






1.关键短语提取
关键短语提取是自然语言处理中的一个子任务,指的是自动提取能够语义上抓住文档关键主题和内容的显著术语。
2.无监督方法
所有无监督关键短语提取方法展示了一些共同属性,这些属性属于以下几类:
① 统计方法(例如,共现矩阵中术语的频率)
②基于图的方法(例如,PageRank算法或术语图中的术语共现)
③位置方法(例如,出现在文档开头较近的术语更为重要)
④语言学方法(例如,通过使用词性标签只保留名词短语作为候选关键短语)
⑤聚类/主题建模技术(例如,潜在狄利克雷分配LDA)
⑥语义知识(例如,使用外部知识库,如维基百科,或使用预训练的词/句子嵌入)
2.1 传统方法
-
统计方法:
- KP-Miner:利用TF-IDF得分和两个统计特征(术语首次出现位置和最小出现次数)对候选关键短语进行筛选和排序。
-
基于图的方法:
- TextRank:是最早的基于图的关键短语提取方法,利用PageRank算法对文档中的术语进行排序。
- PositionRank:一种混合方法,结合了统计特征(术语位置)和基于图的方法,通过偏置PageRank来对关键短语排序。
- MultiPartiteRank:结合了图模型和主题建模技术,通过构建多部分图并调整边权重,提升了关键短语提取的效果。
- YAKE!:利用多种统计指标(如术语大小写、位置、频率等)计算候选关键短语的得分,得分越低,关键短语的质量越高。
2.2 基于嵌入的关键术语提取方法
传统的关键术语提取方法未能捕捉文本中术语之间的语义关系。这些关系可以通过词嵌入来建模,词嵌入能够捕捉文本术语之间的相似性。
WordAttractionRank 是一种基于图的无监督关键术语提取方法,结合了预训练词嵌入和统计测量。其主要步骤包括:首先,对输入文档进行分词和词性标注,然后构建术语图,术语作为节点,节点间的连接表示共现关系。接着,通过计算词吸引力分数(利用词频和词嵌入向量的欧氏距离)来衡量术语对的关系强度。最终,使用加权TextRank算法计算每个术语的排名分数,并提取高排名的关键短语。优点在于能够捕捉术语间的语义关系,提升关键术语提取的准确性。缺点是该方法计算复杂,处理时间较长,且在处理稀疏数据时效果可能不佳。
Personalized PageRank 是基于图的无监督方法,结合了词嵌入和个性化PageRank算法。步骤包括:对输入文本进行预处理,提取名词和形容词;然后构建术语的共现图,并通过计算语义相关性和共现系数来加权图的边。接着,使用个性化PageRank算法对术语进行排名,提取前N个关键短语。优点在于其语义相关性和共现信息的结合,有助于提高关键术语提取的精确度。缺点是计算量大,可能在大规模文档上性能较低,同时对词嵌入的依赖可能限制其在多语言或特定领域的适用性。
Reference Vector Algorithm (RVA) 是一种基于统计的嵌入方法,用于关键术语提取。其步骤包括:首先从文档中生成GloVe词嵌入,然后计算文档标题和摘要的平均嵌入作为参考向量,代表文档的整体语义。接着,从标题和摘要中提取n-gram作为候选关键短语,并基于其与参考向量的余弦相似度进行排名。优点在于其简洁性和高效性,特别适合短文本的关键术语提取。缺点在于对标题和摘要的依赖性较强,可能忽略长文本中的重要术语,同时对于领域特定语言的语义信息提取较为有限。
SIFRank 是一种结合了SIF和BERT嵌入的无监督关键术语提取方法。其步骤包括:首先通过依存句法分析从输入文本中提取名词短语作为候选关键短语;然后计算每个候选短语的SIF加权嵌入,利用BERT生成上下文感知的嵌入;接着,计算候选短语与文档嵌入之间的余弦相似度并排序。优点是结合了深度学习嵌入的优势,能够捕捉丰富的语义信息,在复杂文本中表现尤为优异。缺点是需要依赖BERT等大型预训练模型,计算资源需求较高,处理较长文档时效率可能下降。
SIFRank/SIFRank+ 是基于SIF嵌入和ELMo预训练模型的无监督方法,特别针对短文档(SIFRank)和长文档(SIFRank+)进行优化。核心步骤包括:文档分词并生成词性标签;提取名词短语序列;生成每个标记的嵌入向量并计算候选短语的SIF嵌入;最后,计算候选短语与文档嵌入之间的余弦相似度并排序。SIFRank+还引入了基于位置的加权机制来处理长文档。优点在于其灵活性和对不同文档长度的适应性,同时引入位置加权进一步提升准确性。缺点是计算复杂度较高,尤其是长文档可能导致处理时间增加。
KPRank 是一种混合方法,结合了基于图的PageRank和基于嵌入的语义相似度计算。步骤包括:利用SciBert生成文档的词嵌入并计算主题向量;然后构建术语共现图,计算术语与主题向量的余弦相似度以及术语的位置信息;接着,使用有偏PageRank算法对术语进行排名。优点是将语义信息和位置信息结合,能够更好地反映术语的重要性,适用于科学文献等结构化文本。缺点是需要依赖预训练的领域特定模型(如SciBert),可能在领域外的文本中表现不佳。
KeyBERT 是一种基于嵌入的关键术语提取方法,它利用预训练的Transformer语言模型生成文本和候选关键词的嵌入表示。其步骤包括:首先为每个文档创建n-gram列表及其频率;然后,使用基于Transformer的模型(如MPNet)生成候选关键词和整个文档的嵌入向量;接着,计算候选关键词嵌入与文档嵌入之间的余弦相似度,并按相似度对关键词进行排序;最后,通过一个关键词列表多样化步骤(如MMR或Max Sum Similarity)来确保关键词的多样性。优点在于它能够生成上下文感知的关键词,提升了关键词提取的准确性和相关性,尤其是在语义丰富的文本中表现突出。缺点是其依赖于预训练模型,可能在特定领域的文本中表现欠佳,同时计算嵌入的过程也较为耗时。
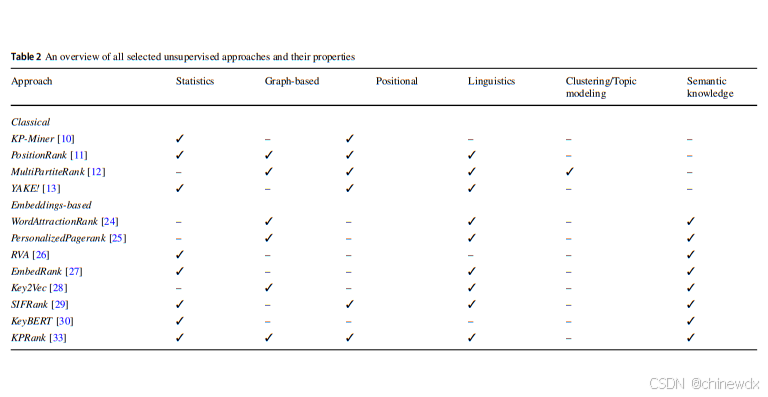
无监督方法属性的比较概览
3.监督方法
一些监督学习的关键术语提取方法将关键术语提取问题视为二分类问题,其中需要将一组预定的短语分类为两个二分类类(关键术语/非关键术语)。最近的文献综述表明,监督方法比无监督方法获得更高的F1分数。然而,这些监督方法在训练和部署方面存在两个主要缺点:(i) 语料库中的每个文档都需要手动分配的关键术语,从而阻碍了KE的完全自动化;(ii) 这些方法不是领域独立的,因为在处理不同主题或自然语言的文本时,需要重新训练。
所有监督关键短语提取方法也展示了一些共同属性,这些属性属于以下几类:
①统计(例如,共现矩阵中术语的频率)
②位置(例如,出现在文档开头较近的术语更重要)
③语言学(例如,通过使用词性标签仅保留名词短语作为候选关键术语)
④上下文(标记的顺序和相对接近度)
⑤语义知识(例如,使用外部知识库,如维基百科,或使用预训练的词/句子嵌入)
3.1传统方法
KEA 利用TF-IDF的无监督方法形成候选关键术语。它还使用每个候选关键术语之前的单词数量与文档中总单词数量的比值。这两个特征(TF-IDF和上述比值)结合在一起,用于训练朴素贝叶斯分类器。
Maui 在KEA方法的基础上进行了改进。它使用了不同的分类模型,训练了不同的特征,并使用了由维基百科知识库提供的上下文信息。这些特征包括:①候选关键术语首次出现的位置;② 其TF-IDF得分;③ 其长度;④ 在训练数据中的频率;⑤ 在文本中首次和最后一次出现之间的单词数量;⑥ 其与其他关键术语的语义相关性,以维基百科术语的超链接图中的节点度数来衡量;⑦其逆维基百科链接,即链接到相应关键术语的文章数量与知识库中总文章数量的比值。
3.2深度学习监督方法
深度学习已被广泛应用于NLP领域,用于解决各种文本任务,包括与关键术语抽取密切相关的关键术语生成任务。这些方法相比于传统方法表现出更好的性能,因而成为监督学习的最新技术。总体而言,深度学习方法考虑使用深度神经网络模型,通过多层表示学习的非线性组合来处理各种学习任务。这些网络模型包括输入层、输出层和多个中间隐藏层。靠近输入层的层学习简单特征,而靠近输出层的层则从前一层学习复杂特征。
Joint Layer RNN 是一种基于RNN的方法,具有两层隐藏层。第一层从关键词中收集信息,第二层利用序列标注方法提取关键术语,基于前一层的信息。在输入层,该方法利用预训练的词嵌入,用它们构建术语共现矩阵,并在训练过程中调整其权重。该方法不仅能提取关键术语,还能利用附近短语的上下文信息,因此比以前的方法表现更好。
CopyRNN是一种基于RNN的方法,能够捕获文本的语义信息。首先,构建源序列(输入文本的术语)和目标序列(训练数据集中的关键术语)的对。每对包含一个源序列和一个目标序列。然后,编码器RNN使用非线性函数将这些信息编码到隐藏层表示中。解码器RNN利用这些表示,根据输入和隐藏层的学习表示生成目标序列。这两个RNN模型一起训练,最大化在训练数据集中给定源序列预测目标序列的概率。为了改进生成的结果,该方法使用了复制机制,识别训练数据集中未包含在当前文档词汇中的重要术语序列,并将其复制到输出中。该机制基于文本的上下文信息生成关键术语,从而减轻了“缺失关键术语”的问题。这些关键术语是与文本高度相关但未在文本中出现的术语序列。
CopyCNN 是一种基于CNN的方法,采用与CopyRNN相同的概念,在给定输入序列(文档术语)的情况下,最大化正确预测目标序列(关键术语)的概率。CopyCNN构建源序列和目标序列的术语对。对于输入层,使用预训练的词嵌入。编码器和解码器CNN共享一个共同的隐藏层表示,该层对输入执行非线性卷积转换。为了预测原始文档中未出现的缺失关键术语,它使用与CopyRNN类似的复制机制。与等效的RNN方法相比,他们的方法在执行时间上表现更好。
CorrRNN是一种基于RNN的方法,通过覆盖机制和复审机制捕捉关键术语之间的相关约束。覆盖机制确保捕捉文档的所有主题,而复审机制确保关键术语的唯一性和非重复性。具体而言,覆盖机制捕捉先前关键术语已经覆盖的文档部分,并在未来的关键术语中忽略这些部分;复审机制利用先前生成的关键术语的上下文信息避免重复生成。CorrRNN的步骤与CopyRNN非常相似,包括使用复制机制预测原始文档中未出现的缺失关键术语。
双向LSTM RNN 是一种基于LSTM的方法,能够利用每个术语的前后上下文。该方法不需要每个领域的特定手工制作特征,因此是领域不可知的。首先,该方法将文档拆分为术语,并为每个术语使用预训练的词嵌入。这些嵌入被输入到双向LSTM单元中,这些单元捕捉特定特征及其上下文。这些单元完全连接到一个隐藏层,该层连接到使用SoftMax函数的输出层。输出层有三个神经元,用于分析每个术语。这些神经元将术语分类为三类(“不是关键术语”、“关键术语的第一个标记”、“关键术语的其他标记”)。
TANN(基于主题的对抗神经网络)是另一种依赖于GAN模型的深度学习KE方法。该方法的新颖之处在于将知识从具有大量标签示例的领域转移到仅有少量标签的领域,从而缓解了其他深度学习监督方法需要大量标签数据才能有效训练的问题。与前面提到的方法一样,TANN将KE问题视为序列标注问题,输入序列被标注为是否属于最终输出中的关键术语。该方法包括四个组件,即基于主题的编码器、领域鉴别器、目标双向解码器和关键术语标注器。基于主题的编码器将输入术语转换为等效的词嵌入。然后,这些嵌入被双向LSTM模型处理,该模型捕捉文档术语序列的上下文信息。该模型的输出作为输入提供给主题相关层,该层考虑文档的全局信息以提取其主要主题。该层具有主题相关机制,选择性地偏好与当前文档主要主题更相似的术语。领域鉴别器使用对抗CNN模型,确保学习的特征具有不变性,因此能够很好地跨不同领域进行泛化。最后,关键术语标注器接收由基于主题的编码器生成的输出表示,以预测原始文本中每个术语的标签。
Bi-LSTM-CRF是一种结合了双向LSTM(bi-LSTM)和条件随机场(CRF)的混合方法,已被证明可以在包括KE在内的各种任务中提高准确性。该方法将KG问题简化为序列标注问题。首先,它利用预训练的词嵌入对文档的术语进行建模。其次,对于每个输入向量(术语),该方法旨在预测一个标签,捕捉它是否是关键术语的一部分。为此,该方法使用bi-LSTM模型生成这些标签。与早期的LSTM方法相反,Bi-LSTM-CRF双向捕捉信息流。第三,该方法将bi-LSTM层的输出输入到CRF层;这两个模型的结合使得能够将输入到输出的长距离信息纳入考虑。
DivGraphPointer 是一种基于CNN和图的混合方法。首先,该方法构建一个术语图,捕捉图中唯一术语之间的短期和长期依赖关系。然后,图卷积神经网络(GCNN)应用于该图,模型每个术语的重要性。与上述方法类似,DivGraphPointer采用编码器-解码器模型,使用术语图作为输入层。具体而言,GCNN的编码器学习图的底层信息表示,解码器(一个多样化指针网络模型)动态地从词图中选择节点以生成关键术语。作者认为,传统的深度学习模型(如RNN、CNN)严重依赖术语序列,忽略了术语之间的中间依赖关系。图基模型通过汇集词图中唯一术语的信息来捕捉这些依赖关系。为了确保生成关键术语的多样性,DivGraphPointer使用类似于CopyRNN的复制机制和动态修改文档表示的机制。
ExHiRD 是一种依赖于GRU(门控循环单元)模型的方法,与LSTM相似。ExHiRD构建了一个包含软或硬排除机制的层级解码框架。该过程对关键术语集合的层级组成进行建模。两个排除机制在一个窗口大小内记录先前预测的关键术语,以增强生成关键术语的多样性。ExHiRD首先利用两层双向GRU学习每个输入词嵌入的上下文表示。然后,它构建一个层级解码器,包括一个短语级和一个词级解码器。这两个解码器都建模为单向GRU,捕捉术语的上下文信息。最后,对解码器输出应用软或硬排除机制,生成最终的关键术语列表。
CatSeq/CatSeqD是一对基于RNN的方法,构建在seq2seq模型基础上。CatSeqD相比于CatSeq的主要区别在于使用了语义覆盖机制和正交正则化。两种方法遵循相同的基础方法。首先,它们将训练数据集中多个关键术语连接成一个包含分隔符标记的序列,然后使用经典的RNN编码器-解码器模型生成序列。为避免之前RNN方法中的缺点,即由于生成类似输出而导致的重复关键术语,CatSeq/CatSeqD引入了一套机制以确保关键术语的多样性。第一个是语义覆盖机制,在解码器末尾添加一个GRU模型。该机制确保生成的序列在语义上与文档接近。第二个是正交正则化,生成不同的输出形式以确保关键术语的多样性。最后,在解码步骤中,模型遵循自终止技术,动态估计生成短语的数量,然后停止解码过程。这种技术的主要优点是,通过在一次传递中生成一组短语,模型基于所有先前生成的短语来确定当前生成的输出。
TNT-KID 是一种基于Transformer的方法,修改了原始的GPT-2模型。首先,该方法依赖于原始模型的两个独立训练阶段,语言预训练阶段和在特定数据集上的手动标签微调阶段。其次,注意力机制也进行了修改,包含了标记的位置,而不仅仅是预训练步骤中获得的嵌入表示。这一步是为了建模文本中术语之间的相对位置信息。作者还替换了原始模型的标准输入嵌入和SoftMax层,使用自适应模型。与GPT-2尝试预测整个词汇的概率分布不同,TNT-KID使用自适应模型预测词汇簇的概率分布以及更常出现的术语。这一修改大大减少了模型的内存需求和时间复杂度,性能仅略有下降。在微调阶段,TNT-KID优化为标记分类,使用双向LSTM-CRF模型,这在早期研究中观察到准确性有所提高。
KeyBART 是一种基于Transformer的方法,基于原始BART[57]模型进行训练,适用于各种文本生成任务(如抽象摘要、问答等)。作者提出了一种称为关键术语替换分类(KRC)的技术,基于掩码语言建模(MLM)技术。这种技术用< MASK >标记替换输入文本的标记,BART在预训练阶段尝试预测这些标记。KRC与MLM的不同之处在于,它不是替换单个标记,而是替换标记跨度;这种技术使方法不仅学习上下文特征,还学习位置特征(例如关键术语的起始和结束标记、其标记数量等)。这种技术训练了一个语言模型,成功地将文本序列分类为关键术语。尽管使用了“分类”一词,KeyBART在其预训练阶段学习这一生成任务;与其他如TNT-KID的研究相反,它在微调训练步骤中训练一个分类器层以提取重要短语。
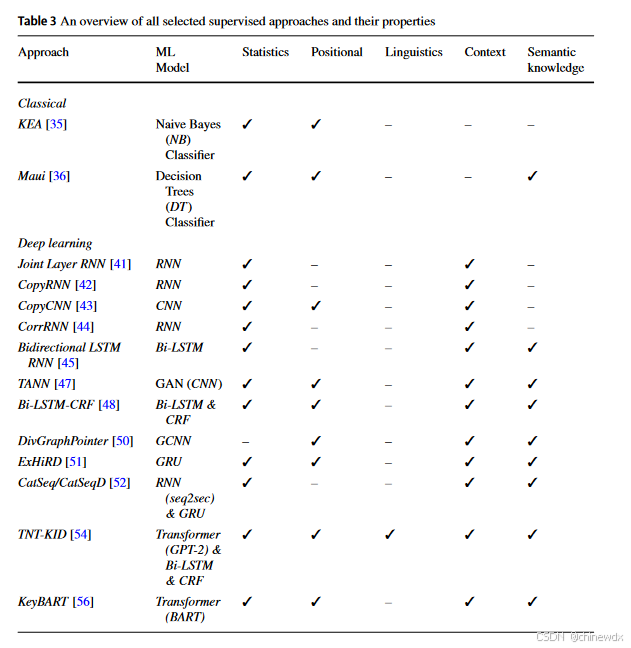
监督方法属性的比较概览
4.实验
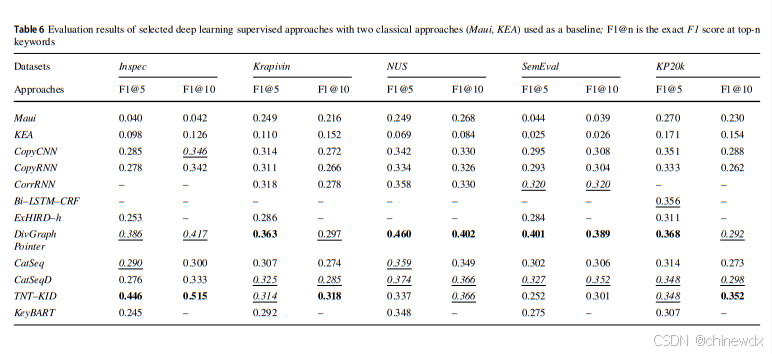
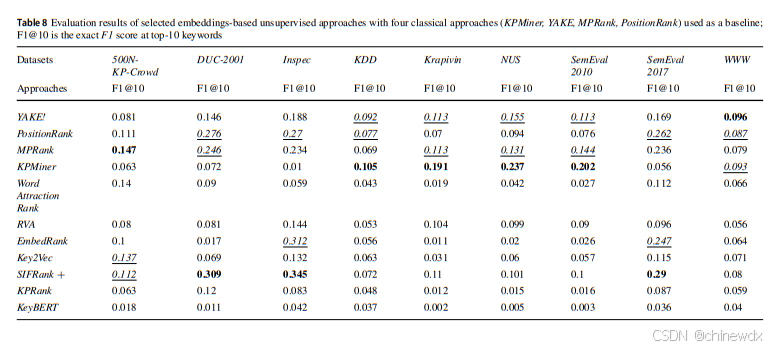
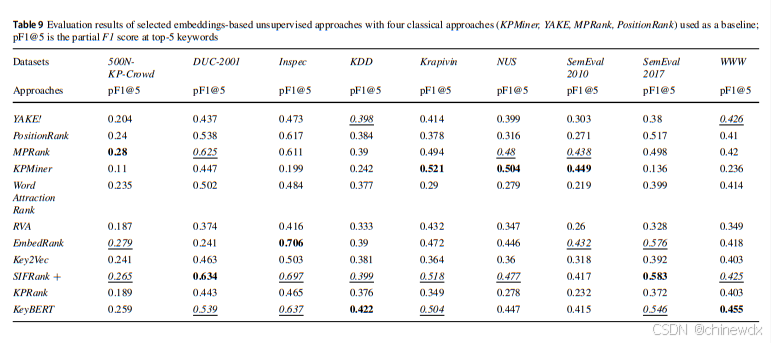
对于监督方法,使用前5和前10个关键短语的F1分数来评估KE方法。
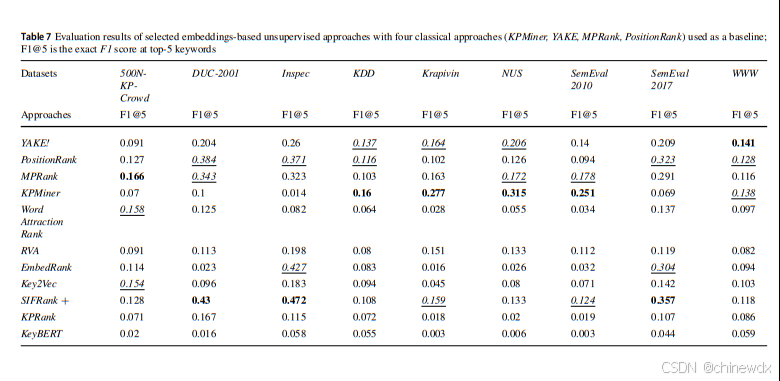
对于基于嵌入的无监督方法使用前5和前10个关键短语的F1和pF1分数来评估基于嵌入的方法。
- 精确率(Exact Precision)= 完全匹配的关键短语数量 / 提取的关键短语总数
- 召回率(Exact Recall)= 完全匹配的关键短语数量 / 分配的关键短语总数
- F1=2⋅exact precision⋅exact recall /exact precision+exact recall
- 部分精确率(Partial Precision)= 部分匹配的关键短语数量 / 提取的关键短语总数
- 部分召回率(Partial Recall)= 部分匹配的关键短语数量 / 分配的关键短语总数
- pF1=2⋅partial precision⋅partial recall/partial precision+partial recall
F1分数计算为准确率和召回率的调和平均数 、pF1分数定义为部分精确率和部分召回率的调和平均数
完全匹配的关键短语数量定义为机器提取的关键短语与人工分配的关键短语之间交集的长度。两个集合成员之间的比较标准是字符串的精确表示。这一标准是精确匹配分数的主要限制,因为尽管具有高度相似性,共享相似词语的关键短语不计为匹配。相反,pF1分数缓解了这一问题。部分匹配的关键短语数量定义为机器提取的关键短语与人工分配的关键短语部分字符串匹配的数量。

5.总结
5.1讨论
①深度学习方法在很大程度上优于经典的监督方法。
②DivGraphPointer 是表现最好的深度学习方法,紧随其后的是基于Transformer的TNTKid。这个发现有两个有趣的原因:(i) 这两种方法都使用了多模型组合;(ii) 后者依赖于Transformer模型,这种模型在某些数据集中表现优于CNN。
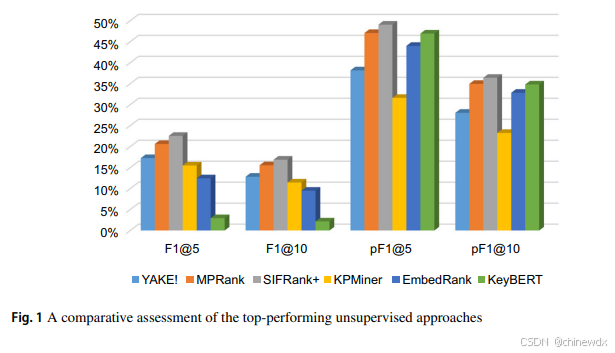
③基于嵌入的无监督方法大多数优于选定的经典方法,除了KPMiner作为一个强基线,在少数数据集中仍略胜一些基于嵌入的方法。
④SIFRank+ 是表现最好的基于嵌入的方法。
⑤部分匹配评估框架使我们能够评估无监督方法,而不会因为生成与人工分配的关键短语相似(但不完全相同)的关键短语而惩罚它们。
⑥不同领域和主题的数据集确实会影响KE方法的性能。
5.2Future
①测试利用更大预训练模型的基于嵌入的方法的潜力,以生成捕捉更多上下文的嵌入。
②调查改进的基于Transformer的模型和更大注意力机制的深度学习方法的性能。
③调查新兴生成式人工智能技术(即大语言模型-LLMs)在KE任务中的性能。
④提供并实验非英语数据集,以测试各种KE方法在多语言环境中的性能。
⑤制定不同领域和主题的数据集,以促进KE方法的更稳健评估。
⑥利用新的评估框架,通过利用语义表示(例如基于BERT的KE评估框架)将KE方法提取的关键短语与黄金关键短语集进行匹配。这将使具有不同字符串表示的同义关键短语的匹配成为可能,从而克服现有KE评估框架的局限性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









