






在微信后台这样的大规模系统中,实现亿级 QPS(Queries Per Second,每秒查询率)并进行熔断降级以防止崩溃,通常会采用以下一系列技术手段:
一、熔断机制
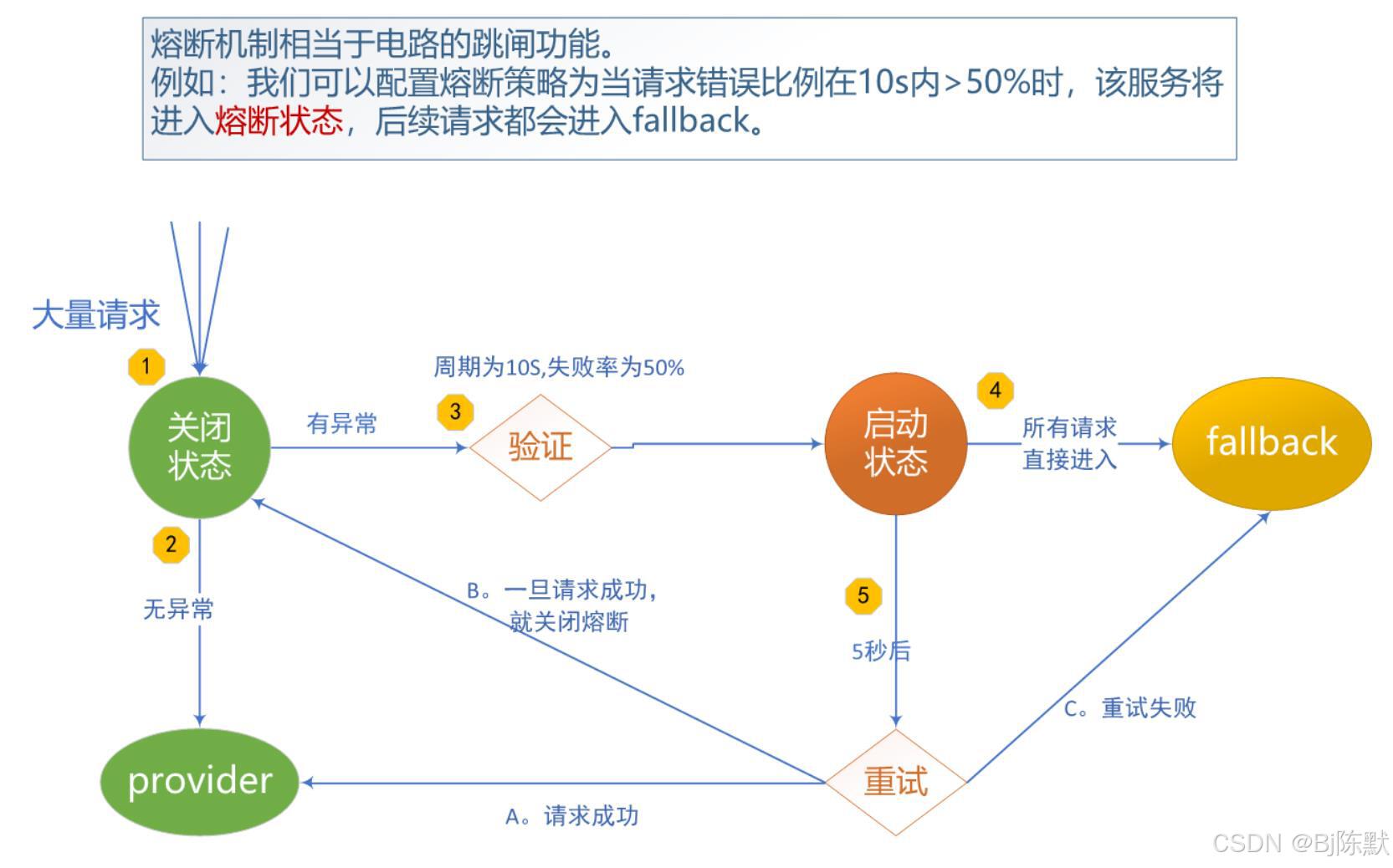
1. 定义触发条件
当系统检测到某个服务的错误率超过一定阈值时,比如连续出现多次请求失败,或者响应时间过长超过设定的时间限制,就会触发熔断。例如,如果一个服务在短时间内的错误率达到 30%,则启动熔断机制。
监控服务的负载情况,当服务的并发请求数量超过其处理能力的一定比例时,也可以触发熔断。比如,当一个服务的并发请求量达到其最大处理能力的 80%,并且持续一段时间,就触发熔断以防止服务被压垮。
2. 熔断策略
快速失败:一旦触发熔断,立即停止向该服务发送新的请求,快速返回预设的错误信息或默认值,避免更多的请求在故障服务上浪费时间和资源。
半开状态尝试恢复:在熔断一段时间后,系统会进入半开状态,尝试向故障服务发送少量请求,以检测服务是否已经恢复。如果这些请求成功,则逐渐恢复正常的请求流量;如果请求仍然失败,则重新进入熔断状态。
二、降级策略
1. 功能降级
对于一些非关键功能,在系统压力过大时可以暂时关闭或降低其性能要求。例如,在高负载情况下,微信可能会暂时关闭一些不太常用的个性化推荐功能,以确保核心的消息发送和接收功能不受影响。
简化服务响应:减少返回数据的复杂度和大小,只返回关键信息,以降低服务的处理压力和响应时间。比如在网络拥堵时,只返回聊天消息的文本内容,而不返回图片、表情等附加信息。
2. 数据降级
缓存降级:当后端数据存储出现问题时,可以使用缓存中的旧数据来响应请求,虽然数据可能不是最新的,但可以保证系统的基本可用性。例如,当微信的数据库出现故障时,可以使用缓存中的用户头像和昵称等信息来显示聊天界面,而不是实时从数据库中获取。
有损数据服务:在极端情况下,可以提供一些有损的数据服务,比如降低图片的分辨率、减少音频的质量等,以保证系统的基本功能能够正常运行。
三、监控与反馈
1. 实时监控
对系统的各个组件进行全面的监控,包括服务的请求量、响应时间、错误率、资源利用率等指标。通过分布式监控系统,实时收集和分析这些数据,以便及时发现问题并触发熔断和降级机制。
例如,使用 Prometheus 和 Grafana 等监控工具,对微信后台的各个服务进行实时监控,一旦发现某个服务的指标异常,就会发出警报。
2. 反馈调整
根据监控数据和用户反馈,不断调整熔断和降级的策略。如果发现某个服务的错误率一直很高,可能需要进一步调整熔断的阈值或者采取更严格的降级措施。
同时,通过用户反馈渠道,了解用户对系统降级后的体验,以便在保证系统可用性的前提下,尽量减少对用户的影响。
总之,微信后台通过综合运用熔断和降级机制,以及强大的监控和反馈系统,能够在高负载情况下保证系统的稳定性和可用性,防止系统崩溃。
微信的熔断机制有哪些优点?
一、保障系统稳定性
在面对高并发流量或服务故障时,熔断机制能够迅速切断对故障服务的调用,防止故障扩散,从而保障整个微信系统的稳定性。例如,当某个后端服务出现问题,如响应时间过长或频繁报错,如果没有熔断机制,大量的请求会持续堆积在该服务上,不仅会导致该服务彻底崩溃,还可能影响到依赖它的其他服务,最终引发连锁反应,使整个微信系统陷入瘫痪。而熔断机制可以及时阻止这种情况的发生,确保系统的核心功能不受影响,维持系统的基本运行。
二、提升系统性能
1. 减少不必要的资源浪费
当熔断发生后,不再向故障服务发送请求,避免了这些请求在网络传输、服务处理等环节的资源消耗。这使得系统能够将有限的资源集中用于正常运行的服务上,提高资源利用率,进而提升整体系统性能。
比如,原本可能有大量的 CPU 和内存资源被浪费在等待故障服务的响应上,现在这些资源可以被分配给其他关键服务,加快处理速度。
2. 降低响应时间
由于熔断后可以快速返回预设的错误信息或默认值,而不是让用户长时间等待故障服务的响应,因此能够大大降低用户的等待时间,提升用户体验。
例如,在没有熔断机制的情况下,用户可能需要等待几十秒甚至几分钟才能得到一个错误提示,而有了熔断机制,用户可以在几毫秒内就收到一个友好的提示信息,告知他们当前服务不可用,请稍后再试。
三、增强系统可扩展性
1. 便于故障排查和修复
熔断机制使得故障服务被隔离,开发人员可以更清楚地定位问题所在,集中精力对故障服务进行排查和修复,而不会被其他正常服务的干扰。
例如,当微信的某个新功能上线后出现问题,熔断机制可以迅速将该功能对应的服务熔断,开发人员可以快速确定是这个新功能引起的问题,针对性地进行修复,而不会影响到微信的其他主要功能。
2. 支持动态调整
微信的熔断机制可以根据实际情况进行动态调整,适应不同的负载和故障场景。例如,可以根据系统的实时负载情况调整熔断的阈值,在高负载时降低阈值,更加严格地控制对故障服务的调用,以保障系统的稳定性;在低负载时提高阈值,允许更多的请求尝试访问可能已经恢复的服务,提高系统的可用性。
同时,还可以根据不同服务的重要性和特性,设置不同的熔断策略,实现精细化的管理,进一步增强系统的可扩展性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











