






第一次接触kafka及spark streaming,均使用单机环境。后续改进分布式部署。
本机通过virtual box安装虚拟机,操作系统:ubuntu14,桥接方式,与本机通信,虚拟机地址:192.168.56.102,本机地址:192.168.56.101
虚拟机中部署kafka08,下载地址:
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.8.2.1/kafka_2.11-0.8.2.1.tgz
kafka目录,进入config,server.properties中:
取消host.name的注释:修改为:host.name=192.168.56.102
取消advertised.host.name的注释:修改为:advertised.host.name=192.168.56.102
取消advertised.port的注释:修改为:advertised.port=9092
之后开启zookeeper和kafka进程:
zookeeper : ./kafka/bin/zookeeper-server-start.sh ./kafka/config/zookeeper.properties &
kafka : ./kafka/bin/kafka-server-start.sh ./kafka/config/server.properties &
本地搭建spark streaming 开发环境:
新建java工程,引入spark streaming依赖包:
http://d3kbcqa49mib13.cloudfront.net/spark-2.0.1-bin-hadoop2.7.tgz
引入spark-streaming-kafka依赖包:
spark-streaming-kafka_2.11-1.6.3.jar
编写producer程序:
import java.sql.Time;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.ExecutionException;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
public class ProducerTestSample implements KafkaImpl{
/**
*
*/
private static final long serialVersionUID = 3764795315790960582L;
@Override
public void process() {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.56.102:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int result = 0;
int multy = 0;
Random random = new Random();
String[] webPages = {"sina","sohu","amazon","google","facebook"};
System.out.println("Producer Test Start Process");
int k = 1;
while(true){
for(int i = 0; i < 100; i++){
result = random.nextInt(4);
multy = random.nextInt(5);
ProducerRecord<String, String> myRecord = new ProducerRecord<String, String>("test2", i+"", webPages[result] + "|" + multy);
producer.send(myRecord,new Callback(){
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e != null) {
e.printStackTrace();
}
}
});
try {
Thread.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
if(k==40){
break;
}
k++;
}
producer.close();
}
}
因为结果需要持久化到内存中,需要安装redis数据库。
下载地址:
https://github.com/MSOpenTech/redis/releases
按需下载。
编写consumer,并将结果保存到redis中:
package com.ibm.spark.streaming.test;
import java.util.Collection;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.ExecutorService;
import java.util.regex.Pattern;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaPairInputDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.KafkaUtils;
import com.google.common.collect.Lists;
import com.ibm.spark.streaming.redis.RedisUtil;
import kafka.serializer.StringDecoder;
import redis.clients.jedis.Jedis;
import scala.Tuple2;
public class ConsumerSample implements KafkaImpl {
/**
*
*/
private static final long serialVersionUID = -7755813648584777971L;
@Override
public void process() {
//Kafka broker version 0.8.2.1
SparkConf sparkConf = new SparkConf().setAppName("JavaDirectKafkaWordCount").setMaster("local[2]");
JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));
Map<String, Integer> topicMap = new HashMap<>();
String[] topics = {"test2"};
for (String topic: topics) {
topicMap.put(topic, 1);
}
System.out.println("Consumer Start Process");
JavaPairInputDStream<String, String> messages = KafkaUtils.createStream(jssc, "192.168.56.102:2181" ,"0", topicMap);
// Get the lines, split them into words, count the words and print
JavaDStream<String> lines = messages.map(new Function<Tuple2<String, String>, String>() {
/**
*
*/
private static final long serialVersionUID = -5586094486938487203L;
@Override
public String call(Tuple2<String, String> tuple2) {
return tuple2._2;
}
});
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = 5042968941949010821L;
@Override
public Iterator<String> call(String x) {
return Arrays.asList(x).iterator();
}
});
JavaPairDStream<String, Integer> wordCounts = words.mapToPair(
new PairFunction<String, String, Integer>() {
/**
*
*/
private static final long serialVersionUID = -142469460515597388L;
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
}).reduceByKey(
new Function2<Integer, Integer, Integer>() {
/**
*
*/
private static final long serialVersionUID = 3919864041535570140L;
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
wordCounts.foreachRDD(
new VoidFunction<JavaPairRDD<String,Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> arg0) throws Exception {
// TODO Auto-generated method stub
arg0.foreachPartition(
new VoidFunction<Iterator<Tuple2<String,Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> arg0) throws Exception {
Jedis jedis = RedisUtil.getJedis();
while(arg0.hasNext()){
Tuple2<String, Integer> resultT = arg0.next();
System.out.println("(" + resultT._1 + "-----" + resultT._2 + ")");
jedis.lpush("result", "(" + resultT._1 + "-----" + resultT._2 + ")");
}
if(jedis.isConnected())
RedisUtil.returnResource(jedis);
}
});
}
}
);
wordCounts.print();
jssc.start();
try {
jssc.awaitTermination();
} catch (InterruptedException e) {
e.printStackTrace();
}finally{
}
}
}
其中,需要先编写redis的工具类:
package com.ibm.spark.streaming.redis;
import java.io.Serializable;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class RedisUtil implements Serializable{
/**
*
*/
private static final long serialVersionUID = 264027256914939178L;
//Redis server
private static String redisServer = "127.0.0.1";
//Redis port
private static int port = 6379;
//password
private static String password = "admin";
private static int MAX_ACTIVE = 1024;
private static int MAX_IDLE = 200;
//waittime and timeout time ms
private static int MAX_WAIT = 10000;
private static int TIMEOUT = 10000;
private static boolean TEST_ON_BORROW = true;
private static JedisPool jedisPool = null;
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxActive(MAX_ACTIVE);
config.setMaxIdle(MAX_IDLE);
config.setMaxWait(MAX_WAIT);
config.setTestOnBorrow(TEST_ON_BORROW);
jedisPool = new JedisPool(redisServer, port);
} catch (Exception e) {
e.printStackTrace();
}
}
public synchronized static Jedis getJedis() {
try {
if (jedisPool != null) {
Jedis resource = jedisPool.getResource();
return resource;
} else {
return null;
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* release resource
* @param jedis
*/
public static void returnResource(final Jedis jedis) {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
}
之后,编写多线程处理类,调用producer和consumer的process,这样就可以在console中看到输出结果:
-------------------------------------------
Time: 1483597847000 ms
-------------------------------------------
(amazon|2,853)
(sina|3,879)
(sina|1,891)
(amazon|0,880)
(sohu|3,810)
(google|3,920)
(sohu|1,846)
(amazon|4,864)
(google|1,883)
(sina|4,856)
...
-------------------------------------------
Time: 1483597848000 ms
-------------------------------------------
(amazon|2,23)
(sina|3,32)
(sina|1,14)
(amazon|0,15)
(sohu|3,24)
(google|3,25)
(sohu|1,17)
(amazon|4,27)
(google|1,27)
(sina|4,18)
...
-------------------------------------------
Time: 1483597849000 ms
-------------------------------------------
(amazon|2,26)
(sina|3,18)
(sina|1,32)
(amazon|0,31)
(sohu|3,32)
(google|3,29)
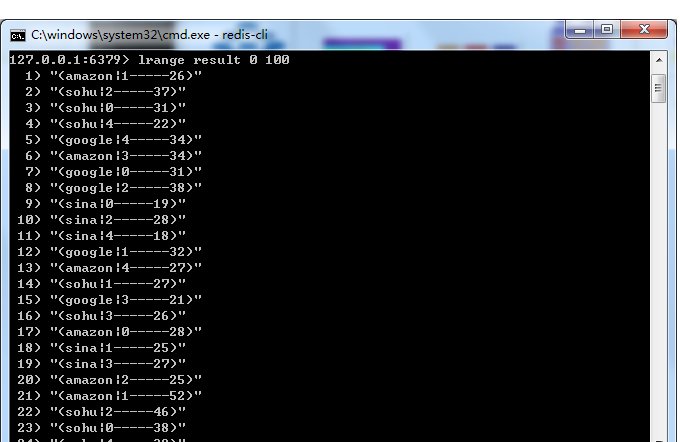
同样,在redis客户端中也能查询到相应的结果:
如有问题,敬请讨论。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









