






python基本数据类型【详解】
python的数据类型分为6大类:
不可变数据(3 个):Number(数值)、String(字符串)、Tuple(元组);
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
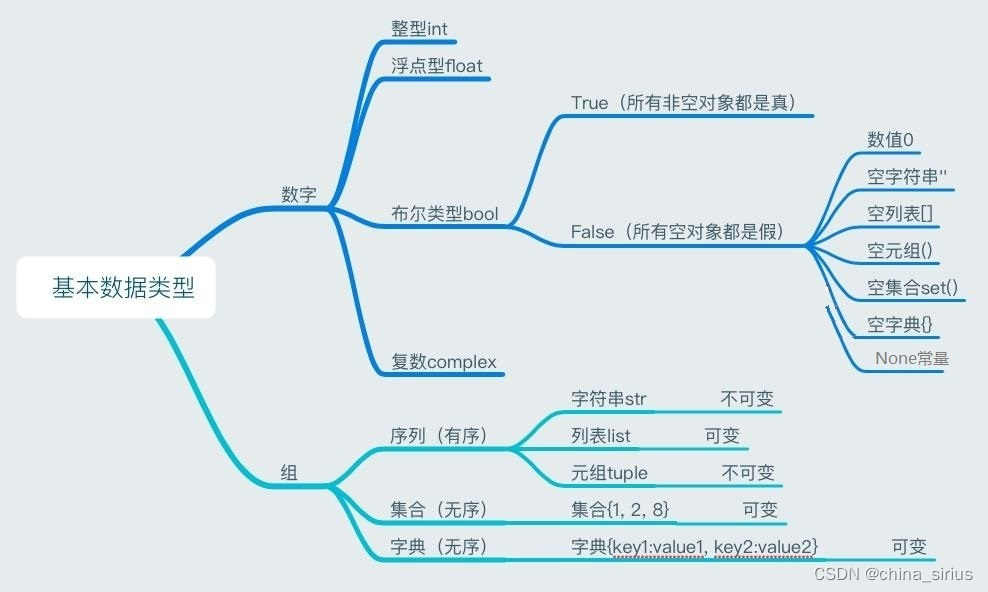
Number(数值)
数字数据类型,如果改变Number类型的值、将重新分配内存空间。
int
整型,是正或负整数,不带小数点。Python3 整型是没有限制大小。
float
浮点型,由整数部分与小数部分组成,浮点类型不精确存储,可用科学计数法表示(2.5e2 = 2.5 x 102 = 250)。
bool
布尔型,true的整型值是1,false的整型值是0。a = True + 1的值为2。
complex(复数)
复数类型,复数由实部(real)和虚部(imag)构成。
String(字符串)
字符串类型可以使用单引号、双引号、三个单引号和三个双引号,其中三引号可以多行定义字符串,Python 不支持单字符类型,单字符也在Python也是作为一个字符串使用。
字符串定义
# 字符串定义
s1 = 'Python'
s2 = "Python"
s3 = '''Python'''
s4 = """Python"""
s5 = ['你', '好', '中', '国'] # 字符串数组
字符串切片
字符串索引index取值范围:-len()到len()-1,越界会报错
s[0], s[-1], s[3:], s[::-1]
字符串替换
还可以使用正则表达式替换
s.replace('Python', 'Hello')
字符串查找
find()、index()、rfind()、rindex()
s1.find('P') # 返回1, 返回第一次出现子串的下标
s2.find('h', 2) # 返回4, 设定下标2开始查找
s3.find('Hello') # 返回-1, 查找不到则返回-1
s4.index('h') # 返回4, 返回第一次出现的子串的下标
s5.index('Hello') # 不同与find(), 查找不到会抛出异常
字符串转大小写
upper()、lower()、swapcase()、capitalize()、istitle()、isupper()、islower()
s.upper() # 'PYTHON'
s.swapcase() # 'pYTHON', 大小写反转
s.istitle() # True,检查字符串是否符合标题文本格式,即每个单词首字母大写、其余字母都小写或不是字母
s.title() # 方法用于将字符串中的每个单词的首字母转换为大写字母,同时将其余字母转换为小写字母。
s.islower() # False
字符串去空格
s.strip() # 去掉这个字符串两头的-、*、\n、#以及空格
s.strip("#") # 去掉这个字符串两头的指定的多个#
s.strip("#*") # 去掉这个字符串两头的指定的多个#、*
s.lstrip() # 去掉字符串左边的空格或指定字符
s.rstrip() # 去掉字符串右边的空格或指定字符
字符串格式化
推荐使用format格式化字符串
s = '%s %s' % ('我的年龄是:', 21)
s = '{}, {}'.format("我的年龄是:", '21')
s = '{0}, {1}, {0}'.format('好', '不')
s = '{name}: {age}'.format(age=21, name='张三')
字符串连接与分割
使用 + 连接字符串,每次操作会重新计算、开辟、释放内存,效率很低,所以推荐使用join
s1 = '你'.join('好') # '你好'
s2 = 'a-b-c'.split('-') # ['a', 'b', 'c']
List(列表)
列表是一组元素可以重复、元素可以修改、无数据类型限制、有序的元素集,列表的元素都写在中括号[]里、元素之间用逗号隔开。
列表中的元素,下标索引从 0 开始,可以对列表进行截取,组合等操作。
列表定义
list1 = ["a", "b", "c", "d"]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", 1,2,3]
list1.index("b") # 搜索
list1.append("e") # 添加元素
list1.remove("e") # 删除元素
列表的操作
list1 = ["a", "B", "c", "d"]
list1[1] = "b" # 单个元素赋值,list1中的元素变为['a', 'b', 'c', 'd']
del list1[3] # 删除元素,list1中的元素变为['a', 'b', 'c']
列表的截取(切片)
切片: 变量的名字[start: end: step]
- start的默认值是按照step方向上的第一个元素
- end的默认值是按照step的方向上的最后一个元素
- step的默认值是1
list1 = ["a", "b", "c", "d"]
list1[0:3] # 返回["a", "b", "c"],表示从索引0开始、直到索引3止,但不包括索引3
list1[:3] # 返回["a", "b", "c"],表示从索引0开始、直到索引3止,但不包括索引3,如果第一个索引是0、可以省略
list1[1:3] # 返回["b", "c"]
list1[-3:-1] # 返回["b", "c", "d"],表示取包括索引-3到-1,-1表示列表最后一个元素
list1[-3:] # 返回["b", "c", "d"],表示取包括索引-3到-1,-1表示列表最后一个元素,如果第二个索引是-1、可以省略
# 切片赋值
list1 = list('englihs')
list1[4:]='sh' # 改变list1中的最后两个值,list1的值为['e', 'n', 'g', 'l', 'i', 's', 'h']
# 切片替换
list1 = list('HELLO') # list1的值为['H', 'E', 'L', 'L', 'O']
list1[1:] = list('ello.') # 从索引1替换到最后,list1的值为['H', 'e', 'l', 'l', 'o', '.']
# 切片插入
list1 = ["a", "b", "c", "d"]
list1[1:1] = [2, 3] # 在索引1后插入新元素,list1中的元素变为['a', 'b', 1, 2, 'c', 'd']
# 切片删除
list1 = ['a', 'b', 1, 2, 'c', 'd']
list1[1:3] = [] # 删除索引1到索引3的元素,list1中的元素变为['a', 'b', 'c', 'd']
# 切片的负索引操作
list1 = ["a", "b", "c", "d"]
list1[-1:-1] = [ 1, 2, 3] # list1中的元素变为['a', 'b', 'c', 1, 2, 3, 'd']
list2 = ["a", "b", "c", "d"]
list1[-2:-1] = [ 1, 2, 3] # list1中的元素变为['a', 'b', 1, 2, 3, 'd']
列表的遍历
list1 = ["a", "b", "c", "d"]
for s in list1:
print(i)
for index in range(0,3):
print(list[index])
列表的方法
# append:用于在列表的末尾追加新的内容
# pop和append方法是Python中数据结构的出栈和入栈
list1 = ['a', 'b', 1, 2]
list1.append(3) # list1中的元素变为['a', 'b', 1, 2, 3]
# extend:表示在列表的末尾追加元素集合(不同于append的添加单个元素)
list2 = [4, 5]
list1.extend(list2) # list1中的元素变为['a', 'b', 1, 2, 3, 4, 5]
# insert:向列表中插入元素
list1.insert(3, 'c') # list1中的元素变为['a', 'b', 'c', 1, 2, 3, 4, 5]
# pop:移除列表中的一个元素(默认是最后一个),并且返回该元素的值
# pop和append方法是Python中数据结构的出栈和入栈
# pop方法是唯一既能修改列表又能返回元素值的方法(除了None)
list1.pop(3, 'c')
# remove:移除列表中第一个匹配的元素
list1.remove(1) # list1中的元素变为['a', 'b', 2, 3, 4, 5]
# count:统计某个元素在列表中出现的次数
list1.count(5) # 输出1,5出现了1次
# index:检索列表中某个元素第一次匹配的索引位置
list1.index('b') # 返回1
# reverse:将列表中的元素进行反转操作
list1.reverse() # list1中的元素变为['a', 'b', 2, 3, 4, 5]
# sort:用于将列表元素排序
list1 = [2, 5, 3, 6, 1, 7, 4]
list1.sort() # list1中的元素变为[1, 2, 3, 4, 5, 6, 7]
# clear:清空列表所有元素
# copy:复制列表
list1 = ['a', 'b', 'c']
list2 = list1.copy() # list2中的元素为['a', 'b', 'c']
可以应用于列表的内置函数
list 函数
如对字符串赋值后想要改变字符串中的某个值,可以利用 list 函数(list 函数适用于所有类型的序列),如下:
s = list('hello') # s = ['h', 'e', 'l', 'l', 'o']
s[0] = "H"
print (s) # ['H', 'e', 'l', 'l', 'o']
len函数
len 函数返回集合中的元素个数
list1 = ['a', 'b', 1, 2]
len(list1)
4
max函数、min函数
max函数返回集合中元素最大值,min函数返回集合中元素最小值
list1 = [1, 6, 5, 10, 9, 8]
max(list1)
10
min(list1)
1
sorted函数(排序函数)
sorted() 函数对所有可迭代的对象进行排序操作。
list1 = [1, 3, 2, 5, 4]
print(sorted(list1)) # 临时排序,输出[1, 2, 3, 4, 5],默认升序
print(sorted(list1, reverse=True)) # 临时排序,输出[5, 4, 3, 2, 1],reverse=True实现降序排序
print(list1) # 原序输出,输出[1, 3, 2, 5, 4]
list2 = [ ('c',3), ('b',2), ('a',1), ('d',4)]
print(sorted(list2, cmp = lambda x, y: cmp(x[1], y[1]))) # 利用cmp函数协助排序,输出[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
print(sorted(list2, key = lambda x:x[1])) # 利用key协助排序,输出[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
Tuple(元组)
元组是一组元素可以重复、元素不能修改、无数据类型限制、有序的集合,元组的元素都写在小括号 () 里、元素之间用逗号隔开。
元组与字符串类似,下标索引从 0 开始,可以对元组进行截取,组合等操作。
创建元组
# 创建元组
t1 = () # 空元组
t2 = ('a','b','c','d','e','f','g')
t3 = ('张三', '李四', 100, 100);
# 删除元组
del t1, t2 # 删除后再引用报错:name 't1' is not defined
# 查看元组类型
>>> type(t1)
<class 'tuple'>
t4 = (100) # 元组中只含一个元素时,需要在元素后面添加逗号,否则()会被当作运算符使用
>>> type(44)
<class 'int'>
t4 = (100,) # 元组中只含一个元素时,需要在元素后面添加逗号,否则()会被当作运算符使用
>>> type(44)
<class 'tuple'>
访问元组,通过下标索引进行访问操作
t1 = (1, 2, 3, 4, 5, a, b)
t2 = (6, 7, 8, 9, 10, a, b)
t1[1:4] # 返回(2, 3, 4)
t1[0] = 0 # 报错,元组元素不能被修改
t3 = t1 + t2 # t3 = (1, 2, 3, 4, 5, a, b, 6, 7, 8, 9, 10, a, b) 元素可以重复
元组运算符
t1 = (1, 2, 3)
t2 = (4, 5, 6)
len(t1) # 返回2,表示元组元素个数,即元组长度
t3 = t1 + t2 # 元组之间连接,t3 = (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
(t1, ) * 3 # 复制元组,返回(1, 2, 3, 1, 2, 3, 1, 2, 3)
t3[1:] # (2, 3, 4, 5, 6, 7, 8, 9, 10)
t3[:2] # (1, 2)
t3[-1] # 10
t3[-2] # 9
元组内置函数
#计算元组元素个数。
len(tuple)
#返回元组中元素最大值。
max(tuple)
#返回元组中元素最小值。
min(tuple)
#将列表转换为元组。
tuple(list)
Set(集合、容器)
set集合是由一个无序不重复元素的序列,使用大括号 {} 或 set() 函数创建(创建空set集合不能用 {} , {} 是创建空字典)。
set集合可以用来成员检测、消除重复元素。
set集合支持像并集、交集、差集、对称差分等数学运算。
set集合不能被切片也不能被索引,除了做集合运算之外,集合元素可以被添加还有删除。
set集合定义
# set集合定义
set1 = {'a', 'b', 'a', 'b'}
set1 # 输出{'a', 'b'},结果实现自动去重
# 添加
set1.add('e')
print(set1) # 输出 {'a', 'b', 'a', 'b', 'e'}
# 删除
set1.discard('e')
print(set1) # 输出 {'a', 'b', 'a', 'b'}
# 去除重复元素
list1 = ['a', 'b', 'a', 'b']
print(set(list1)) # 输出{a', 'b'}
Set集合的基本操作
set1 = {'a', 'b', 'a', 'b'}
# 添加单个元素
set1.add('e') # set1中的元素为 {'a', 'b', 'e'},如果'e'已经存在、则不会添加
# 添加元素(参数可以是列表,元组,字典等)
set1.update({'c', 'd'}) # set1中的元素为 {'a', 'b', 'c', 'd'}
set1.update(['c', 'd']) # set1中的元素为 {'a', 'b', 'c', 'd'}
set1.update(['c', 'd'], ['e', 'f' ,'g']) # set1中的元素为 {'a', 'b', 'c', 'd', 'f', 'g'}
# 删除一个元素g
set1.remove('g') # remove方法:如果g不存在,则会报错
set1.discard('g') # discard方法:如果g不存在,不会报错
set1.pop() # pop方吱:随机删除一个元素
# 集合长度
len(set1)
# 清空集合
set1.clear()
# 判断元素是否存在
'g' in set1 # 返回TRUE或FALSE
集合之间的运算
集合之间的运算符分别是‘-’、‘|’、‘&’、‘^’:
- ‘-’:代表前者中包含后者中不包含的元素
- ‘|’:代表两者中全部元素聚在一起去重后的结果
- ‘&’:两者中都包含的元素
- ‘^’:不同时包含于两个集合中的元素
集合推导式
a = {x for x in '1234567890' if x not in '02468'} # a的结果为{'1', '3', '5', '7', '9'}
集合内置方法
- difference()
用于返回集合间的差集,返回一个新集合。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
tmp = a.difference(b) # 两个集合的差集返回一个集合,元素包含在集合a中,但不在集合b中
print(tmp) # tmp = {'a', 'b'}
print(a) # a = {'a', 'b', 'c', 'd'}
- difference_update()
移除两个集合中都存在的元素。
difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
a.difference_update(b) # a集合中留存差集元素
print(a) # a = {'a', 'b'}
- intersection()
用于返回两个或更多集合中都包含的元素,即交集,返回一个新集合。set.intersection(set1, set2 … etc),set1参数必填,多个参数表示大家的交集。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
c = {'c', 'd', 'e'}
tmp = a.intersection(b, c)
print(tmp) # tmp = {'c', 'd'}
- intersection_update()
用于获取两个或更多集合中都重叠的元素,即计算交集。
intersection_update() 方法不同于 intersection() 方法,因为 intersection() 方法是返回一个新的集合,而 intersection_update() 方法是在原始的集合上移除不重叠的元素。
intersection_update() 方法语法:set.intersection_update(set1, set2, set3…),set1必填
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
c = {'c', 'd', 'e'}
a.intersection_update(b, c) # a集合中留存交集元素
print(a) # {'c', 'd'}
- union()
方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次,返回值返回一个新集合。
union() 方法语法:set.union(set1, set2…),参数set1必填
#参数set1 – 必需,合并的目标集合
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
c = {'e', 'f', 'g'}
tmp = a.union(b, c)
print(tmp) # {'a', 'b', 'c', 'd', 'e', 'f', 'g'}
- isdisjoint()
用于判断两个集合是否包含相同的元素, 如果没有返回 True,否则返回 False。
isdisjoint() 方法语法:set.isdisjoint(set)
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
tmp = a.isdisjoint(b)
print(tmp) # True
- issubset()
用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd'}
tmp = b.issubset(a) # b是否为a的子集,这里的写法要注意
print(tmp) # True
- issuperset()
用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd'}
tmp = a.issuperset(b) # a是否全部包含b
print(tmp) # True
- symmetric_difference()
返回两个集合中不重复的元素集合,即会移除两个集合中都存在的元素,结果返回一个新集合。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
tmp = a.symmetric_difference(b)
print(tmp) # {'a', 'b', 'e', 'f'}
- symmetric_difference_update()
移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
a = {'a', 'b', 'c', 'd'}
b = {'c', 'd', 'e', 'f'}
a.symmetric_difference_update(b) # 不创建新集合,而是修改a集合
print(a) # {'a', 'b', 'e', 'f'}
Dictionary(字典)
字典是一种元素为key-value映射类型(即键值对映射,其它变成语言中的Map集合)。
字典的key(键)必须为不可变类型,且不能重复,如果键重复、则最后的一个键值对会替换前面的键值对。
值可以取任何数据类型。键必须是不可变的,如字符串,数字或元组等,用列表就不行。
字典是不排序的,所以不能像列表那样切片。如果访问字典中不存在的键,将导致 KeyError 出错信息。
创建空字典使用 {} 。
字典的定义
books = {} # 创建空字典
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
students = { 'student1': 'shangsan', 'student1': 'lisi', 'student1': 'wangwu' } # 创建字典
print (students['student1']) # 输出键为 'student1' 的值
print (students.keys()) # 输出字典的所有键
print (students.values()) # 输出字典的所有值
print (len(students)) # 输出字典的长度
字典的遍历
students = { 'student1': 'shangsan', 'student1': 'lisi', 'student1': 'wangwu' } # 创建字典
for k,v in students.items():
print(k,v)
访问字典数据
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
print(classes['class1'])
print(classes[3])
操作字典
- 添加和更新字典数据
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
classes['class1'] = 'class1'
print(classes['class1']) # 输出'class1'
- 删除字典、删除字典元素
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
del classes['class1'] # 删除元素'class1'
del classes # 删除字典classes
可以应用于字典的内置函数
- len()
计算字典元素个数(键的总个数)
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
len(classes) # 输出4
- str()
输出字典中可以打印的字符串标识。
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
str(classes) # "{'class1': '1', 'class2': '2', 3: '3', ('a', 'b'): (1, 2)}"
- type()
判断数据类型,如果是字典则返回字典类型
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
type(classes) # <class 'dict'>
字典的函数
- dict.clear()
删除字典内所有元素,clear() 方法没有任何返回值
classes = {'class1': '1', 'class2': '2', 3:'3', ('a', 'b'): (1, 2)}
dict.clear()
len(classes) # 输出0
- dict.copy()
对字典进行复制,分为浅拷贝与深拷贝。
person = {'p1': 'p1', 'p2': 'p2'}
person1 = person.copy() # 这里深拷贝(person1的值和person值,分别指向不同的内存区域)
person2 = person # 这里浅拷贝(person2和person的值,都指向同一块内存区域)
- dict.fromkeys()
创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值,该方法返回一个新字典。
fromkeys() 方法语法:dict.fromkeys(seq[, value]), 参数seq:字典键值列表,value:可选参数、设置键序列(seq)对应的值,默认为 None。
seq = ('zhangsan', 'lisi', 'wangwu') # 创建元组
dict1 = dict.fromkeys(seq) # 将元组的值作为字典的key
print(str(dict1)) # 输出:{'zhangsan': None, 'lisi': None, 'wangwu': None}
dict1 = dict.fromkeys(seq, 20) # 将元组的值作为字典的key,给字典的value赋值20
print(str(dict1)) # 输出:{'zhangsan': 20, 'lisi': 20, 'wangwu': 20}
dict1 = dict.fromkeys(seq, ("class1", 19, "语文")) # 将元组的值作为字典的key,给字典的value赋一个元组
print(str(dict1)) # 输出:{'zhangsan': ('class1', 19, '语文'), 'lisi': ('class1', 19, '语文'), 'wangwu': ('class1', 19, '语文')}
- dict.get()
返回指定键的值,如果值不在字典中返回default值。 - key in dict
键在字典dict里返回true,否则返回false。 - dict.items()
以列表返回可遍历的(键, 值) 元组数组。
person = {'p1': 'p1', 'p2': 'p2'}
print(person.items()) # 输出:dict_items([('p1', 'p1'), ('p2', 'p2')])
for key,values in person.items():
print(key + ': ' + values)
- dict.keys()
返回一个迭代器,可以使用 list() 来转换为列表
person = {'p1': 'p1', 'p2': 'p2'}
print(person.keys()) # 输出:dict_keys(['p1', 'p2'])
print(list(person.keys())) # 输出:['p1', 'p2']
- dict.setdefault()
setdefault()方法和get()方法类似,如果key存在、则返回对应的值,如果不存在、则插入key并返回默认值default、默认值default没有指定时为None。
setdefault()方法语法:dict.setdefault(key, default=None),参数key:必填、查找的键值,default: 键不存在时设置的默认键值。
person = {'p1': 'p1', 'p2': 'p2'}
print(person.setdefault('p2', '新值')) # 输出:'p2'
print(person.setdefault('p3', '新值')) # 输出:'新值'
print(person.setdefault('p4', None)) # 输出:None
print(person.setdefault('p4', '新值')) # 输出:None,上一步中键为'p4'的元素已经存在
- dict.update(dict2)
函数把参数字典的 key/value(键/值) 对更新到字典dict里,重复的key会覆盖掉。
person1 = {'p1': 'p1', 'p2': 'p2'}
person2 = {'p2': '新p2', 'p3': 'p3'}
person1.update(person2) # 输出:{'p1': 'p1', 'p2': '新p2', 'p3': 'p3'}
- dict.values()
返回一个迭代器,可以使用 list() 来转换为列表,列表为字典中的所有值。
person = {'p1': 'p1', 'p2': 'p2'}
print(list(person.values())) # 输出:['p1', 'p2']
- dict.pop(key[,default])
删除键key所对应的元素,返回值为被删除的值。key值必须给出。否则,返回default值。
pop()方法语法:pop(key[,default]),参数key:必填、要删除的key,default:如果没有 key、则返回 default 值。
person = {'p1': 'p1', 'p2': 'p2'}
print(person.pop('p1', 'ok')) # 输出:p1
print(person.pop('p1', 'ok')) # 输出:ok
- dict.popitem()
从字典中“弹出”一个键值对,按照 LIFO(Last In First Out 后进先出法)顺序规则,将最末尾的键值对“弹出”。
返回“弹出”的键值对。
如果字典已经为空,却调用了此方法,就报出KeyError异常。
person = {'p1': 'p1', 'p2': 'p2', 'p3': 'p3', 'p4': 'p4'}
print(person.popitem()) # 输出:{'p4': 'p4'}
print(person) # 输出:{'p1': 'p1', 'p2': 'p2', 'p3': 'p3'}
print(person.popitem()) # 输出:{'p3': 'p3'}
print(person) # 输出:{'p1': 'p1', 'p2': 'p2'}















 62
62











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









