






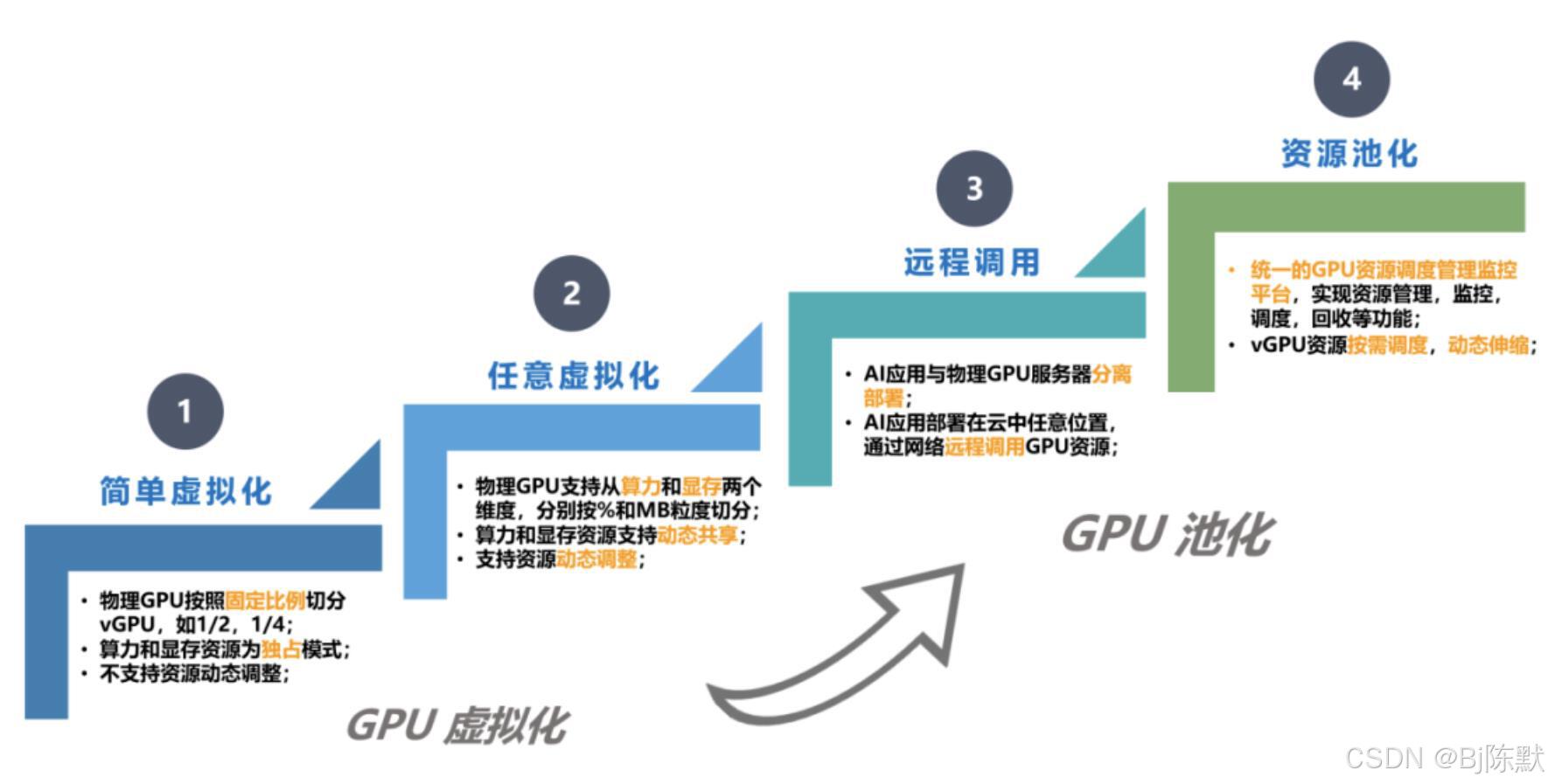
一、什么是GPU虚拟化
(一)定义
GPU虚拟化是一种将物理GPU(图形处理器)资源分割成多个虚拟GPU的技术,使得多个用户或虚拟机(VM)能够共享同一个物理GPU,就好像每个用户或VM都拥有自己独立的GPU一样。
(二)目的
1. 资源利用率提升
在数据中心等环境中,物理GPU设备价格昂贵。通过GPU虚拟化,可以让多个用户或应用同时使用一个GPU,避免资源闲置,从而提高硬件资源的投资回报率。例如,在一个深度学习训练的集群中,多个研究小组可能在不同时段有不同的模型训练任务,GPU虚拟化允许这些小组共享昂贵的GPU资源。
2. 隔离性保障
尽管多个用户或应用共享GPU,但每个虚拟GPU在功能上是相对独立的。这意味着一个用户或应用的操作不会对其他用户或应用的GPU使用产生干扰。就像在一栋公寓楼里,每个房间(虚拟GPU)有自己的空间,住户(用户或应用)可以在自己的房间内自由活动,不会轻易影响到其他住户。
二、GPU虚拟化的类型
(一)时分复用(Time Division Multiplexing,TDM)
1. 原理
TDM是一种基于时间片的虚拟化方式。物理GPU的时间被划分成多个时间片,每个虚拟GPU按照一定的顺序轮流使用这些时间片。例如,假设有3个虚拟GPU(vGPU1、vGPU2、vGPU3),物理GPU的时间片分配可能是vGPU1使用10ms,然后vGPU2使用10ms,接着vGPU3使用10ms,如此循环。
2. 特点
简单性:实现相对简单,技术成熟。它在概念上类似于CPU的时间片轮转调度。
性能局限:由于每个虚拟GPU只能在自己分配的时间片内使用GPU,当某个虚拟GPU的任务需要连续的大量时间来处理时,性能可能会受到影响。例如,在进行大规模的图形渲染任务时,如果时间片过短,渲染可能会频繁中断,导致渲染效率降低。
(二)空间复用(Space Division Multiplexing,SDM)
1. 原理
SDM是将物理GPU的资源(如显存、计算单元等)在空间上划分成多个部分,每个部分分配给一个虚拟GPU。以显存为例,物理GPU的显存可能被划分为几个区域,每个区域分配给一个不同的虚拟GPU,使得每个虚拟GPU有自己独立的显存空间来存储数据和纹理等。
2. 特点
资源分配灵活:可以根据不同虚拟GPU的需求灵活分配物理GPU的资源。例如,对于一个对显存要求高但对计算单元要求相对较低的图形应用和一个对计算单元要求高但对显存要求较低的深度学习应用,可以通过SDM方式合理分配物理GPU的显存和计算单元,使两个应用都能较好地运行。
资源划分复杂:需要精确地划分物理GPU的各种资源,而且不同GPU的架构不同,资源划分的难度和方式也有所不同。同时,资源划分后可能会存在一定的碎片化问题,影响整体资源的利用效率。
(三)混合复用(Hybrid Multiplexing)
1. 原理
混合复用结合了时分复用和空间复用的特点。它既在时间上对物理GPU进行切片,又在空间上对GPU资源进行划分。例如,先将物理GPU的显存按照一定比例划分给不同的虚拟GPU,然后在时间片分配上也根据不同虚拟GPU的任务优先级等因素进行分配。
2. 特点
性能优化:能够综合时分复用和空间复用的优点,更好地满足不同类型应用的需求。对于既有对实时性要求高的图形渲染任务,又有对资源独占性要求高的深度学习任务的场景,可以通过混合复用方式提供更优化的性能。
管理复杂:由于结合了两种复用方式,其管理和配置相对复杂。需要考虑时间片分配和空间资源分配的协同,以及如何根据应用的动态变化调整分配策略等问题。
三、GPU虚拟化的关键技术
(一)驱动层虚拟化
1. 工作方式
在驱动层进行虚拟化,主要是通过修改GPU驱动程序,使它能够识别和管理多个虚拟GPU。驱动程序负责将物理GPU的资源分配给各个虚拟GPU,并处理虚拟GPU的请求。例如,当一个虚拟GPU发出一个绘制三角形的指令时,驱动程序会根据虚拟GPU的资源配额,将这个指令转发给物理GPU,并协调物理GPU的资源来完成这个操作。
2. 优势
兼容性好:可以利用现有的GPU硬件和大部分软件应用。因为很多应用是通过GPU驱动来与GPU进行交互的,通过驱动层虚拟化,只要应用符合驱动的接口规范,就可以在虚拟化环境中运行。
性能较高:由于驱动直接管理物理GPU资源分配给虚拟GPU,减少了中间层的开销,相对来说可以提供较高的性能。
(二)中间件虚拟化
1. 工作方式
中间件虚拟化是在操作系统和GPU驱动之间插入一个中间件层。这个中间件层负责对物理GPU资源进行虚拟化处理,将其转换为多个虚拟GPU提供给上层应用。中间件会拦截应用对GPU的请求,根据虚拟化策略重新分配资源并转发请求。例如,中间件可能会根据应用的优先级和资源需求,将应用的请求分配到合适的虚拟GPU时间片或者空间区域。
2. 优势
灵活性高:可以在不修改GPU驱动和操作系统的情况下实现GPU虚拟化。这对于一些无法修改驱动或者操作系统的环境非常有用。同时,中间件可以方便地实现不同的虚拟化策略,如根据用户的付费等级分配不同质量的虚拟GPU服务。
易于管理:可以通过中间件对虚拟GPU进行集中管理,包括资源分配、性能监控等。管理员可以通过中间件的管理界面方便地调整虚拟化策略,如增加或减少某个虚拟GPU的资源配额。
四、GPU虚拟化的应用场景
(一)云计算
1. 图形处理即服务(Graphics Processing as a Service,GPaaS)
在云计算环境中,用户可以通过互联网访问云端的虚拟GPU资源来进行图形处理。例如,一些小型的设计公司可能没有足够的资金购买高端的GPU设备,他们可以租用云端的虚拟GPU来完成3D建模、动画制作等图形处理任务。
2. 深度学习即服务(Deep Learning as a Service,DLaaS)
深度学习任务通常需要大量的计算资源,包括GPU。通过GPU虚拟化,云服务提供商可以将物理GPU分割成多个虚拟GPU提供给不同的深度学习用户。这样,研究人员和开发者可以在云端利用虚拟GPU资源进行模型训练和推理,无需自己搭建复杂的GPU集群。
(二)企业数据中心
1. 多用户图形工作负载共享
在企业的数据中心中,可能有多个部门或员工需要使用GPU进行图形相关的工作,如CAD设计、图形渲染等。GPU虚拟化允许这些用户共享物理GPU资源,提高资源的利用效率,同时保证每个用户的工作不受其他用户的干扰。
2. 混合工作负载处理
企业数据中心可能同时有图形处理和深度学习等不同类型的工作负载。GPU虚拟化可以通过混合复用等方式,合理分配物理GPU资源,使得不同类型的工作负载都能得到有效的处理。


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











