







在 1B 参数的 LLM 上测试 17 种提示工程技巧
当你使用像 ChatGPT 这样的 AI 模型时,提问或给出指令的方式被称为提示(prompting),这其实有很大的讲究哦。无论你是直接使用这个工具,还是构建基于 LLM 的应用程序,都是如此。
要是想得到更准确、更有创意或者更可靠的回答,学习提示工程的基础知识就很有用了。这主要是关于如何撰写提示,以便让模型更清楚你到底想要什么。
在本文中,我们将在一个 1B LLaMA 模型 上以一种基础的方式测试 17 种提示技巧,看看它们能在多大程度上改善小型 LLM 的结果。
你可以直接滚动浏览这篇博客,也可以使用这个速查表以便更快地参考。
文章目录
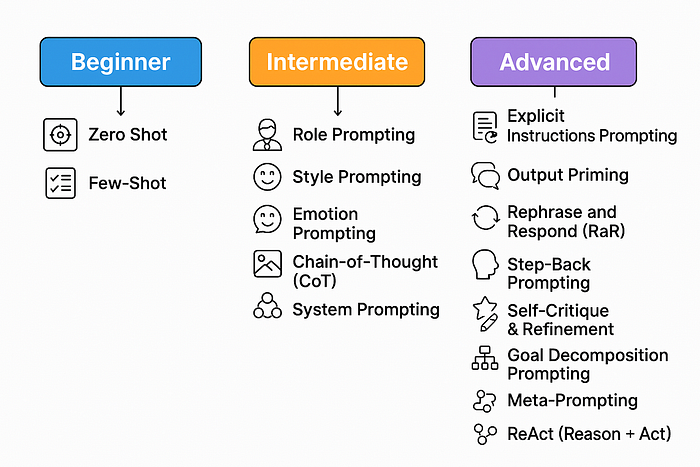
- 在 1B 参数的 LLM 上测试 17 种提示工程技巧
- 搭建舞台
- 零样本(Zero Shot)
- 少样本(Few-Shot)
- 角色提示(Role Prompting)
- 风格提示(Style Prompting)
- 情感提示(Emotion Prompting)
- 上下文提示(Contextual Prompting)
- 思维链(Chain-of-Thought, CoT)
- 系统提示(System Prompting)
- 明确指令提示(Explicit Instructions Prompting)
- 输出引导(Output Priming)
- 重述并回应(Rephrase and Respond, RaR)
- 后退提示(Step-Back Prompting)
- 自我批评与改进
- 目标分解提示(Goal Decomposition Prompting)
- 元提示(Meta-Prompting)
- 反应(ReAct)
- 思维线索(Thread-of-Thought, ThoT)
- 总结
搭建舞台
在我们开始测试这些技巧之前,我们需要定义一些稍后会用到的函数,例如将我们的 1B LLaMA 模型加载到一个函数中,以避免代码重复。那么,我们先来做这件事吧。
# 导入所需模块
import os
from openai import OpenAI
import json
# 使用自定义基础 URL 和 API 密钥初始化 OpenAI 客户端
client = OpenAI(
base_url="https://api.studio.nebius.com/v1/",
api_key="YOUR NEBIUS/TogetherAI API KEY"
)
# 我们的 LLaMA 3.2 1B 指令模型
MODEL_NAME = "meta-llama/Llama-3.2-1B-Instruct"
# 默认系统提示
DEFAULT_SYSTEM_PROMPT = "You are a helpful assistant."
# 用户提示函数
def create_user_content(text):
"""辅助函数,用于以期望的格式创建用户消息内容。"""
return [{ "type": "text", "text": text }]
# 调用 LLaMA 3.2 1B LLM 函数以生成回答
def call_llm(messages_list, model_name=MODEL_NAME, temperature=0.0):
"""调用 LLM,传入消息列表并返回回答的内容。"""
response = client.chat.completions.create(
model=model_name,
temperature=temperature,
messages=messages_list
)
return response.choices[0].message.content
我们定义了一些比较通用的东西。虽然我使用 Nebius LLM 提供商来加载我的 LLaMA 3.2 1B 模型,但你也可以使用 Hugging Face 来做这件事。
两者没有区别;我仅仅是把它当作一个 API 来快速获取回答,无需等待。
让我们开始测试不同的提示技巧及其用例吧。
零样本(Zero Shot)
零样本提示是与 LLM 交互最直接的方式。
你只需直接让模型执行任务或回答问题,而无需给出任何具体的示例来说明你希望它如何完成。
模型完全依赖其预先存在的知识和训练来理解你的意思并生成回答。
这种技巧适用于:
- 简单的问答(例如,“法国的首都是哪里?”)。
- 基本文本摘要,当风格不太重要时。
- 快速头脑风暴或生成初步想法。
- 任何你认为 LLM 已经有足够的通用理解能力来处理请求而无需具体指导的任务。这通常是你的首选。
假设我们想让 1B LLaMA 模型解释一个科学概念,比如光合作用。一个非常基础的零样本提示可能是这样的:
user_prompt_before = "What is photosynthesis?"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Photosynthesis is a process plants use to make their food.
They use sunlight, water, and carbon dioxide.
这还行,但要是我们希望解释得更简单一些呢?即使仍然使用零样本(也就是说,仍然不提供示例),我们也可以通过使请求更具体来显著改善结果。
我们没有给它一个“如何回答”的示例,但我们告诉了它“谁”是回答的对象。
user_prompt_after = "Explain photosynthesis to a 5-year-old child."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Imagine plants are like little chefs! They use sunshine like
a magic oven, drink water, and breathe in air to make their
own yummy food called sugar. That's how they grow big and strong!
“之后”的提示虽然仍然是零样本,但更好地引导了模型。通过添加上下文(受众是“5 岁儿童”),1B 模型更有可能产生一个更简单、更有趣且使用适当类比的回答。
少样本(Few-Shot)
少样本提示比零样本提示更进一步。与其只是让 LLM 做某事,你会给它几个示例(“样本”),展示你想要它执行的任务的类型,展示你将提供什么样的输入以及你期望什么样的输出。这有助于模型“在上下文中学习”你到底在寻找什么。
- **单样本提示(One-Shot Prompting)**是少样本提示的一个特例,你只提供一个示例。
- 提供的示例越多(在模型的上下文窗口允许的范围内),模型通常越能理解复杂的模式或期望的输出格式。
少样本提示在以下情况下特别有用:
- 情感分析(将文本分类为正面、负面或中性)。
- 根据自然语言描述简单生成代码。
- 数据提取或重新格式化。
- 以高度特定的非标准风格生成文本。
让我们尝试让 1B LLaMA 模型对电影评论进行情感分类。如果没有示例,使用零样本方法,我们得到的是一个对话式的回答,而不是一个严格的标签。
user_prompt_before = "Classify the sentiment of this movie review: 'The movie was okay, not great but not terrible.'"
messages = [
{"role": "system", "content": "You are a sentiment classifier."}, # 一点角色提示
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
The sentiment of the movie review 'The movie was okay,
not great but not terrible.' appears to be Neutral.
模型正确地判断了情感,但它有点啰嗦。对于一个应用程序来说,我们可能只需要一个“中性”这样的单词。
现在,让我们提供几个示例(样本),向模型展示我们期望的确切输入输出格式。
# 实际查询是最后一个用户消息
target_review = "Classify: 'The movie was okay, not great but not terrible.'"
messages_few_shot = [
{"role": "system", "content": "You are a sentiment classifier. Respond with only 'Positive', 'Negative', or 'Neutral'."},
# 示例 1
{"role": "user", "content": create_user_content("Classify: 'This is the best movie I have ever seen!'")},
{"role": "assistant", "content": "Positive"},
# 示例 2
{"role": "user", "content": create_user_content("Classify: 'I hated this film, it was a waste of time.'")},
{"role": "assistant", "content": "Negative"},
# 示例 3(单样本会在第一个示例对后停止)
{"role": "user", "content": create_user_content("Classify: 'The plot was predictable, but the acting was decent.'")},
{"role": "assistant", "content": "Neutral"},
# 实际查询
{"role": "user", "content": create_user_content(target_review)}
]
response = call_llm(messages_few_shot)
print(response)
### 输出 ###
Neutral
通过少样本示例,1B LLaMA 模型完全理解了我们想要一个单词的分类(“正面”、“负面”或“中性”),而不是一个完整的句子。它从示例中学会了期望的任务和输出格式。
角色提示(Role Prompting)
角色提示是一种技巧,你指示 LLM 扮演一个特定的角色或人物。就好像在一场戏剧中选角一样。
你告诉模型,“扮演一个[特定角色]”,比如“扮演一个经验丰富的旅行向导”、“你是怀疑论的科学家”或者“像 17 世纪的海盗那样说话”。
这个指令通常放在系统提示中或用户提示的开头,它会影响 LLM 的语气、词汇、风格,有时甚至会影响它优先考虑或如何构建回答的信息。
角色提示非常适合:
- 让互动变得更有趣或更吸引人(例如,一个海盗解释编程)。
- 为特定受众进行解释(例如,“像耐心的老师给好奇的高中生解释量子物理一样”)。
- 以特定的声音生成创意内容(例如,一个睿智的老龙讲述的故事)。
- 模拟不同角色或专家之间的对话。
- 从特定的“专家”视角获取建议,即使 LLM 只是根据其训练数据模拟这种专业知识。
让我们先不给 1B LLaMA 模型分配任何特定角色,让它告诉我们关于黑洞的信息。
user_prompt_before = "Tell me about black holes."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT}, # 通用的“有帮助的助手”
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
A black hole is a region of spacetime where gravity is so strong
that nothing, not even light, can escape from it. They are formed
from the remnants of massive stars that collapse under their own gravity.
这是一个完全正常的、事实性的但标准的解释。这就是你从一个通用的有帮助的助手那里期待得到的回答。
现在,让我们分配一个有趣的角色。我们让 LLM 像一个有点古怪又热情的天文学家来解释黑洞。这个指令最好放在系统提示中,以便在整个对话中保持一致的角色。
system_prompt_role_after = "You are Professor Astra, a friendly and slightly eccentric astronomer. You love to explain complex space topics with a sense of wonder, using simple analogies, and a touch of humor."
user_prompt_after = "Professor Astra, I'm curious! Can you tell me all about those mysterious black holes?"
messages = [
{"role": "system", "content": system_prompt_role_after},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Ah, black holes, my young stargazer! Magnificent, aren't
they? Imagine the universe's hungriest vacuum cleaners, but like,
SUPER DUPER powerful! When a really, really big star runs out of fuel,
it can't hold itself up anymore and *WHOOSH* it collapses into an tiny,
tiny point with CRAZY strong gravity.
1B LLaMA 模型在“Professor Astra”角色的引导下,给出了一个更有趣、更生动、更吸引人的解释。
它使用了热情的语言(“SUPER DUPER powerful,” “CRAZY strong”)、类比(“universe’s hungriest vacuum cleaners”)以及一点角色特色(“my young stargazer,” “Fascinating, eh?”)。
风格提示(Style Prompting)
风格提示与角色提示密切相关,但更专注于输出的文本特征,而不是一个完整的人物。
你是在引导 LLM 以特定的文学、艺术、正式或非正式的风格来写作。例如:“像欧内斯特·海明威那样写作”,“像我五岁时那样解释这个”。
虽然角色提示定义了 LLM 是谁,但风格提示定义了 LLM 是如何写作的。风格提示非常灵活:
- 创意写作:生成具有特定文学风格的故事、诗歌或剧本。
- 内容改编:为不同受众重写现有文本(例如,简化技术术语,使内容更随意或更正式)。
- 营销与品牌:撰写符合特定品牌声音的文案。
- 教育材料:创建针对不同学习水平或偏好的解释。
- 幽默与模仿:模仿独特的写作风格以达到喜剧效果。
让我们让 1B LLaMA 模型写一段关于日落的简短描述,但不给出任何风格上的指示。
user_prompt_before = "Write a short description of a sunset."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
The sun slowly dips below the horizon, casting a warm glow across
the sky. Colors like orange, pink, and purple often appear as
the light fades and day turns into night.
这是一个不错的、直白的描述。它很实用,但缺乏任何特别的艺术魅力或独特性。
现在,让我们要求以特定的诗歌风格来描述:一首俳句。俳句有独特的结构(5–7–5 个音节),通常唤起自然意象。
user_prompt_after = "Write a short description of a sunset in the style of a haiku."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Golden light descends,
Sky ablaze with fiery hues,
Day gives way to night.
“之后”的提示通过指定“以俳句的风格”,改变了输出。
1B LLaMA 模型试图遵循 5–7–5 个音节的结构(或者至少接近),并专注于俳句典型的简洁、富有表现力的意象。
情感提示(Emotion Prompting)
情感提示涉及指示 LLM 生成一个传达特定情感或从情感角度写成的回应。
你实际上是要求 AI“感受”(或者至少,令人信服地模拟出感受)某种情感,当它写作时。
情感提示对于以下场景非常有价值:
- 创意写作:为角色或叙述增加情感深度。
- 沟通:撰写需要传达特定情感的邮件(例如,感谢信、慰问信、道歉信)。
- 客户服务:生成对客户查询或投诉的富有同理心的回应。
- 营销:创建与目标受众产生情感共鸣的广告文案。
- 角色扮演和模拟:开发具有不同情感状态的角色。
让我们让 1B LLaMA 模型写一封感谢收到的礼物的感谢信,但不给出任何特定的情感方向。
user_prompt_before = "Write a thank you note for a gift I received."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Dear [Givers Name],
Thank you very much for the gift. I appreciate your thoughtfulness.
Sincerely,
[Your Name]
这是一个礼貌但非常标准且有点乏味的感谢信。它完成了任务,但没有传达太多真挚的情感。
现在,让我们要求一封表达强烈积极情感:深深的感激和兴奋的感谢信。我们还会添加一点关于礼物的上下文,以帮助 LLM。
user_prompt_after = "Write a thank you note for a gift I received. Make it sound very excited and deeply grateful. The gift was a book I've wanted for ages and I was thrilled to get it!"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Dear [Givers Name],
Oh my goodness, thank you SO, SO MUCH for the book! I was absolutely
over the moon when I opened it – I have been wanting this one for what
feels like forever! I am so incredibly excited to start reading it.
This was such a thoughtful and amazing gift, I can't tell you how much
I appreciate it. You are the best!
With heartfelt gratitude and tons of excitement,
[Your Name]
通过明确要求“兴奋”和“深深的感激”,并提供关于礼物的上下文(“我渴望已久的书”),1B LLaMA 模型生成了一封更温暖、更个人化且情感表达更丰富的感谢信。
上下文提示(Contextual Prompting)
上下文提示就是给 LLM 提供足够与你的请求相关的背景信息。如果 LLM 没有足够的上下文,这就像是让别人在没有告诉你起点或目的地的情况下给你指路。
上下文提示在几乎所有非平凡的 LLM 交互中都至关重要:
- 个性化推荐:根据用户历史或声明的偏好推荐电影、书籍或产品。
- 问题解决:为 LLM 提供所有相关数据点以便分析。
- 内容生成:撰写关于特定主题的文章或摘要,其中背景细节很重要。
- 多轮对话:确保 LLM 记住并利用对话早期的信息。
- 任务完成:为 LLM 提供所有必要的输入,以便其执行特定操作(例如,“下周二上午为两名成人预订从伦敦到巴黎的航班”)。
让我们让 1B LLaMA 给出一个礼物建议,但不提供任何有用的信息。
user_prompt_before = "Suggest a gift."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Some popular gift ideas include books, gift cards, flowers,
or a nice meal out. To give a more specific suggestion,
I do need to know more about the personyou are buying
for and the occasion!
1B 模型尽其所能,给出了非常通用的建议。它甚至正确地指出它需要更多信息!当提示过于模糊时,这是常见的回应。
现在,让我们提供一些丰富的上下文:礼物是给谁的、场合、他们的兴趣以及预算。
user_prompt_after = (
"I need a gift suggestion. Here's some context:\n"
"- Recipient: My sister, she's 30 years old.\n"
"- Occasion: Her birthday.\n"
"- Interests: She loves reading fantasy novels, gardening, and trying new loose-leaf teas.\n"
"- Budget: Around $50.\n"
"Suggest a thoughtful gift based on this."
)
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, for your sister who loves fantasy novels, gardening,
and tea, with a $50 budget, here are a few thoughtful birthday gift ideas:
1. **A Curated Tea and Fantasy ... [截断的回答]
现在,建议变得具体、与姐姐的兴趣相关,并且考虑到了预算。这清楚地展示了上下文提示的力量:你给 LLM 提供的相关信息越多,它的输出就越贴切、越有针对性。
思维链(Chain-of-Thought, CoT)
思维链旨在提高 LLM 的推理能力,特别是对于需要多步思考的任务,比如算术、常识推理或多跳问答。
与其只是要求最终答案,你可以鼓励 LLM“一步一步地思考”或“展示它的思考过程”。这可以通过以下方式实现:
- 零样本 CoT:在你的提示中简单地加上“让我们一步一步地思考”这样的短语。
- 少样本 CoT:在你的提示中提供示例,这些示例不仅展示最终答案,还展示得出答案所采取的中间推理步骤。
CoT 提示对于以下场景非常重要:
- 数学应用题:解决需要分解的算术或代数问题。
- 逻辑推理谜题:解决涉及多个约束或推断的谜题。
- 常识推理:回答需要理解隐含关系或日常知识的问题。
- 多步问答:一个问题的答案取决于前一个问题的答案。
- 调试 LLM 的回应,因为思考过程变得可见。
让我们给 1B LLaMA 模型一个简单的数学应用题,看看它能否直接解决。较小的模型通常在多步算术上会遇到困难。
user_prompt_before = "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(f"Answer: {response}")
### 输出 ###
Answer: Roger now has 11 tennis balls.
即使答案正确,模型也只给出了最终答案。如果它是错误的,我们就不知道它的推理依据是什么了。
现在,让我们使用简单的零样本 CoT,在提示中加上“让我们一步一步地思考。”
user_prompt_after = "Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? Let's think step by step."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, lets break this down step by step:
1. Roger initially has 5 tennis balls.
2. He buys 2 more cans of tennis balls.
3. Each can contains 3 tennis balls.
4. So, the total number of new tennis balls he bought is 2 cans * 3 balls/can = 6 tennis balls.
5. To find out how many tennis balls he has now, we add the initial number of balls to the new balls: 5 balls + 6 balls = 11 balls.
Therefore, Roger now has 11 tennis balls.
区别非常明显!通过简单地加上“让我们一步一步地思考”,1B LLaMA 模型包含了它的推理过程。
系统提示(System Prompting)
系统提示(也称为使用“系统消息”或“预提示”)涉及向 LLM 提供高层次的指令、上下文、角色指导或整个对话或交互会话中适用的总体行为规则。
系统提示的关键好处是,这些指令在不需要在每个用户查询中重复的情况下持续存在,从而使 LLM 的行为更加一致和可控。
假设我们希望 1B LLaMA 对一段文本进行摘要,并且我们希望摘要非常简洁,具体为一句话。我们可以在用户提示中加上这个限制。
text_to_summarize = "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower. Locally nicknamed 'La dame de fer' (French for 'Iron Lady'), it was constructed from 1887 to 1889 as the centerpiece of the 1889 World's Fair. Although initially criticized by some of France's leading artists and intellectuals for its design, it has become a global cultural icon of France and one of the most recognizable structures in the world."
user_prompt_before = f"Summarize the following text in one sentence: '{text_to_summarize}'"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT}, # 使用默认的通用系统提示
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
The Eiffel Tower, a wrought-iron lattice structure in Paris designed
by Gustave Eiffel for the 1889 Worlds Fair, overcame initial criticism
to become a global French cultural icon.
现在,让我们把关于简洁性和 LLM 角色的核心指令移到系统提示中。这使得用户提示更简单,并且对于一系列摘要任务来说,这个指令更具持久性。
custom_system_prompt = "You are a 'Concise Summarizer'. Your primary goal is to provide the shortest possible, grammatically correct summary that captures the main essence of any text provided. For all summaries, aim for just one clear sentence unless explicitly instructed otherwise."
messages = [
{"role": "system", "content": custom_system_prompt},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
The Eiffel Tower in Paris, designed by Gustave Eiffel for the 1889
Worlds Fair, became a globally recognized French cultural icon despite
initial critiques.
对于单一请求来说,输出质量可能相似,但这种方法在处理大量查询时更具鲁棒性和可扩展性。
明确指令提示(Explicit Instructions Prompting)
它专注于使你的请求清晰、直接且毫无歧义。它的目标是尽可能减少误解的空间,通过:
你应该在几乎所有提示中都力求明确的指令,但在以下情况下尤其关键:
- 期望的输出有特定的结构或内容要求。
- 你希望避免某些主题或类型的信息。
- 长度或简洁性很重要。
- 任务复杂,可能会有多种解释方式。
- 与较小的 LLM 一起工作时,这些 LLM 从非常直接的指导中受益匪浅。
让我们让 1B LLaMA 模型“写关于苹果的内容”——这是一个非常开放且模糊的请求。
user_prompt_before = "Write about apples."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Apples are a popular fruit that grow on apple trees.
They come in various colors like red, green, and yellow,
and can be eaten raw or used in cooking things like pies and sauce.
Apples are known to be a good source of fiber and vitamins.
模型给出了一些关于苹果的一般性事实。这并没有错,但它没有得到指导。如果用户有特定的关注点呢?
现在,让我们变得更加具体。我们将告诉 LLM 要关注苹果的哪些方面、期望的长度以及要避免的内容。
user_prompt_after = (
"Write a short paragraph about apples focusing on their nutritional benefits and common varieties.\n"
"The paragraph should be exactly 3 sentences long.\n"
"Mention at least two specific varieties (e.g., Granny Smith, Fuji).\n"
"Do not discuss apple cultivation or history."
)
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Apples are a nutritious fruit, offering beneficial fiber and
essential vitamins like Vitamin C that contribute to a healthy diet.
来自明确提示的输出明显更符合我们(现在已明确说明)的要求。
输出引导(Output Priming)
它发生在你给 LLM 提供它期望回答的开头时,本质上是为它开了个头。
通过给出这个“起点”,你引导模型朝着特定的结构、格式、语气或内容延续的方向发展。
这就像是给 LLM 一个轻推,让它朝着你希望它的输出方向发展。
对于旧式的完成风格模型(比如 text-davinci-003),你会直接将你的引导词附加到提示中,模型会完成它。对于聊天模型(比如 LLaMA Instruct),这通常是通过以下方式实现的:
- 通过将用户的最后一条消息结构化,使其自然地引导到期望的输出格式(例如,以“Here is the list:\n-”结尾)。
- 使用少样本示例,其中助手的示例回答以引导的方式开始。
让我们让 1B LLaMA 列出简单香草蛋糕的配料,但不尝试引导输出格式。
user_prompt_before = "What are the ingredients for a simple vanilla cake?"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
For a simple vanilla cake, you will typically need ingredients like flour,
sugar, eggs, butter or oil, milk, baking powder, and vanilla extract.
Some recipes might also include salt.
模型列出了配料,但它以句子或段落的形式列出。这很适合阅读,但如果我们需要一个机器可解析的列表,或者只是一个干净的项目符号格式的食谱卡呢?
现在,让我们通过引导输出来尝试获得一个项目符号列表。我们将在用户的提示中以一种强烈暗示助手应继续以列表形式回答的方式结束。
user_prompt_after = (
"What are the ingredients for a simple vanilla cake? Please list them out.\n"
"Here are the ingredients for a simple vanilla cake:\n"
"-"
)
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
# 为了显示,我们将响应的第一个项目添加到前面
print(f"Here are the ingredients for a simple vanilla cake:\n- {response}")
### 输出 ###
Here are the ingredients for a simple vanilla cake:
- Flour
- Sugar
- Eggs
- Butter (or oil)
- Milk
- Baking powder
- Vanilla extract
- A pinch of salt
通过以“Here are the ingredients…\n-”结束用户提示,我们强烈地向 1B LLaMA 模型暗示了其回答应作为该列表的延续。
重述并回应(Rephrase and Respond, RaR)
它是一种更简单的直接提示形式,涉及让 LLM 首先重述你的请求或解释其对任务的理解**,然后再尝试生成主要回答。
这就像一个检查点,以确保 LLM 正在正确的道路上,特别是对于复杂或可能有歧义的查询。
当:
- 用户的请求复杂、多面或可能有歧义。
- 错误或不一致的回答的成本很高(例如,基于误解生成一篇长文档)。
- 你希望确保 LLM 已经掌握了请求的所有关键约束或组成部分。
- 教授或演示如何分解问题时。
让我们给 1B LLaMA 一个有点模糊的创意任务:“写一个关于旅行的故事。”这可以有很多种意思!
user_prompt_before = "Write a story about a journey."
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Elara the brave squirrel packed a small bag of nuts and set off
from her cozy oak tree. She journeyed through whispering woods,
across a babbling brook, and over sun-dappled meadows.
After many days, she reached the legendary Giant Berry Bush,
its branches laden with the sweetest fruit she had ever tasted,
and returned home a hero.
模型生成了一个故事。这是一个旅行,但它是众多可能性中的一个。如果用户想象的是一次太空旅行,或者一次情感之旅呢?LLM 只是选择了一种解释。
现在,让我们指示 1B LLaMA 模型首先陈述其对“关于旅行的故事”的理解,然后再写故事。
user_prompt_after = (
"I'd like a story about a journey.\n"
"First, briefly describe what kind of journey you are planning to write about (e.g., is it an adventure, an emotional journey, a short trip, a long quest? Who is the main character?).\n"
"Then, write a short story (around 100 words) based on your description."
)
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出
Finn, a young inventor with grease-stained fingers, clutched his whirring
contraption. His journey to King Oberons far-off castle was fraught with peril:
rickety bridges and shadowy forests tested his resolve ...
通过要求 LLM 首先陈述其理解,我们迫使它“承诺”一个特定类型的旅行。即使在这个一次性提示中没有用户反馈,这个内部澄清步骤也可以导致一个更集中的故事。
后退提示(Step-Back Prompting)
当你引导 LLM 首先考虑与特定问题相关的更广泛的概念、原则或一般知识**,然后再尝试回答那个具体问题本身时。
这就像是让模型“拉远镜头”,建立基础理解,然后再“拉近镜头”专注于细节。
核心思想是,通过首先检索并阐述一般原则,LLM 然后可以将这个更广泛的上下文应用到具体问题上,从而得出更有洞察力、更合理、更全面的答案。
后退提示对于以下场景特别有效:
- 涉及细微差别或定义的问题:(例如,“病毒是活的吗?”)。
- 涉及复杂或有争议话题的查询:理解基础原则是关键。
- 可以从第一性原理思考中受益的问题解决。
- 解释复杂主题:通过首先阐述基础。
- 避免陷入过于简单的答案的陷阱,通过强迫一个更考虑周全的方法。
让我们问 1B LLaMA 一个经典的问题:“番茄是水果还是蔬菜?”
user_prompt_before = "Is a tomato a fruit or a vegetable?"
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
{"role": "user", "content": create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Botanically speaking, a tomato is a fruit because it develops from the
flowers ovary and contains seeds. However, in culinary contexts,
it is often treated as a vegetable due to its savory flavor and use
in main dishes.
1B 模型给出了一个很好的常见答案,涉及到了植物学和烹饪学的视角。然而,它并没有深入解释为什么存在这些不同的分类。
现在,让我们使用后退提示。我们将要求 LLM 首先解释“水果”的植物学定义和“蔬菜”的一般烹饪理解**,然后再将这些定义应用到番茄上。
user_prompt_after = (
"I have a question about tomatoes. But first, please explain:\n"
"1. What is the botanical definition of a fruit?\n"
"2. What is the general culinary understanding of a vegetable?\n\n"
"Now, using those definitions, explain whether a tomato is considered a fruit or a vegetable, and clarify why there's often confusion."
)
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM_PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, let's break this down:
1. **Botanical Definition of a Fruit:* ... [截断]
“之后”的回答更加全面且具有教育意义。通过首先建立基础定义(“后退一步”),LLM 提供了一个更清晰且更有力的解释,说明了为什么番茄在植物学上是水果,而在烹饪学中通常被视为蔬菜。
自我批评与改进
这是一种多步骤技巧,你指示 LLM:
- 首先,对任务生成一个初始回答。
- 然后,根据特定标准(例如,清晰度、简洁性、准确性、相关性、创造力、遵守约束条件)批判性地评估自己的回答。
- 最后,根据自己的批评,生成一个修订和改进后的回答。
当:
- 创意任务:改进标语、故事创意、诗歌或营销文案。
- 复杂解释:确保清晰度、准确性和完整性。
- 摘要:提炼摘要,使其更简洁且更好地捕捉关键点。
- 代码生成:要求模型审查其代码是否存在错误、效率问题或是否符合最佳实践。
- 任何第一次尝试可能不错但可以从“第二次审视”和润色中受益的任务。
让我们让 1B LLaMA 为一款新的环保水瓶生成一个简短、吸引人的标语。一次性尝试可能还不错,但可能并不出色。
user_prompt_before = "Write a short, catchy slogan for a new eco-friendly water bottle."
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM_PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(f"Slogan: {response}")
### 输出 ###
Slogan: Sip Green, Live Clean.
这是一个不错的标语。它很短,押韵,并且暗示了“环保”(Green)和“水”(Sip/Clean)。但能不能更好、更直接一些呢?
现在,让我们要求 1B LLaMA 生成一个标语,然后对其进行批评,最后提供一个改进后的版本。
user_prompt_after = (
"I need a short, catchy slogan for a new eco-friendly water bottle. Please follow these steps:\n"
"1. First, generate one initial slogan.\n"
"2. Then, critically evaluate your own slogan:\n"
" * Is it catchy and memorable?\n"
" * Does it clearly communicate 'eco-friendly'?\n"
" * Does it relate well to a 'water bottle'?\n"
" * What are its weaknesses or areas for improvement?\n"
"3. Finally, based on your critique, provide an improved slogan."
)
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, here is the process:
1. **Initial Slogan:**
Drink Pure, Save Nature Future.
2. **Critique:**
* **Catchy/Memo ... [截断]
这个过程迫使 1B LLaMA 对自己的输出进行针对特定标准的分析。这种结构化的反思很有价值。自我批评提示鼓励了一个更深思熟虑且经过润色的生成过程。
目标分解提示(Goal Decomposition Prompting)
它涉及在提示本身中将一个大型、复杂的任务或目标分解为一系列更小、更易于管理的子目标或步骤。
你实际上是为 LLM 提供了一个结构化的计划或它需要执行的操作序列,以实现整体目标。
这有点类似于思维链(CoT)提示,但尽管 CoT 通常侧重于引出问题的推理步骤,目标分解更多是关于通过明确列出期望输出的组成部分或阶段来指导生成过程。
目标分解在以下场景中非常有效:
- 期望的输出是多方面的,有多个不同的部分(例如,规划活动、撰写有特定部分的报告、生成角色档案)。
- 你希望确保 LLM 考虑到所有必要的组成部分。
- 总体任务对于 LLM(尤其是较小的 LLM)来说过于复杂,无法在单一的、无结构的请求中可靠地处理。
- 你希望引导 LLM 通过其回答的具体工作流程或结构。
让我们让 1B LLaMA 规划一个简单的周末旅行。这是一个相对复杂的任务,有许多隐含的子组成部分。
user_prompt_before = "Plan a simple weekend trip to a nearby nature spot."
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
For a simple weekend trip to a nearby nature spot, you could
consider visiting a local state park or nature reserve.
You might want to pack some snacks and water, go for a hike,
and enjoy the scenery. Remember to check the weather forecast before you go!
1B 模型给出了一些非常一般的想法。“计划”相当模糊,缺乏结构,并且遗漏了许多在实际规划旅行时可能会考虑的关键元素(比如每天的具体活动、除了零食之外还需要带什么,或者安全)。
现在,让我们明确地将“规划旅行”的目标分解为几个不同的子目标或问题,让 LLM 依次解决。
user_prompt_after = (
"I want to plan a simple weekend trip to a nearby nature spot. Please help me by creating a plan that includes the following:\n"
"1. Suggest one specific type of nature spot (e.g., a forest with hiking trails, a lakeside area, a scenic mountain viewpoint).\n"
"2. List 3-4 essential items to pack specifically for that type of nature spot.\n"
"3. Suggest one main activity for Saturday and a different one for Sunday.\n"
"4. Provide one important safety tip relevant to visiting that nature spot."
)
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, here is a plan for your simple weekend nature trip:
1. **Suggested Nature Spot:** A serene lakeside ... [截断]
现在,输出更加结构化且全面。1B LLaMA 解决了指定的每个子目标,从而得到了一个更实用、更有行动性的“计划”。
元提示(Meta-Prompting)
它是一种非常有趣的技巧,你让 LLM 帮助你创建更好的提示,用于另一个(或者甚至是同一个)LLM。你实际上是问 LLM,“我应该如何有效地向你(或者另一个 AI)提出任务 X?”
这就像是咨询一个专家(LLM 本身,它“见过”无数的提示)来了解如何最好地措辞你的请求。
元提示在以下场景中很有用:
- 你不确定如何最好地向 LLM 提出一个复杂的请求。
- 你希望找到更有效的方法来提示特定类型的输出。
- 你希望优化提示,以获得更好的质量、具体性或创造力。
- 你希望利用 LLM 对于什么是好的提示的“知识”。
- 你正在教授他人提示工程,并希望展示 LLM 如何协助提示创建。
假设一个用户希望从 LLM 那里得到一些独特的奇幻故事创意。他们可能会先尝试一个简单的提示,但这可能无法得到他们期望的丰富、有结构的创意。
Give me some fantasy story ideas.
这个提示太基础了。LLM 很可能会给出一些通用的想法。用户想要一个更好的提示,但不知道如何措辞。
所以,与其展示这个弱提示的结果,我们来展示元提示如何帮助创建一个更好的提示。
让我们让 1B LLaMA 帮助我们为生成奇幻故事创意创建一个良好的提示。我们将告诉它我们希望在每个故事创意中包含的信息。
user_prompt_meta_after = (
"I want to use an LLM to generate 3 distinct and creative fantasy story ideas.\n"
"For each story idea, I need the LLM to provide:\n"
"a) A unique main character concept.\n"
"b) A compelling central conflict.\n"
"c) A unique magical element or system integral to the story.\n\n"
"Please write out the actual, detailed prompt I should use to give to an LLM to get these structured fantasy story ideas."
)
messages = [
# 我们可以使用一个系统提示来鼓励良好的提示创作
{"role": "system", “内容”: “You are an expert in prompt engineering and creative writing assistance.”},
{"role": "user", “内容”: create_user_content(user_prompt_meta_after)}
]
# 这个回应就是建议的提示
suggested_prompt_from_llm = call_llm(messages)
print("--- Suggested Prompt from LLM (Meta-Prompting Result) ---")
print(suggested_prompt_from_llm)
### 输出 ###
--- Suggested Prompt from LLM (Meta-Prompting Result) ---
Okay, here is a detailed prompt you can use to get those structured fantasy story ideas:
Please generate 3 di ... [截断]
元提示帮助生成了一个比用户最初的简单尝试更详细、更有结构的提示。当被问及如何提示时,1B LLaMA 依据其对什么是有效提示的隐含理解(具体性、要包含的例子、清晰的结构)来给出答案。
反应(ReAct)
旨在让 LLM 通过将推理(类似于思维链的步骤,分解问题并创建计划)与行动(模拟采取行动以收集信息或与环境互动,即使这个“环境”只是它自己的知识库或假设的工具)交替进行,来解决复杂任务。
模拟的 ReAct 风格提示适用于:
- 多跳问答:找到答案需要按顺序查找几条信息。
- 事实验证:模拟查找事实,然后将它们综合起来。
- 复杂问题解决:需要分解问题,收集信息(即使是假设从自己的知识中收集),然后构建解决方案。
- 规划任务:需要思考步骤,为每个步骤可能需要收集的信息,然后制定计划。
- 让 LLM 的问题解决过程更加明确和可审计,即使它没有使用真正的外部工具。
让我们问一个问题,可能需要 LLM 隐式地查找或结合几条信息。
user_prompt_before = "Who was the U.S. president when the first person walked on the moon, and what was the name of that astronaut?"
messages = [
{"role": "system", “内容”: DEFAULT_SYSTEM PROMPT},
{"role": "user", “内容”: create_user_content(user_prompt_before)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Richard Nixon was the U.S. president when the first person walked
on the moon. The first astronaut to walk on the moon was Neil Armstrong.
1B LLaMA 模型可能直接记住了这个信息,能够回答这个问题。
然而,对于更复杂的问题,如果它没有“预先编译”答案,直接的方法可能会失败,或者产生一个不太自信的答案。我们看不到它是如何连接这些事实的。
现在,让我们引导 1B LLaMA 通过明确阐述一个“思考、行动、观察”的过程来回答同样的问题,就好像它在使用工具或数据库一样。
user_prompt_after = (
"Answer the following question: 'Who was the U.S. president when the first person walked on the moon, and what was the name of that astronaut?'\n\n"
"To answer this, please follow a ReAct-like process. For each step, state:\n"
"Thought: [Your reasoning or plan for the next step]\n"
"Action: [The specific information you need to find or the sub-question you need to answer, as if you were querying a tool or database]\n"
"Observation: [The hypothetical result or answer to your Action]\n\n"
"Continue this process until you have all the information to answer the main question. Then, provide the final answer."
)
messages = [
{"role": "system", “内容”: “You are a helpful assistant that solves problems by thinking step-by-step, simulating actions, and observing results.”},
{"role": "user", “内容”: create_user_content(user_prompt_after)}
]
response = call_llm(messages)
print(response)
### 输出 ###
Okay, I will answer the question using a ReAct-like process.
Thought: The question has two parts. First, ... [截断]
ReAct 风格的提示迫使 1B LLaMA 将主问题分解为更小的、可管理的子问题(找到日期,然后找到总统,然后找到宇航员)。
“行动”和“观察”步骤模拟了查询信息的过程。这使得 LLM 的内部“知识查找”更加明确。
思维线索(Thread-of-Thought, ThoT)
它专注于鼓励 LLM 在对话的多个回合或整个长篇生成文本中保持连贯且相互联系的推理线或叙述线。
ThoT 对于以下场景至关重要:
- 长篇内容生成:撰写论文、文章、报告或故事章节,其中在多个段落中保持连贯性至关重要。
- 复杂解释:确保多部分的解释易于理解且逻辑连贯。
- 多轮问题解决:在几个交互步骤中跟踪约束条件、中间结果以及整体目标。
- 扩展对话:帮助 LLM 记住关键点并在更长的对话中保持专注于用户的主要目标。
- 辩论或论证性写作:确保论点逻辑连贯且一致。
假设我们让 1B LLaMA 解释一个复杂的流程,比如“在美国,法案如何成为法律”,但没有具体指导如何保持清晰的线索。对于一个很长的解释来说,较小的模型可能会开始偏离主题或丢失对主要阶段的关注。
如果只是被要求“解释法案如何成为法律”,1B 模型可能会:
- 提供一个步骤列表,但没有清楚地说明一个步骤如何导致下一个步骤。
- 在一个步骤(例如,委员会工作)上偏离主题,丢失整体流程。
- 使用不一致的术语或忘记定义之前引入的关键术语。
- 解释可能会感觉支离破碎,像是一堆事实,而不是一个连贯的流程叙述。
与其一次性给出一个庞大的提示,我们可以通过模拟引导 LLM 逐节进行,或者要求它用清晰的过渡语来结构化其解释,专注于“线索”。
user_prompt_after = (
"I need a clear explanation of how a bill becomes a law in the US.\n"
"Please structure your explanation as follows:\n\n"
"1. **Introduction:** Briefly state the overall purpose of the legislative process.\n"
"2. **Bill Introduction:** Explain who can introduce a bill and where.\n"
"3. **Committee Stage:** Describe what happens in committees and why this stage is important. Ensure you explain how this connects to the previous step.\n"
"4. **Floor Action (House/Senate):** Detail the debate and voting process in one chamber. Explain how a bill gets from committee to the floor.\n"
"5. **Action in the Other Chamber:** Explain that the process is repeated and what happens if versions differ. Clearly link this to the previous chamber's action.\n"
"6. **Conference Committee (if needed):** Explain its role in reconciling differences.\n"
"7. **Presidential Action:** Describe the President's options (sign, veto, pocket veto) and the consequences.\n"
"8. **Overriding a Veto (if applicable):** Explain this final potential step.\n\n"
"Throughout your explanation, ensure each stage logically follows the previous one, maintaining a clear 'thread' of the bill's journey. Use clear transition phrases."
)
messages = [
{"role": "system", "conten": "You are an expert in explaining complex governmental processes clearly and logically."},
{"role": "user", "conten": "create_user_content(user_prompt_after)"}
]
response = call_llm(messages) # 这将是一个很长的回应
print(response)
### 输出 ###
Okay, here is an explanation of how a bill becomes a law in the US,
following the requested structure and maintaining a clear thread:
**1. Introduction:**
The legislative process in the United ...
通过明确要求一个结构化的提纲,并指示 LLM 确保逻辑连贯并使用过渡语,得到的解释更加连贯且易于理解。整个法案的“线索”得以保持。
总结
我们已经深入探讨了 17 种不同的提示工程技巧,看看它们如何帮助我们即使在 1B LLaMA 模型上也能获得更好的结果。从简单的零样本到更复杂的 ReAct,每一种技巧都提供了引导 AI 的独特方式。
你还将接触到一些令人兴奋的概念,例如:
- 思维树(Tree-of-Thought, ToT):让 LLM 探索多条推理路径并自我评估。
- 自我一致性:通过生成多条推理路径并进行多数投票来提高推理能力。
- 指令调整风格提示:利用模型在指令上进行微调的具体方式。
- 角色校准提示:更精确地调整角色的行为。
- 多角色对话提示:模拟多个 AI 角色之间的对话。



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











