






前面总结完了html部分的基础内容之后,我总结了一下一下css部分的内容,希望对大家有所帮助~
初识CSS
• css的全称为cascading style sheet 层叠样式表,它的主要作用是为我们的html标签添加各种各样的样式和修饰效果。
• 这里我总结的css属于css2.0的知识点,css3.0的知识我打算在后面的文章里面总结。
• 其实html+css部分的知识点总共站前端的知识总量的1%-2%,但是却占了20%-30%的重要度,所以我们一定不能轻视html和css。(这是针对最近网上有很多人学习前端忽视html和css说的…)
首先我们要介绍一下,html页面如何引入我们的css样式
css的引入方式一共有4种:
1.行间样式 直接在html 的标签里面写style属性 前面两篇里面的更改标签的样式都是用的这一种方式
2.页面级css 在head标签里面添加一个style标签
<style type=”text/css”></style>
这里的style标签的type要不不写,不然就要写正确,只要书写错误,这个样式就不会生效。
3.外部css文件 <—我们选择这种方式
我们在外面创建一个.css后缀的文件,然后在html里面引入这个外部的css文件即可。
在head标签里面加上一个link标签。
<link rel=”stylesheet” href=””>
• link标签里面的href属性上写我们建立的css文件的地址,最好用相对地址的形式。
我们为什么要选择这种加载方式?
因为link加载不会阻塞html的加载,html和css属于异步加载
4.import方式引入(已经弃用)
在head标签里面写一个style标签,在第一行写上@import url();url里面写上css文件的地址,可以加引号也可以不加引号。
这种引入方式有几种缺点导致它现在被废弃使用:
1.必须写在第一行,若有多个则一起写在最前面。
2.ie6的环境下,只能使用最多31次,这个数字据说是阿里的开发人员一点一点测试出来的。
3.程序读到import的时候,会忽略掉import,等到html里面的所有内容包括图片在内的所有资源全都加载完之后才加载import的css文件,也就是说,import引入的css文件和html的加载是同步进行的。
• 这里有一点不得不说明的是,link标签引入和style标签修改样式二者之间并没有什么优先级,谁写在前面谁就先执行,写在后面的css文件会覆盖掉前面的css文件。有时候会因为网速问题,link写在上面,但是link还没有加载进来,所以先运行了后面的style,这种问题是网速导致的,并不是二者本身拥有优先级的问题。
介绍完了如何引入css文件之后,我们再来介绍一下css选择器的知识
• css选择器的作用是让我们找到我们想要修改样式的元素,然后为其修改样式。
我们的选择方式有很多种:
1.id选择器
我们给元素添加一个id属性,这个id是唯一标识,一个元素只能有一个id,一个id也只能给一个元素。然后我们在css文件中,通过#id {}的方式,就可以选择到我们添加id的那个元素了。
<div id=”demo”></div>

CSS; “复制代码”); “查看纯文本代码”); “返回代码高亮”)
2.class类选择器
在元素的属性中写一个叫做class的属性,这个属性是为这个元素添加一个类名,每一个元素可以有多个类名,同一个类名也可以赋给很多个元素。然后我们在css文件中,通过.class {} 的方式来选择出添加了类名的元素。
<div class=”demo”></div>

CSS; “复制代码”); “查看纯文本代码”); “返回代码高亮”)
3.标签选择器
div{} 只要是div的标签就会被选择出来。
• 这里有一个很重要的编程思想:我们先写css在写html,是我们自己在创造标签,而如果我们现在html再写css的话,是我们在添加样式。比如:我们在em加上font-weight: bold;的样式,这样我们就创造了一个加粗斜体的标签。
4.通配符选择器 {} 所有的标签都会被选择出来加上样式,body标签页包含在内。所以如果{background-color: red}的话,那么整个页面都会变红,因为我们同时给body元素也添加了背景颜色。
• 我们在单独的样式后面加上 !important之后,这个样式就会被赋予最高级的优先级,在没有特殊情况下,后面怎么添加样式都不会覆盖或者修改这个样式。比如:background-color: red !important;没有特殊情况的话后面怎么加样式都是红色的。
5.属性选择器
[id] {} 这样有id属性的标签就都会被选择出来。
我经过测试发现:
优先级 !important > 行间样式 > id > class|属性 > 标签 > *
但是我们不必背这些东西,我们只需要记住他们每一种选择器的权重值就可以了。
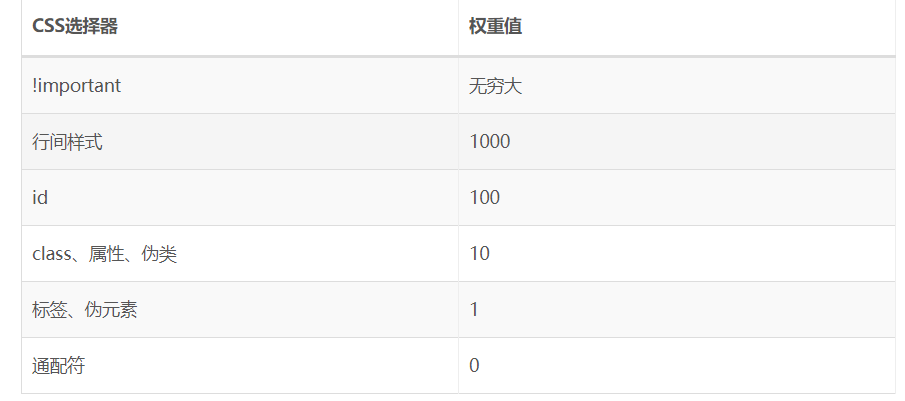
• 值得一提的是,在数学中无穷大+1依然是无穷大,但是在css选择器的权重值里面,无穷大+1 > 无穷大。
有了权重值 我们就可以了解父子选择器了
6.父子选择器 (派生选择器)
div p {}
给div下面的p加样式 这时候的p的权重值是加和的结果。
• 在实际开发中,我们因为要注意浏览器寻找时候的耗能,一般父子选择器不超过4层。
.wrapper .box .content .name 一般不超过像这样的四层。
7.直接子元素选择器
div>strong
div直接子元素里面的strong,div的子元素里面的不是div的直接子元素的strong就不符合要求。
<div>
<strong></strong>
</div>
√
<div>
<em>
<strong></strong>
</em>
</div>
×
id和class也是可以使用父子选择器的哟~
8.并列选择器
<p class=”select”></p>
<div class=”select”></div>
怎么选择出类名是select的div呢?
我们可以使用div.select {} 来选择出来
这种方式是只有div和.select同时作用在一个标签上的时候才会被选择出来,书写的时候标签名放在前面,其他的放在后面。
9.分组选择器
<p></p>
<strong></strong>
<em></em>
<div></div>
我们要想同时给四种标签都加上color: red的样式,不可能把四个标签都写一遍样式,因此要用分组选择器。
div, p, em, strong {} 这样的写法,我们可以把前面写的所有的标签都选择出来加上样式,中间是用逗号连接的。这个样子四种标签就全都被选择出来并且都加上了统一的样式。
最后有一个很重要的问题,那就是父子选择器的时候浏览器是怎么检索的?
div p strong em span 这样的选择器,浏览器是怎么找的?是从左往右,还是从右往左?
答案是从右往左哟~
这是为什么呢?
• 因为如果是从左往右寻找的话,每找到一个父级标签,都要把它下面的所有标签都遍历一遍,看看有没有我们下一个标签,上面那个选择器中,浏览器会先找到div这个标签,然后把div下面所有的子元素都遍历一遍后,找到strong这个标签,然后再把strong这个标签下面的所有元素遍历一遍,找到em这个标签,以此类推,这样是十分消耗性能并且速度非常慢的。
• 而如果是从右往左的话,那么浏览器只需要先找到span标签,然后从span这个节点向上寻找,只要找到em就可以停止寻找,以此类推,不必遍历所有的节点,而且需要遍历的点非常的少,这样的好处显而易见,速度非常快,而且不耗性能。
最后有一些需要说
• 我们一般不给标签加id,而是通过添加class类名来选择的,因为id代表唯一标示,我们一般用id来做标记,后台的php会提取出来id,然后换成他们的标记,因此可能会导致我们的选择器选择不出来我们想要的标签。
• 我们写类名的时候,一定要注意语义化,要符合语义化标准,要用英文单词去命名,而不是用看不懂的abc之类的类名。
希望以上的知识会对大家有所帮助哟~















 489
489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









