
这是因为似然函数(概率)是乘性的,而loss函数是加性的,所以需要引入log项“转积为和”。而且也是为了简化运算。
4 交叉熵为什么可以作为损失函数?
1) 希望学到的分布与真实分布不一致
2) 真实分布未知,假设训练数据是从真实数据独立同分布采样。
3) 极大似然取对数,再加上负号取最小值。
5 SVM损失函数
svm损失函数就是Hinge loss 加上l1 正则
6 Yolo的损失函数

7 iou计算

8 Dropout使用经验?
- 对于不同的层,设置的keep_prob大小也不一致,神经元较少的层,会设keep_prob为 1.0,而神经元多的层则会设置比较小的keep_prob
- 通常被使用在计算机视觉领域,图像拥有更多的特征,场景容易过拟合,效果被实验人员证明是很不错的。
参考文献:















 2061
2061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









