







本文档适合基本了解数字图像处理的初学者,仅用于研究交流,由于资料来源较多,只能尽量在相关章节注明出处。
转载本文请注明出处http://blog.csdn.net/chinadragon76/article/details/22408727。
希望达到的目的:
- 为查阅或正确理解ISO/IEC 14496-10标准文档做必要的引导和铺垫;
- 对编码数据复用技术(本文Annex A)有初步了解;
- 对码率控制(本文8小节)及错误隐藏(本文9小节)有基本了解。
1. 视频压缩的必要性
- 使得在不能支持原始非压缩视频传输和存储的环境下能够使用数字视频。
例如,当前Internet的吞吐速率难以实时处理没有压缩的视频(即使在很低的视频帧率和很小的视频空间分辨率的情况下),一张1.36GB容量的DVD仅能存储不到1分钟相当于电视质量分辨率和帧率的原始视频(216Mbits/s)
- 视频压缩使得人们能够更有效地使用传输和存储资源。
如果存在一个高效率的通道,则传输高分辨率的压缩视频或者多个压缩视频要比传输单独一个底分辨率的未压缩的视频更具吸引力。虽然存储和传输容量不断提高,但在未来很长时间里,压缩仍然是多媒体服务的核心内容。
2.H.264视频压缩标准特点
追朔到20世纪90年代,自视频编码标准发布以来,不论是国际标准化组织ISO的MPEG-*系列标准还是国际电信联盟ITU-T的H.26x系列标准,其编码的基本原理都是相同的,都是用空域预测去掉空间冗余、时域预测去掉时域冗余,最后采取熵编码使得可以用最少的比特数来表示码流(参考本文3.2.1小节,编码概念图)。所不同的是,各种标准采用的具体算法和实现各不相同。
相比于先前的视频压缩标准,H.264引入了很多先进的技术,包括4×4整数变换、空域内的帧内预测、1/4象素精度的运动估计、多参考帧、多种小块的帧间预测、去除块效应的环路滤波、灵活的slice大小、基于上下文的自适应变长编码CAVLC(Context-based Adaptive Variable Length Coding)和基于上下文的自适应二进制算术编码CABAC (Context-based Adaptive Binary Arithmetic Coding)等。
进一步可参考维基百科相关描述: http://zh.wikipedia.org/wiki/MPEG-4_Part_10
3.原理
3.1 JPEG压缩原理
RGB图像(源)经伽马校正和缩减取样(Downsampling)分解为YUV区域后,对各区域分别进行平移和DCT转换分离出高频和低频区域,接着对DC/AC系数进行量化(Quantization, 一种低通滤波,是主要的有损运算,量化矩阵的获取来自实验得出的经验值,好的图形图像处理软件有多种各个环境的经验值)过滤区域的高频部分,经熵编码输出最终压缩数据。
ref: http://www.w3.org/Graphics/JPEG/itu-t81.pdf http://zh.wikipedia.org/zh-cn/JPEG
3.2 DPCM/DCT混合编/解码器
DPCM - Differential Pulse Code Modulation
3.2.1 一些基本概念
1.预测编码:经过压缩编码后传输的并不是像素本身的取样值,而是该取样的预测值和实际值之差。
2.编码概念图:
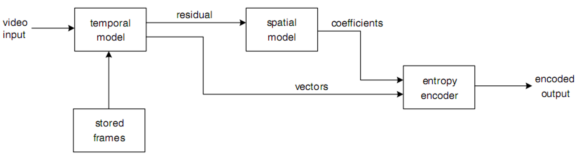
可扩展阅读《H.264 And MPEG-4 Video Compression》chapter 3. by Iain E. Richardson.《THE H.264 ADVANCED VIDEO COMPRESSION STANDARD, 2nd Edition》chapter 3.6, by Iain E. Richardson.
3.块效应产生原因与消除算法:主要原因是对基于块的帧内和帧间预测残差的DCT变换系数进行量化的过程相对粗糙,解码时IDCT恢复AC/DC变换系数带有误差,造成图像块边界上视觉不连续;另一个次要原因来自于运动补偿预测。
近年出现的块效应消除算法主要分两类:一类是彻底改变原有编码模式,不采用分块处理方法,例如基于纹理的编码,小波变换编码(high profile)等,另一类是在现有分块压缩编码基础上进行优化和扩展,多采用后处理方式进行图像恢复和增强,例如基于图像恢复的凸集投影法(POCS)和最大后验概率法(MAP)等,基于图像增强的空域滤波和DCT变换域滤波等。(扩展阅读: 论文《DCT图像压缩方法的改进及其应用》,丛爽等著。)
3.2.1 编码器
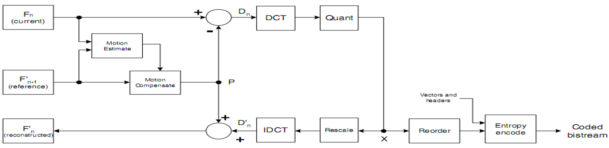
编码器有两条主要的数据流路径:左->右(编码)、右->左(重建)。编码数据流如下:
1.以宏块(16×16亮度区域和相应的色度区域)为单位,对输入视频第n帧Fn进行编码;
2.运动估计函数从参考帧(如上一次重建帧F或子采样后的F)中寻找当前宏块的匹配(相似)区域,该区域和当前宏块的位置偏移即为运动矢量MV;
3.根据MV生成运动补偿的预测P(16×16区域);
4.用当前宏块减去P生成当前帧的残差宏块Dn;
5.将Dn分割为8×8或4×4的子块,分别进行DCT变换;
6.子块量化(X);
7.子块的DCT系数重排序(Reorder),再进行run-level游程编码(在一个非零的DCT系数前的连续为零的系数的数目被称为“游run”,而非零DCT系数的绝对值被称为“程level”);
8.编码后的系数、运动矢量和相关的宏块头信息经过熵编码(无损)后生成压缩比特率。
重建数据流如下:
1.每个量化后的宏块X经过重定比例(rescale)、IDCT(DCT逆变换)变换生成解码后的残差D'n。由于量化过程不可逆,所以D'n和原宏块Dn并不相同(有失真);
2.残差Dn与运动补偿预测P相加得到重建宏块,所有重建宏块一起得到重建帧Fn。
第n帧Fn编码结束后,其重建帧F'n可以用来作为参考帧,并用于第n+1帧Fn+1的编码。
以下是添加帧内预测后的H.264编码器流程图:
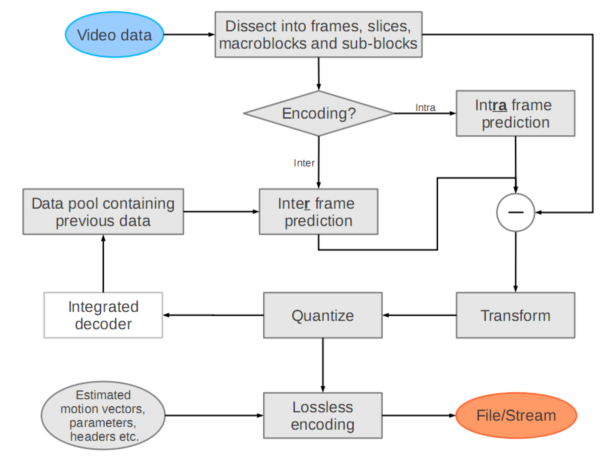
H.264编码器流程图
3.2.1 解码器

解码器数据流:
1.熵解码器从压缩比特流中解码出变换系数、运动矢量和宏块头信息;
2.反向run-level游程编码并重排序之后,得到量化的变换域宏块X;
3.X经过重定比例(rescale)、IDCT变换生成解码后的残差D'n;
4.根据解码后的运动矢量,在解码器上一次重构的参考帧F'n-1中找到16×16的匹配区域,作为运动补偿的预测P;
5.残差D'n与P相加得到重建宏块,所有重建宏块一起得到重建帧F'n。
F'n可以用来显示,也可存储下来作为解下一帧F'n+1的参考帧。
以下为包含帧内预测的H.264解码器流程图:
H.264 解码器流程图
扩展阅读:一份研究报告《H.264/MPEG-4 Advanced Video Coding》, by Alexander Hermans, 2012.9.11. 本小节H.264编/解码器流程图表来自该文。
4.Level(级别)和Profile(档次)
4.1 Level(级别)
Level(级别)是用来约束分辨率、帧率和码率的。
| Level |
Max macroblocks |
Max video bit rate (kbit/s) |
Examples for high resolution @ frame rate (max stored frames) |
||||
| per second |
per frame |
BP, XP, MP |
HiP |
Hi10P |
Hi422P, Hi444PP |
||
| 1 |
1,485 |
99 |
64 |
80 |
192 |
256 |
128×96@30.9 (8) |
| 1b |
1,485 |
99 |
128 |
160 |
384 |
512 |
128×96@30.9 (8) |
| 1.1 |
3,000 |
396 |
192 |
240 |
576 |
768 |
176×144@30.3 (9) |
| 1.2 |
6,000 |
396 |
384 |
480 |
1,152 |
1,536 |
320×240@20.0 (7) |
| 1.3 |
11,880 |
396 |
768 |
960 |
2,304 |
3,072 |
320×240@36.0 (7) |
| 2 |
11,880 |
396 |
2,000 |
2,500 |
6,000 |
8,000 |
320×240@36.0 (7) |
| 2.1 |
19,800 |
792 |
4,000 |
5,000 |
12,000 |
16,000 |
352×480@30.0 (7) |
| 2.2 |
20,250 |
1,620 |
4,000 |
5,000 |
12,000 |
16,000 |
352×480@30.7(10) |
| 3 |
40,500 </ |
||||||
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2694
2694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









