







一、加载kni内核模块
在加载kni模块时,可以设置它的内核线程模式:
insmod kmod/rte_kni.ko kthread_mode=single
insmod kmod/rte_kni.ko kthread_mode=multiple
single模式(默认):只在内核侧创建一个内核线程,来接收所有kni设备上的数据包,一个线程 vs 所有kni设备
multiple模式:每个kni接口创建一个内核线程,用来接收数据包,一个线程 vs 一个kni设备
dpdk在加载kni模块时,默认是采用的single模式,同时还可以为此内核线程设置cpu亲和性。
二、KNI用户态和内核态交互
rx_q:从kni thread角度来说,是接收。
tx_q:从kni thread角度来说,是发送。
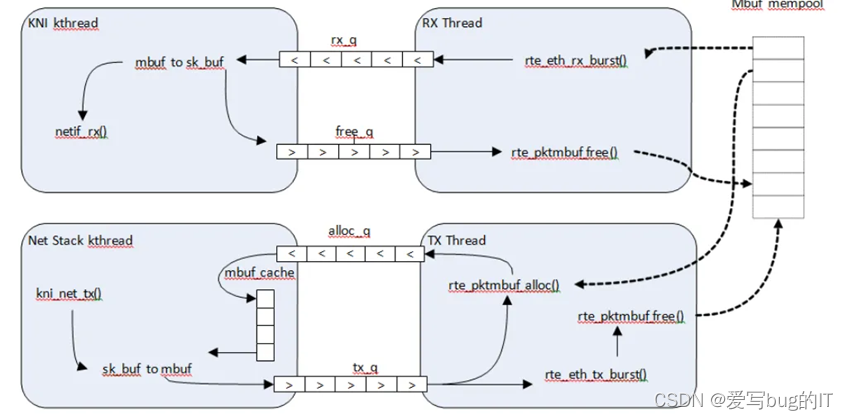
图的上半部分:
1、在 DPDK RX 端,mbuf 由 PMD 在 RX 线程上下文中分配。
2、这个线程将mbuf入队rx_q FIFO。
3、KNI线程将为rx_q轮询所有KNI活动设备。如果一个mbuf出队列,它将被转换为sk_buff结构,并通过netif_rx()函数发送到网络堆栈。
4、释放已出队的mbuf指针,并将mbuf指针归还到free_q FIFO队列。
图的下半部分:
1、调用 kni_net_tx() 回调函数,从 Linux 网络堆栈接收数据包。
2、出队mbuf(无需等待缓存),用sk_buff数据来填充mbuf结构。
DPDK TX 线程将 mbuf 从tx_q队列出列,并将其发送到 PMD(通过 rte_eth_tx_burst())。
三、内核态KNI处理
3.1 内核初始化
a、模块初始化之注册misc设备
static int __init
kni_init(void)
{
int rc;
rc = register_pernet_subsys(&kni_net_ops);
rc = misc_register(&kni_misc);
/* Configure the lo mode according to the input parameter */
kni_net_config_lo_mode(lo_mode);
return 0;
}
模块初始化函数kni_init比较简单,核心函数有两个
注册misc设备:misc_register
配置lo_mode:kni_net_config_lo_mode
通过register_pernet_subsys或者register_pernet_gen_subsys,注册了kni_net_ops,保证每个namespace都会调用kni_init_net进行初始化。
注册为misc设备后,其工作机制由注册的misc device决定,即
static const struct file_operations kni_fops = {
.owner = THIS_MODULE,
.open = kni_open,
.release = kni_release,
.unlocked_ioctl = (void *)kni_ioctl,
.compat_ioctl = (void *)kni_compat_ioctl,
};
static struct miscdevice kni_misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = KNI_DEVICE,
.fops = &kni_fops,
};
#define KNI_DEVICE "kni"
重点关注结构体变量kni_fops的kni_open,kni_release,kni_ioctl函数。
b、kni_open函数
kni_open(struct inode *inode, struct file *file)
{
struct net *net = current->nsproxy->net_ns;
struct kni_net *knet = net_generic(net, kni_net_id);
/* kni device can be opened by one user only per netns */
if (test_and_set_bit(KNI_DEV_IN_USE_BIT_NUM, &knet->device_in_use))
return -EBUSY;
file->private_data = get_net(net);
pr_debug("/dev/kni opened\n");
return 0;
}
检查保证一个namespace一个用户只能打开一个kni设备。
打开后,将基于namespace的私有数据赋值给file->private_data。
c、kni_ioctl函数
如何使用kni设备呢?内核的kni模块,提供了ioctl的支持。
static int
kni_ioctl(struct inode *inode, uint32_t ioctl_num, unsigned long ioctl_param)
{
int ret = -EINVAL;
struct net *net = current->nsproxy->net_ns;
switch (_IOC_NR(ioctl_num)) {
case _IOC_NR(RTE_KNI_IOCTL_CREATE):
ret = kni_ioctl_create(net, ioctl_num, ioctl_param);
break;
case _IOC_NR(RTE_KNI_IOCTL_RELEASE):
ret = kni_ioctl_release(net, ioctl_num, ioctl_param);
break;
}
return ret;
}
有两个有效的case,RTE_KNI_IOCTL_CREATE和RTE_KNI_IOCTL_RELEASE,分别对应DPDK用户态的rte_kni_alloc和rte_kni_release,即申请kni interface和释放kni interface。
d、rte_kni_alloc vs kni_ioctl_create 对比
在rte_kni_alloc中,关键的代码是kni_reserve_mz申请连续的物理内存,并用其作为各个ring。
e、kni_ioctl_create函数
在kni_ioctl_create函数中会创建struct kni_dev结构体变量,并给它的成员赋值。
static int
kni_ioctl_create(struct net *net, uint32_t ioctl_num,
unsigned long ioctl_param)
{
struct kni_net *knet = net_generic(net, kni_net_id);
int ret;
struct rte_kni_device_info dev_info;
struct net_device *net_dev = NULL;
struct kni_dev *kni, *dev, *n;
//申请netdev并赋值
net_dev = alloc_netdev(sizeof(struct kni_dev), dev_info.name,kni_net_init);
kni = netdev_priv(net_dev);
//将ring的物理地址转为虚拟地址
kni->tx_q = phys_to_virt(dev_info.tx_phys);
kni->rx_q = phys_to_virt(dev_info.rx_phys);
kni->alloc_q = phys_to_virt(dev_info.alloc_phys);
kni->free_q = phys_to_virt(dev_info.free_phys);
//注册netdev
ret = register_netdev(net_dev);
//启动内核接收线程
ret = kni_run_thread(knet, kni, dev_info.force_bind);
return 0;
}
- 通过phys_to_virt将ring的物理地址转成虚拟地址使用,这样就保证了KNI的用户态和内核态使用同一片物理地址,从而做到零拷贝。
- 注册netdev网络设备
- 启动内核接收线程
f、kni_run_thread函数
kni_run_thread是内核态要开启内核线程来接收所有kni设备上的数据。
static int
kni_run_thread(struct kni_net *knet, struct kni_dev *kni, uint8_t force_bind)
{
/**
* Create a new kernel thread for multiple mode, set its core affinity,
* and finally wake it up.
*/
if (multiple_kthread_on) {
//线程函数为kni_thread_multiple
kni->pthread = kthread_create(kni_thread_multiple,(void *)kni, "kni_%s", kni->name);
} else {
//加mutex锁
mutex_lock(&knet->kni_kthread_lock);
if (knet->kni_kthread == NULL) {
//创建内核线程,线程函数为kni_thread_single
knet->kni_kthread = kthread_create(kni_thread_single,
(void *)knet, "kni_single");
}
//解mutex锁
mutex_unlock(&knet->kni_kthread_lock);
}
return 0;
}
如果KNI为多线程模式,每创建一个kni设备,就创建一个内核线程。
如果KNI为单线程模式,则检查是否已经启动了kni_thread。没有的话,创建唯一的kni内核thread kni_single,有的话,则什么都不做。
g、kni_thread_single线程函数
static int
kni_thread_single(void *data)
{
struct kni_net *knet = data;
int j;
struct kni_dev *dev;
while (!kthread_should_stop()) {
down_read(&knet->kni_list_lock);
//遍历所有kni设备
for (j = 0; j < KNI_RX_LOOP_NUM; j++) {
list_for_each_entry(dev, &knet->kni_list_head, list) {
//接收动作
kni_net_rx(dev);
kni_net_poll_resp(dev);
}
}
up_read(&knet->kni_list_lock);
}
return 0;
}
在持有读锁的情况下,遍历所有的kni设备,执行接收动作kni_net_rx。
h、kni_net_rx函数如下
/* rx interface */
void
kni_net_rx(struct kni_dev *kni)
{
/**
* It doesn't need to check if it is NULL pointer,
* as it has a default value
*/
(*kni_net_rx_func)(kni);
}
ni_net_rx内部调用回调函数kni_net_rx_func
static kni_net_rx_t kni_net_rx_func = kni_net_rx_normal;
默认情况下kni_net_rx_func回调函数注册为kni_net_rx_normal
i、kni_net_rx_normal函数
kni_net_rx_normal(struct kni_dev *kni)
{
uint32_t ret;
uint32_t len;
uint32_t i, num_rx, num_fq;
struct rte_kni_mbuf *kva;
void *data_kva;
struct sk_buff *skb;
struct net_device *dev = kni->net_dev;
/* Get the number of free entries in free_q */
/*检查释放队列是否还有空位,没有的话,意味着读取后的数据无法增加到释放队列,故直接返回。*/
num_fq = kni_fifo_free_count(kni->free_q);
/* Burst dequeue from rx_q */
/* 重点!!! 从kni->rx_q中弹出元素*/
/* 重点!!! 从kni->rx_q中弹出元素*/
num_rx = kni_fifo_get(kni->rx_q, kni->pa, num_rx);
if(num_rx == 0)
return;
/* Transfer received packets to netif */
// 循环处理收到的kni数据,将数据复制到申请的skb中。
for (i = 0; i < num_rx; i++) {
kva = pa2kva(kni->pa[i]);
len = kva->pkt_len;
data_kva = kva2data_kva(kva);
kni->va[i] = pa2va(kni->pa[i], kva);
/* 从内存申请skb */
skb = dev_alloc_skb(len + 2);
/* 如果只有一个mbuf segment段,则直接拷贝,如果是多个segment段,则分批拷贝*/
if (kva->nb_segs == 1) {
memcpy(skb_put(skb, len), data_kva, len);
}
/*设置skb相关参数*/
skb->dev = dev;
skb->protocol = eth_type_trans(skb, dev);
skb->ip_summed = CHECKSUM_UNNECESSARY;
//调用netif_rx_ni将skb传给内核协议栈处理
netif_rx_ni(skb);
}
/* Burst enqueue mbufs into free_q */
/*将使用后的mbuf指针加入到kni->free_q队列中,等待用户态KNI来进行释放*/
ret = kni_fifo_put(kni->free_q, kni->va, num_rx);
}
1.检查释放队列是否还有空位,没有的话,意味着读取后的数据无法增加到释放队列,故直接返回。
2.从kni->rx_q读取数据到kni->pa中。没有任何报文,则直接返回。
3.循环处理收到的kni数据,将数据复制到申请的skb中。
4.调用netif_rx_ni将skb传给内核协议栈处理
5.将读取的数据追加到free_q队列中,将使用后的kni->va投递到kni->free_q队列中,等待用户态KNI进行释放
这是DPDK app向KNI设备写入数据,也就是发给内核的情况。
而最前面的rte_kni_handle_request是什么作用呢?
rte_kni_handle_request从kni->req_q拿到request,然后根据修改mtu或者设置接口的命令做相应的操作,最后将response放回kni->resp_q。
3.2 模块初始化之配置lo_mode
void
kni_net_config_lo_mode(char *lo_str)
{
if (!strcmp(lo_str, "lo_mode_none"))
pr_debug("loopback disabled");
else if (!strcmp(lo_str, "lo_mode_fifo")) {
pr_debug("loopback mode=lo_mode_fifo enabled");
kni_net_rx_func = kni_net_rx_lo_fifo;
} else if (!strcmp(lo_str, "lo_mode_fifo_skb")) {
pr_debug("loopback mode=lo_mode_fifo_skb enabled");
kni_net_rx_func = kni_net_rx_lo_fifo_skb;
} else {
pr_debug("Unknown loopback parameter, disabled");
}
}
配置lo_mode,函数指针kni_net_rx_func指向不同的函数,默认为kni_net_rx_normal。
如果为lo_mode_fifo模式,函数指针kni_net_rx_func设置为kni_net_rx_lo_fifo;
如果为lo_mode_fifo_skb模式,函数指针kni_net_rx_func设置为kni_net_rx_lo_fifo_skb;
3.2.1 dpdk网口 -> KNI网口方向
3.2.1.1 用户态KNI处理流程
将pkts_burst中的mbuf报文批量发送给kni接口
unsigned
rte_kni_tx_burst(struct rte_kni *kni, struct rte_mbuf **mbufs, unsigned num)
{
void *phy_mbufs[num];
unsigned int ret;
unsigned int i;
//记住这里传递的都是指向mbuf的指针
//指向mubuf的地址是虚拟地址,将虚拟地址全部转为物理地址
for (i = 0; i < num; i++)
phy_mbufs[i] = va2pa(mbufs[i]);
//将物理地址投递到kni->rx_q队列上
ret = kni_fifo_put(kni->rx_q, phy_mbufs, num);
/* Get mbufs from free_q and then free them */
kni_free_mbufs(kni);
return ret;
}
static void
kni_free_mbufs(struct rte_kni *kni)
{
int i, ret;
struct rte_mbuf *pkts[MAX_MBUF_BURST_NUM];
ret = kni_fifo_get(kni->free_q, (void **)pkts, MAX_MBUF_BURST_NUM);
if (likely(ret > 0)) {
for (i = 0; i < ret; i++)
rte_pktmbuf_free(pkts[i]);
}
}
准备rte_mbuf的指针数组pkts,然后调用kni_free_mbufs函数从kni->free_q队列上获取要释放的元素,保存到pkts中。然后调用rte_pktmbuf_free函数进行释放内存资源
用户态KNI做了两件事:
1.将mbuf投递到kni->rx_q接收队列上
2.批量从kni->free_q队列上取元素,将内存归还给内存池
3.2.1.2 内核态KNI处理流程
前文已将数据mbuf投递到kni->rx_q队列中,那么谁来读取kni->rx_q队列上的数据写入内核网络协议栈上呢?
带着上述的疑问,我们来探寻下内核态的KNI处理流程
3.2.2 KNI网口方向 -> dpdk网口
3.2.2.1 从kni->tx_q队列读数据
kni_egress函数中调用rte_kni_rx_burst从KNI网口中批量读取数据包,然后调用rte_eth_tx_burst批量发送给dpdk网口。
unsigned
rte_kni_rx_burst(struct rte_kni *kni, struct rte_mbuf **mbufs, unsigned num)
{
unsigned ret = kni_fifo_get(kni->tx_q, (void **)mbufs, num);
/* If buffers removed, allocate mbufs and then put them into alloc_q */
if (ret)
kni_allocate_mbufs(kni);
return ret;
}
从kni->tx_q队列取元素存至mbufs指向的数组中,如果buffer已经删除,则调用kni_allocate_mbufs申请mbufs,然后添加到alloc_q队列。
static void
kni_allocate_mbufs(struct rte_kni *kni)
{
int i, ret;
struct rte_mbuf *pkts[MAX_MBUF_BURST_NUM];
void *phys[MAX_MBUF_BURST_NUM];
int allocq_free;
//判断kni->alloc_q队列上还需要申请多少内存资源
allocq_free = (kni->alloc_q->read - kni->alloc_q->write - 1) \
& (MAX_MBUF_BURST_NUM - 1);
for (i = 0; i < allocq_free; i++) {
/*从内存池申请内存资源*/
pkts[i] = rte_pktmbuf_alloc(kni->pktmbuf_pool);
//申请到的内存是虚拟地址,将其转换为物理地址,内核才能进行操作
phys[i] = va2pa(pkts[i]);
}
//将申请的内存投递到kni->alloc_q队列中
ret = kni_fifo_put(kni->alloc_q, phys, i);
/* Check if any mbufs not put into alloc_q, and then free them */
if (ret >= 0 && ret < i && ret < MAX_MBUF_BURST_NUM) {
int j;
for (j = ret; j < i; j++)
rte_pktmbuf_free(pkts[j]);
}
}
上面rte_kni_rx_burst函数中kni_fifo_get(kni->tx_q, (void **)mbufs, num);
kni_fifo_get函数是从kni->tx_q队列取数据,那么谁往kni->tx_q队列投递数据呢?
3.2.2.2 向kni->tx_q队列写数据
当内核向kni设备发送数据时,最终会调用到net_device_ops->ndo_start_xmit。
net_device_ops结构体的ndo_start_xmit回调函数注册为kni_net_tx(位于kernel/linux/kni/kni_net.c)
static int
kni_net_tx(struct sk_buff *skb, struct net_device *dev)
{
/* Check if the length of skb is less than mbuf size */
//对skb报文做长度检查,不能超过mbuf的大小
if (skb->len > kni->mbuf_size)
goto drop;
//检测tx_q队列中是否有空闲位置
//检测alloc_q队列有否有剩余的mbuf
if (kni_fifo_free_count(kni->tx_q) == 0 ||
kni_fifo_count(kni->alloc_q) == 0) {
/**
* If no free entry in tx_q or no entry in alloc_q,
* drops skb and goes out.
*/
goto drop;
}
/* dequeue a mbuf from alloc_q */
/* 从alloc_q队列取出一块内存*/
ret = kni_fifo_get(kni->alloc_q, &pkt_pa, 1);
if (likely(ret == 1)) {
void *data_kva;
//将pkt_pa转化为虚拟地址
pkt_kva = pa2kva(pkt_pa);
data_kva = kva2data_kva(pkt_kva);
pkt_va = pa2va(pkt_pa, pkt_kva);
/*skb -> mbuf 将skb的值赋值过去*/
len = skb->len;
memcpy(data_kva, skb->data, len);
if (unlikely(len < ETH_ZLEN)) {
memset(data_kva + len, 0, ETH_ZLEN - len);
len = ETH_ZLEN;
}
pkt_kva->pkt_len = len;
pkt_kva->data_len = len;
/* 将pkt_va追加到发送队列 tx_q */
ret = kni_fifo_put(kni->tx_q, &pkt_va, 1);
if (unlikely(ret != 1)) {
/* Failing should not happen */
pr_err("Fail to enqueue mbuf into tx_q\n");
goto drop;
}
} else {
/* Failing should not happen */
pr_err("Fail to dequeue mbuf from alloc_q\n");
goto drop;
}
/* 释放skb并更新计数 */
dev_kfree_skb(skb);
kni->stats.tx_bytes += len;
kni->stats.tx_packets++;
return NETDEV_TX_OK;
drop:
/* Free skb and update statistics */
dev_kfree_skb(skb);
kni->stats.tx_dropped++;
return NETDEV_TX_OK;
}
四、tun虚拟网卡拓展
除了kni外,还有一种方式,也可以将报文发给内核协议栈,那就是tun虚拟网卡方式。这其实和kni操作是差不多的。dpdk提供了exception_path例子来介绍tun的使用。首先应用层打开/dev/net/tun设备,然后通过往这个/dev/net/tun设备发送ioctl消息, 内核接收到ioctl消息后创建虚拟网卡。这和kni设备的创建是不是很相似,kni设备是通过往/dev/kni混合设备发ioctl消息来创建kni设备的。在创建完虚拟网卡后,也可以和kni设备执行类似的操作。例如ifconfig配置tun虚拟网卡ip, ethtool设置虚拟网卡信息,tcpdump抓包等。
kni作为用户态和内核的接口,没有系统调用和内存拷贝,dpdk通过大页内存实现的fifo,从而实现零拷贝,因此比传统的tun/tap设备性能更好,而tun需要通过write系统调用,同时从应用层拷贝要发送的数据到内核。
kni混合设备只实现了open和ioctl接口,没有实现read/write接口,因此不能像tun/tap设备一样使用读写文件的方式进行数据收发。
要使用tun虚拟网卡功能,大体上就下面三个调用操作就行了。
//读写方式打开tun设备
int tap_fd = open("/dev/net/tun", O_RDWR);
ifr.ifr_flags = IFF_TAP | IFF_NO_PI;
snprintf(ifr.ifr_name, IFNAMSIZ, "%s", name);
ret = ioctl(tap_fd, TUNSETIFF, (void *) &ifr);
//通过tun,将报文发往内核
ret = write(tap_fd, rte_pktmbuf_mtod(m, void*), rte_pktmbuf_data_len(m));
//通过tun接口,从内核接收报文
ret = read(tap_fd, rte_pktmbuf_mtod(m, void *), MAX_PACKET_SZ);















 229
229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









