






目录
SolrCloud配置... 2
简介... 2
Solr 是什么?... 2
配置单机版Solr服务器... 2
1:下载Solr 2
2:部署Tomcat 2
3:将下载的Solr解压,并复制其中example\webapps\solr.war包到指定位置... 2
4:复制example\solr中的solr.xml和zoo.cfg到一个新建文件夹(solrhome)中。... 2
5:在tomcat的conf文件夹下新建Catalina\localhost文件夹,并在其中新建solr.xml,内容如下:... 2
6:启动Tomcat,测试工程。... 2
7:在单机版Solr服务器中添加connection,... 2
配置分布式Solr服务器... 2
1: 参照Solr单机版的配置,配置多台Solr服务器... 2
2:修改主节点... 3
3:修改从节点... 3
5: 在项目中引用... 4
配置Solr服务器集群... 4
1:部署Zookeeper 4
2:部署Solr 5
3:在Zookeeper 中上传Solr的connection配置文件... 6
4:执行命令... 6
5: 创建connection实例... 6
Solr服务器集群的好处... 7
索引(collection)的逻辑图... 8
Solr和索引对照图... 8
创建索引过程... 9
分布式查询... 9
Shard Splitting. 10
SolrCloud配置
简介
Solr 是什么?
Solr它是一种开放源码的、基于 Lucene Java 的搜索服务器,易于加入到 Web 应用程序中。Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。Solr的特性包括:
高级的全文搜索功能 专为高通量的网络流量进行的优化 基于开放接口(XML和HTTP)的标准 综合的HTML管理界面 可伸缩性-能够有效地复制到另外一个Solr搜索服务器 使用XML配置达到灵活性和适配性 可扩展的插件体系
配置单机版Solr服务器
1:下载Solr
http://www.apache.org/dyn/closer.cgi/lucene/solr/
2:部署Tomcat
3:将下载的Solr解压,并复制其中example\webapps\solr.war包到指定位置
4:复制example\solr中的solr.xml和zoo.cfg到一个新建文件夹(solrhome)中。
5:在tomcat的conf文件夹下新建Catalina\localhost文件夹,并在其中新建solr.xml,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<Context docBase="D:\\development\\SolrCloud\\data\\solr\\war\\solr.war" debug="0" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="D:\\development\\SolrCloud\\data\\solr\\solrhome" override="false"/>
</Context>
其中docBase指向solr.war文件,Environment/value 配置为solrhome的路径。
6:启动Tomcat,测试工程。
7:在单机版Solr服务器中添加connection,
(1):在Solr解压的路径example\solr\下找到collection1
(2):将collection1复制到之前配置好的solrhome文件夹中。
(3):重启Tomcat服务器。
配置分布式Solr服务器
1: 参照Solr单机版的配置,配置多台Solr服务器
假设目前存在多台已经配置好的Solr服务器分别为
http://127.0.0.1:8080/solr/connection1
http://127.0.0.1:8081/solr/connection1
http://127.0.0.1:8082/solr/connection1
目前需要设置8080为主机,8081,8082为从机
2:修改主节点
(1):找到需要设置主库的solrhome,找到其中需要设置的核心connection1,例如路径为\example\solr\collection1
(2):打开\conf\solrconfig.xml
(3):修改节点 替换配置中存在的requestHandler/replication和updateHandler
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="master">
<str name="replicateAfter">startup</str>
<str name="replicateAfter">commit</str>
<str name="replicateAfter">optimize</str>
<str name="confFiles">schema.xml</str>
</lst>
</requestHandler>
<updateHandler class="solr.DirectUpdateHandler2">
<autoCommit>
<maxDocs>1</maxDocs>
<maxTime>1000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
</updateHandler>
3:修改从节点
(1):找到需要设置从库的solrhome,找到其中需要设置的核心connection1,例如路径为\example\solr\collection1
(2):打开\conf\solrconfig.xml
(3):修改节点 替换配置中存在的requestHandler/replication和updateHandler
<requestHandler name="/replication" class="solr.ReplicationHandler" >
<lst name="slave">
<str name="masterUrl">http://10.28.175.246:8080/solr/waiter</str>
<str name="pollInterval">00:00:20</str>
</lst>
</requestHandler>
上述操作完成后,一个Solr分布式就完成了,主库主要负责接收插入的数据,从库主要负责查询数据。
从库会在定期(pollInterval配置)到主库进行数据查询,若主库数据有修改,从库会自动进行差异同步。
5: 在项目中引用
<bean id="concurrentUpdateSolrServer" class="org.apache.solr.client.solrj.impl.ConcurrentUpdateSolrServer">
<constructor-arg value=" http://127.0.0.1:8080/solr/connection1" />
<constructor-arg value="8" />
<constructor-arg value="8" />
</bean>
<bean id="lbHttpSolrServer" class="org.apache.solr.client.solrj.impl.LBHttpSolrServer" >
<constructor-arg>
<array value-type="java.lang.String">
<value>http://127.0.0.1:8081/solr/connection1</value>
<value>http://127.0.0.1:8082/solr/connection1</value>
</array>
</constructor-arg>
</bean>
配置Solr服务器集群
本文所讲的Solr集群服务器是基于 Tomcat7 + Zookeeper3.4.6 + Solr4.6
1:部署Zookeeper
(1)下载Zookeeper3.4.6
下载地址为 http://www.apache.org/dyn/closer.cgi/zookeeper/
(2)解压Zookeeper3.4.6 .tar.gz到文件夹中待用
(3)打开conf文件夹,新建文件zoo.cfg(也可以重命名zoo_sample.cfg)
(4)修改zoo.cfg:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=D:\\tmp\\zookeeper\\server1\\data
clientPort=2181
server.1=127.0.0.1:2888:3888
server.2=127.0.0.1:2889:3889
server.3=127.0.0.1:2890:3890
在此示例文件中,我们部署了三分Zookeeper服务器,数据文件分别定位到
D:\\tmp\\zookeeper\\server1
D:\\tmp\\zookeeper\\server2
D:\\tmp\\zookeeper\\server3
其中的server.x中的x为服务器myid(myid随后说在哪里定义),后面的127.0.0.1:2888:3888分别对应与2181
例如,服务器A的clientPort为2181,则对应的地址为127.0.0.1:2888:3888
服务器B的clientPort为2182,则对应的地址应该为127.0.0.1:2889:3889
服务器配置文件 dataDir clientPort
server_1/conf/zoo.cfg D:\\tmp\\zookeeper\\server1 2181
server_2/conf/zoo.cfg D:\\tmp\\zookeeper\\server2 2182
server_3/conf/zoo.cfg D:\\tmp\\zookeeper\\server3 2183
(4):接下来我们该说说myid的问题了
上述文件中我们定义了一个 dataDir 地址,此地址是程序存放数据用的地址,在此地址中,我们定义一个myid文件,用记事本打开,写入1,则此项目的Myid为1
分别将三个服务器按照123进行排列写入myid文件
(5):依次启动Zookeeper服务器
(连接第一台时有异常信息,不用管,等都连接起来就没有异常了)
2:部署Solr
按照Solr单机版的部署方式,部署三台Solr单机版服务器,并去掉其中的所有connection
(1): 配置Solr和Zookeeper关联
假设之前部署好的Zookeeper地址为:
127.0.0.1:2181
127.0.0.1:2182
127.0.0.1:2183
2:部署好的三个solr服务器配置分别为
solr服务器 tomcat端口 solrhome
solr1 8081 SolrCloud\data\solrhome1
solr2 8082 SolrCloud\data\solrhome2
solr3 8083 SolrCloud\data\solrhome3
3:打开solrhome1下的solr.xml,并修改内容:
<?xml version="1.0" encoding="UTF-8" ?>
<solr>
<solrcloud>
<str name="host">${host:}</str>
<int name="hostPort">8080</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:15000}</int>
<bool name="genericCoreNodeNames">
${genericCoreNodeNames:true}
</bool>
<str name="zkHost">
127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
</str>
</solrcloud>
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:0}</int>
<int name="connTimeout">${connTimeout:0}</int>
</shardHandlerFactory>
</solr>
其中hostPort为该服务器的tomcat端口
zkHost为Zookeeper的三个服务器地址用逗号连接起来。
依次启动三个solr服务器,并访问任意一个solr,出现下图页面,即说明配置集群服务成功。
3:在Zookeeper 中上传Solr的connection配置文件
(1):复制相应的Solr的配置文件(例如:Solr\example\solr\collection1\conf)到指定地址
(2):复制Solr\example\lib\ext\*.jar 和 war包中的所有lib中的所有jar包到一个文件夹中。
4:执行命令
java -classpath D:\\uploadCloud\\ClientLib\\* org.apache.solr.cloud.ZkCLI -cmd
upconfig -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 -confdir
D:\\uploadCloud\\conf -confname myconf
该命令是使用了之前复制的jar包中的ZkCLI程序进行一个指定文件夹的 upconfig 工作
4:执行命令
java -classpath D:\\uploadCloud\\ClientLib\\* org.apache.solr.cloud.ZkCLI -cmd
linkconfig -collection collection -confname myconf -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
该命令是将刚刚上传的配置文件命名为一个collection对象
5: 创建connection实例
访问刚刚配置的solr服务器
http://127.0.0.1:8081/solr/admin/collections?action=CREATE&name=collection1&numShards=3&replicationFactor=3&maxShardsPerNode=3
name:collection的名称
numShards:指定分片数量(slices)
replicationFactor:副本数量
maxShardsPerNode:默认值为1,注意三个数值:numShards、replicationFactor、liveSolrNode,一个正常的solrCloud集群不容许同一个liveSolrNode上部署同一个shard的多个replic,因此当maxShardsPerNode=1时,numShards*replicationFactor>liveSolrNode时,报错。因此正确时因满足以下条件: numShards*replicationFactor<liveSolrNode*maxShardsPerNode
createNodeSet:
collection.configName:指定该collection使用那份config,这份config必须存在于zk中。
Solr服务器集群的好处
集中式的配置信息使用ZK进行集中配置
启动时可以指定把Solr的相关配置文件上传Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。另外,Solr的一些任务也是通过ZK作为媒介发布的。目的是为了容错。接收到任务,但在执行任务时崩溃的机器,在重启后,或者集群选出候选者时,可以再次执行这个未完成的任务。
自动容错SolrCloud对索引分片,并对每个分片创建多个Replication
每个Replication都可以对外提供服务
一个Replication挂掉不会影响索引服务。更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
近实时搜索
立即推送式的replication(也支持慢推送)。可以在秒内检索到新加入索引。
均衡查询压力 查询时自动负载均衡SolrCloud索引的多个Replication可以分布在多台机器上 如果查询压力大,可以通过扩展机器,增加Replication来减缓。
自动分发的索引和索引分片发送文档到任何节点,它都会转发到正确节点。
事务日志事务日志确保更新无丢失,即使文档没有索引到磁盘。
索引存储在HDFS上索引的大小通常在G和几十G,上百G的很少,这样的功能或许很难实用。 但是,如果你有上亿数据来建索引的话,也是可以考虑一下的。 我觉得这个功能最大的好处或许就是和下面这个“通过MR批量创建索引”联合实用。
通过MR批量创建索引 有了这个功能,你还担心创建索引慢吗?
强大的RESTful API通常你能想到的管理功能,都可以通过此API方式调用。这样写一些维护和管理脚本就方便多了。
优秀的管理界面主要信息一目了然;可以清晰的以图形化方式看到SolrCloud的部署分布;当然还有不可或缺的Debug功能。
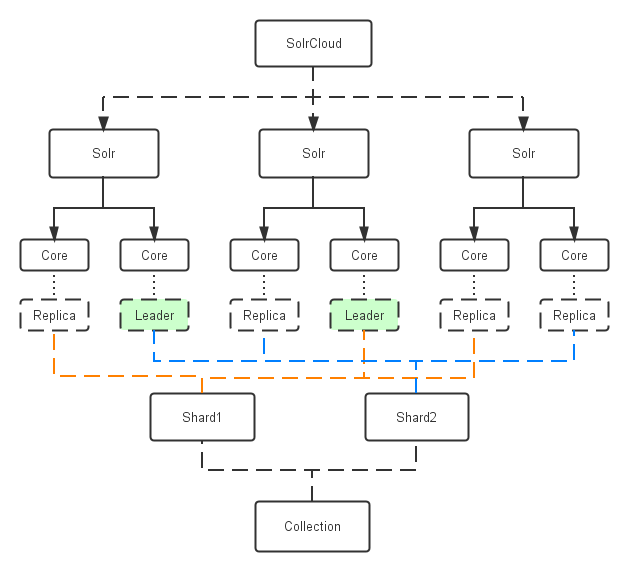
索引(collection)的逻辑图
Solr和索引对照图
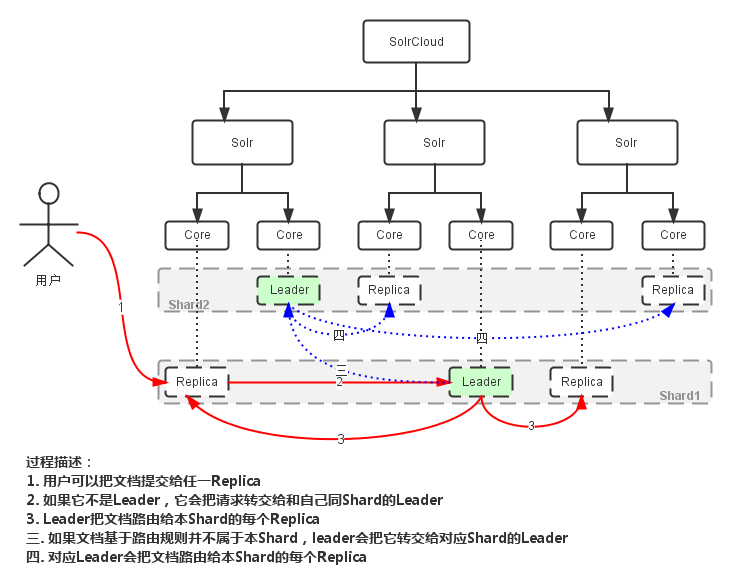
创建索引过程
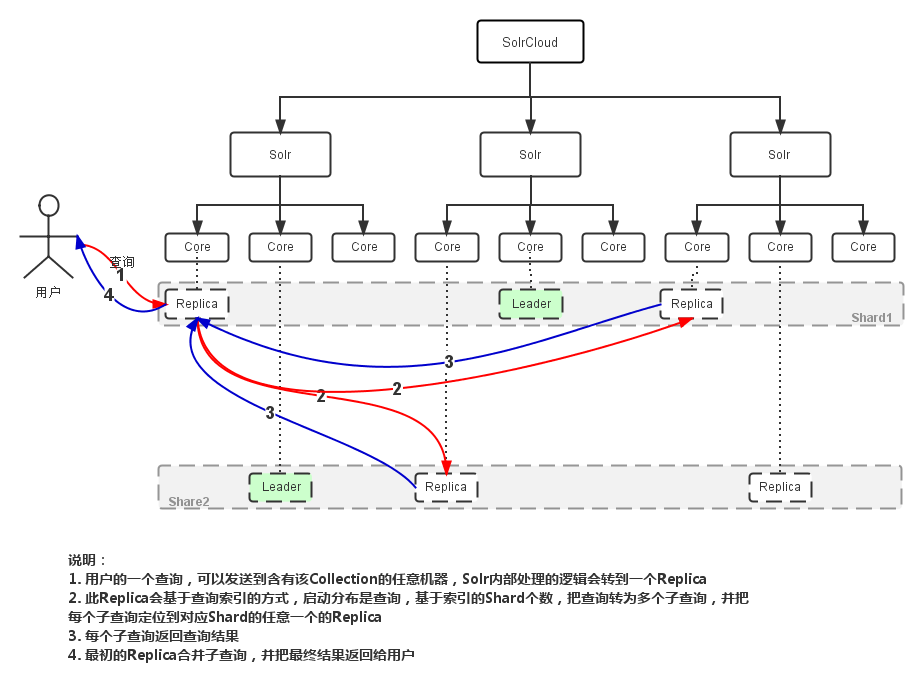
分布式查询
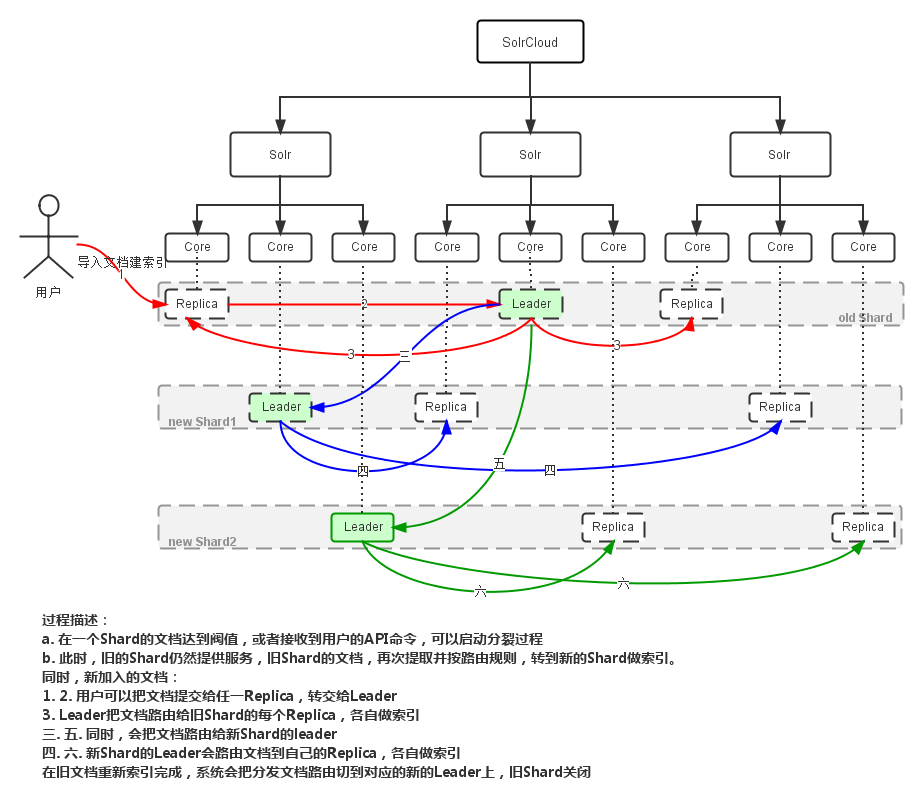
Shard Splitting















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









