






Spark源码版本定制从SparkStreaming切入的原因:
1,早期版本的Spark只有Spark Core,在后续版本的演进中逐渐增加了Spark SQL、Spark Streaming、Spark R、Spark GraphX、Spark MLlib等框架。Spark Streaming 是Spark Core上的一个子框架,我们通过对一个子框架的彻底研究,一定能够掌握对所有Spark框架问题的解决之道;
2,Spark SQL涉及了太多的SQL语法细节的解析和优化,对于我们集中精力研究Spark而言不太适合;Spark R很不成熟,支持功能有限;Spark GraphX最近的几个版本没有新的进展,而且涉及到很多数学级别的算法;Spark MLlib也涉及了太多的数学知识;而Spark Streaming是流式计算,在大数据流处理时代,一切不能进行实时流处理的数据,都是无效的数据;Spark Streaming的流式处理,可以在线的使用机器学习、图计算、Spark SQL、Spark R的成果,这得益于Spark的一体化、多元化的技术架构的设计,这是Spark无可匹敌之处,这也是Spark Streaming必将一统大数据天下的根源。
本期内容:
1,Spark Streaming另类在线实验
2,瞬间理解Spark Streaming本质
一、Spark Streaming另类在线实验
我们在学习和研究Spark Streaming的过程中,经常会有一些比较困惑的问题:例如说数据不断的流进来,不断的生成Job并提交给集群进行处理,我们渴望更清晰的看到数据的流入、渴望更清晰的看到数据被处理的过程。如果能看得很清楚的话,心里就会很踏实。其实只需要使用一个小技巧,就是把Spark Streaming 的Batch Interval放到足够大,例如说5分钟一次(Batch Interval时间间隔的大小对于我们而言没有太大的影响,但是对于我们理解Spark Streaming的工作原理具有重大的意义),把处理的过程放慢,以方便看清楚程序执行的各个环节。
我们从已经写过的广告计费系统中在线黑名单过滤实战案例的Spark Streaming程序入手。
本案例中Spark集群测试环境有5个节点:Master、Worker1、Worker2、Worker3、Worker4。
Spark版本为最新的 spark-1.6.1
本案例源代码如下:
package com.dt.spark.sparksteaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object OnlineBlackListFilter {
def main(args: Array[String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf() //创建SparkConf对象
conf.setAppName("OnlineBlackListFilter") //设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setMaster("spark://Master:7077") //此时,程序在Spark集群
val ssc = new StreamingContext(conf, Seconds(30))
/**
* 黑名单数据准备,实际上黑名单一般都是动态的,例如在Redis或者数据库中,黑名单的生成往往有复杂的业务
* 逻辑,具体情况算法不同,但是在Spark Streaming进行处理的时候每次都能工访问完整的信息
*/
val blackList = Array(("hadoop", true),("mahout", true))
val blackListRDD = ssc.sparkContext.parallelize(blackList, 8)
val adsClickStream = ssc.socketTextStream("Master", 9999)
/**
* 此处模拟的广告点击的每条数据的格式为:time、name
* 此处map操作的结果是name、(time,name)的格式
*/
val adsClickStreamFormatted = adsClickStream.map { ads => (ads.split(" ")(1), ads) }
adsClickStreamFormatted.transform(userClickRDD => {
//通过leftOuterJoin操作既保留了左侧用户广告点击内容的RDD的所有内容,又获得了相应点击内容是否在黑名单中
val joinedBlackListRDD = userClickRDD.leftOuterJoin(blackListRDD)
/**
* 进行filter过滤的时候,其输入元素是一个Tuple:(name,((time,name), boolean))
* 其中第一个元素是黑名单的名称,第二元素的第二个元素是进行leftOuterJoin的时候是否存在在值
* 如果存在的话,表面当前广告点击是黑名单,需要过滤掉,否则的话则是有效点击内容;
*/
val validClicked = joinedBlackListRDD.filter(joinedItem => {
if(joinedItem._2._2.getOrElse(false))
{
false
} else {
true
}
})
validClicked.map(validClick => {validClick._2._1})
}).print
/**
* 计算后的有效数据一般都会写入Kafka中,下游的计费系统会从kafka中pull到有效数据进行计费
*/
ssc.start()
ssc.awaitTermination()
}
}
把Batch Interval的时间间隔重新设置为300秒,代码如下:
val ssc = new StreamingContext(conf, Seconds(300))
然后把编译好的程序导出成一个jar文件,部署到Master节点的某个目录下。
启动start-dfs.sh、Spark sbin目录下的start-all.sh start-history-server.sh三个脚本文件。
通过 nc -lk 9999 命令打开Socket发送数据的端口。
到Spark bin目录下执行 spark-submit 命令提交刚才打包的 jar文件到Spark集群。
向Socket发送数据的端口输入部分测试数据:

程序正常运行并在控制台打印出计算后的结果:

我们立即停止程序的执行,此时从实际执行的角度讲只有一个Job(Batch级别)。
打开浏览器,输入http://Master:18080,查看Web UI上的History Server的日志信息如下:

应用程序列表中最后一次执行的程序则为我们刚才执行完成的程序,可以看到该程序运行了2分钟,点击该程序超链接进去以后可以看到共有5个已完成的Job,且Job 1的运行时间为1.5分钟,而从实际执行的角度讲只有一个Job:

点击Job 0超链接进去以后从DAG Visualization图中可以看到,此Job并没有执行业务逻辑的代码,从中可以发现Spark Streaming在运行的过程中会自动额外的启动一些Job,这是我们从Web控制台看到的第一个现象。

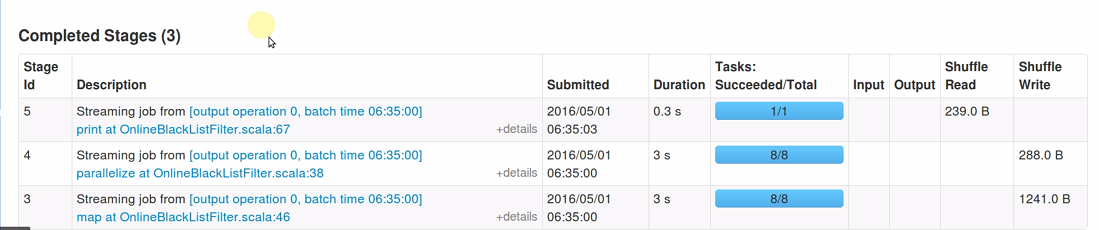
另外还可以看到,Job 0跨两个Stage,点击Stage 0超链接进去后,会发现有50个已完成的任务:

从Aggregated Metrics by Executor 处可以看到,此Stage 跨四个Executor:
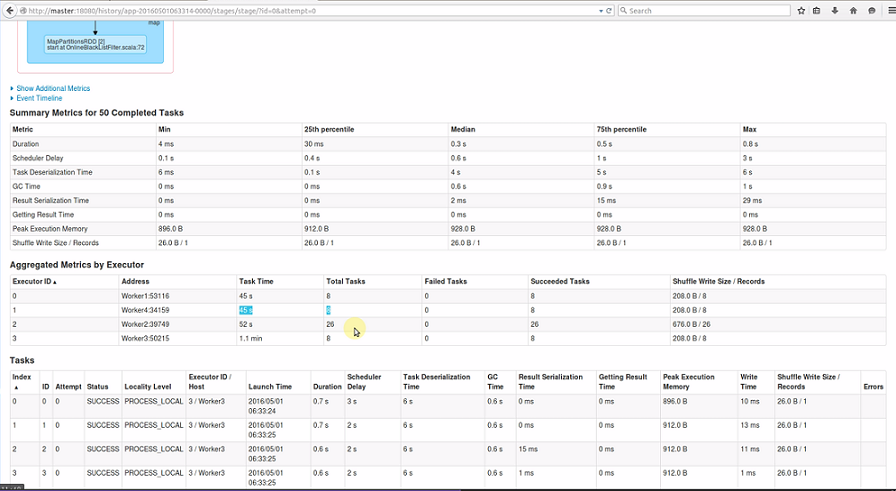
回过头来再点击Job 1超链接,进去后发现此Job只有一个Stage 2:
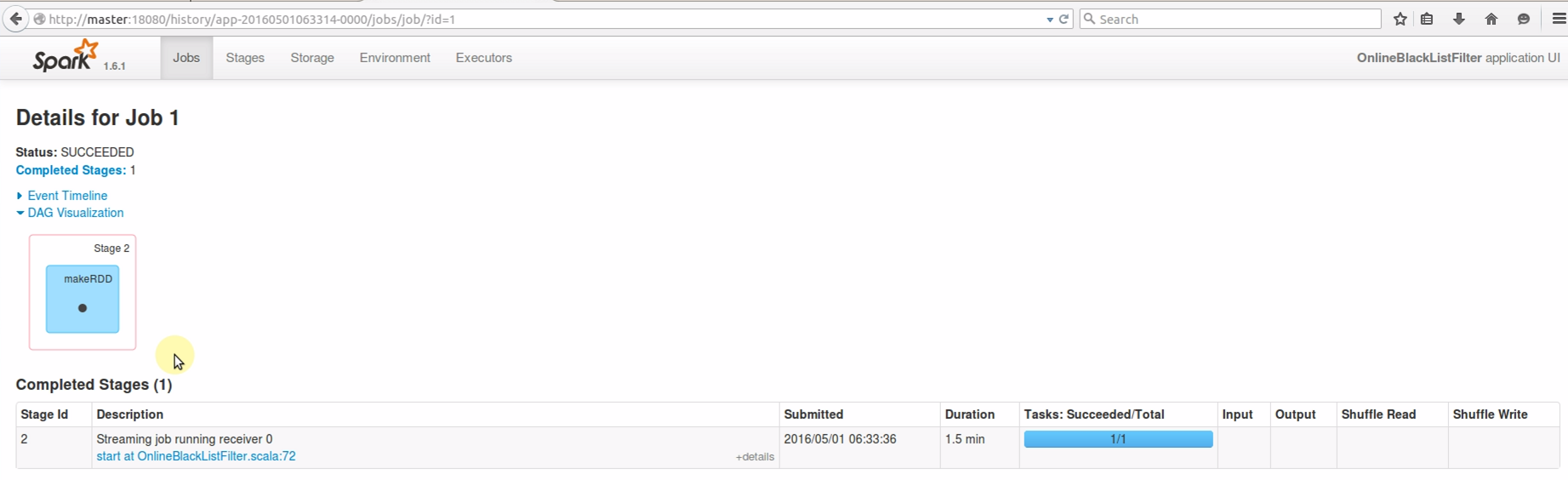
点击Stage 2 超链接进去后,从DAG Visualization图中可以看到,makeRDD在ReceiverTracker上执行,ReceiverTracker是整个集群的数据追踪器。而且从Aggregated Metrics by Executor 处可以看到,此Stage只在Worker4节点上执行,且执行时间为1.5分钟:
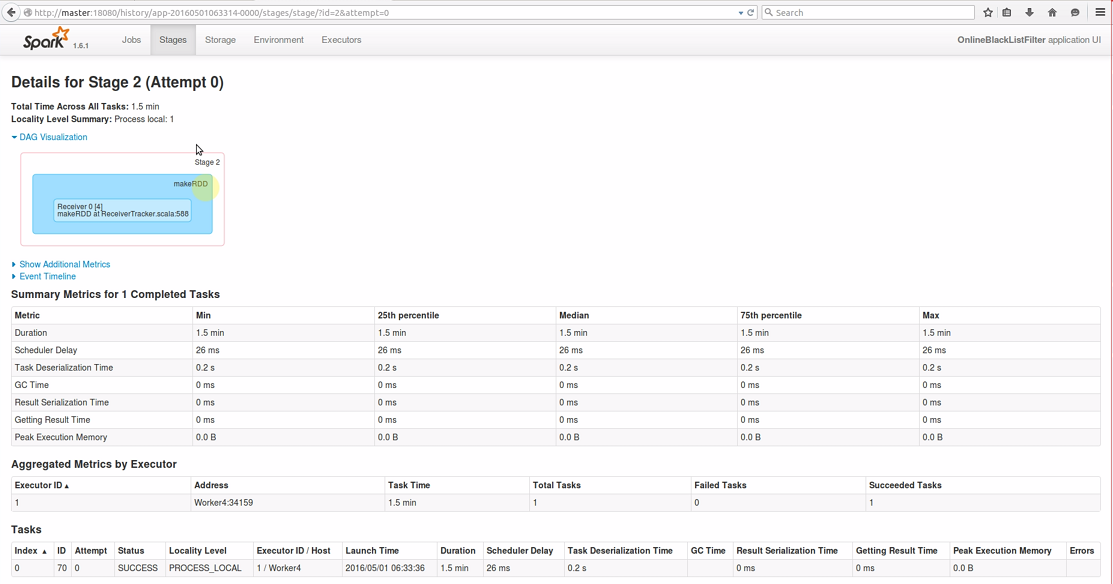
在前面我们已经看到过,整个程序运行了2分钟,那么在这里是什么程序运行了1.5分钟?
是数据接收器Receiver运行了1.5分钟,因为Receiver在一直不断地接收数据,且Receiver是在Executor上运行的,SparkStreaming 启动Receiver是通过一个Job来执行的,是这个Job(也就是我们看到的Job 1)运行了1.5分钟,在一个具体Cluster的Worker上,Executor中启动Receiver是通过一个Job来执行的(肯定有一个Action触发),而且这个Receiver只在一个Executor中运行,且在这个地方就是通过一个Task接收数据,这是我们从Web控制台看到的第二个现象。从这个角度来讲,Receiver接收数据和普通的Job没有区别,由此我们也得到一个启发,就是我们在一个Spark Application中可以启动很多个Job,不同的Job之间可以相互配合。通过SparkStreaming框架默认启动的Job,接收数据为后续的处理做准备,为我们写复杂程序奠定了非常良好的基础,这就是我们写非常复杂的Spark程序的一个黄金切入点。
另外还有一点,从上图中可以看到,Tasks的 Locality Level 为 PROCESS_LOCAL,PROCESS_LOCAL 为内存节点,SparkStreaming 默认接收数据的方式为 MEMORY_AND_DISK_SER_2,再次说明一点,数据量比较少内存能放的下的情况下数据不会放入磁盘,处理的时候直接使用内存中的数据。
再回去看Job 2的运行情况,发现此Job有三个Stage在执行:
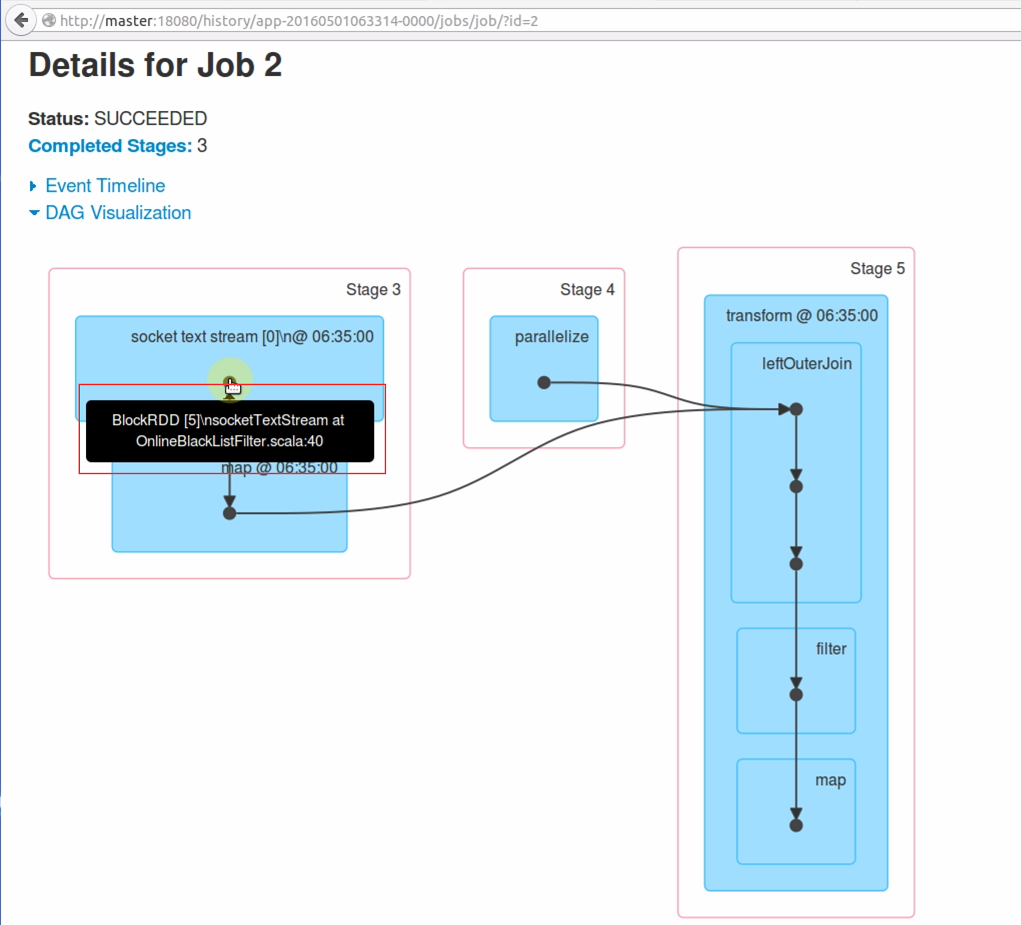
在Stage 3上,有一个BlockRDD 来自于 socket text stream的方法,其实就是InputDStream通过BatchInterval时间间隔产生的RDD。
点击Stage 3超链接进去,查看该Stage运行情况,发现此Stage在4个Executor上执行:


这里进行的是transform操作,发生在四个节点的Executor上,这就说明,接收数据是在一个节点上,处理数据是在4个节点上,最大化地利用集群资源进行处理。
点击Stage 4超链接进去,查看该Stage运行情况,发现此Stage也是在4个Executor上执行:
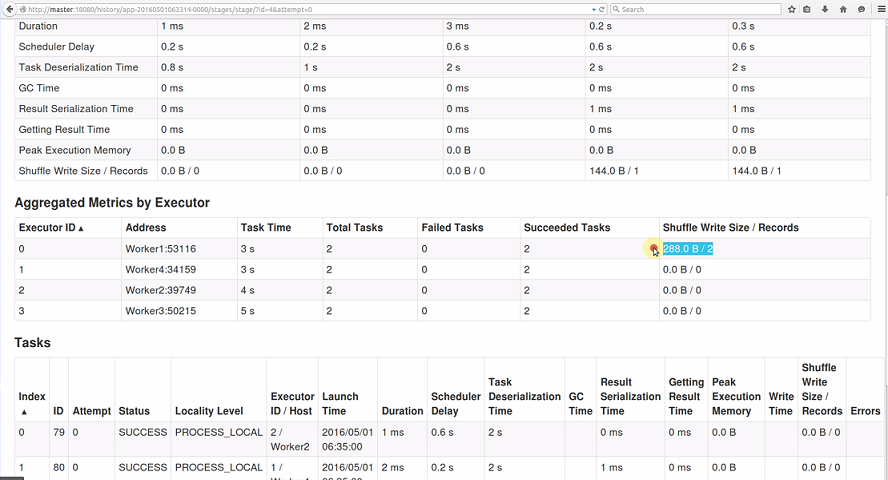
点击Stage 5超链接进去,查看该Stage运行情况,发现此Stage只发生在Worker4节点上:

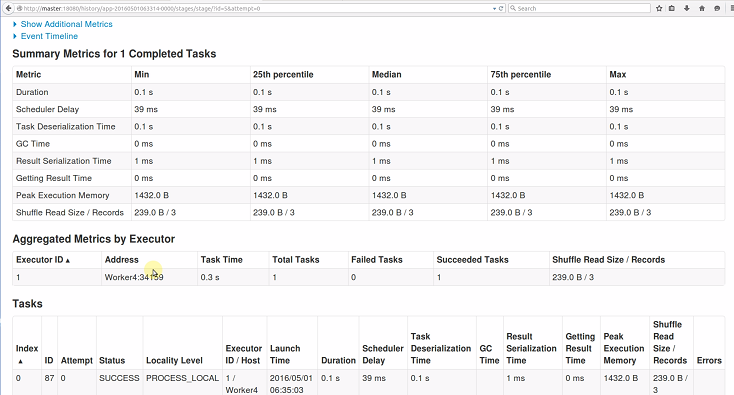
这里进行了leftOuterJoin操作,会产生一个结果,把结果放在Worker4节点上。
再回去看Job 3的运行情况,发现此Job跳过了两个Stage,实际上只有一个Stage 8 在执行:

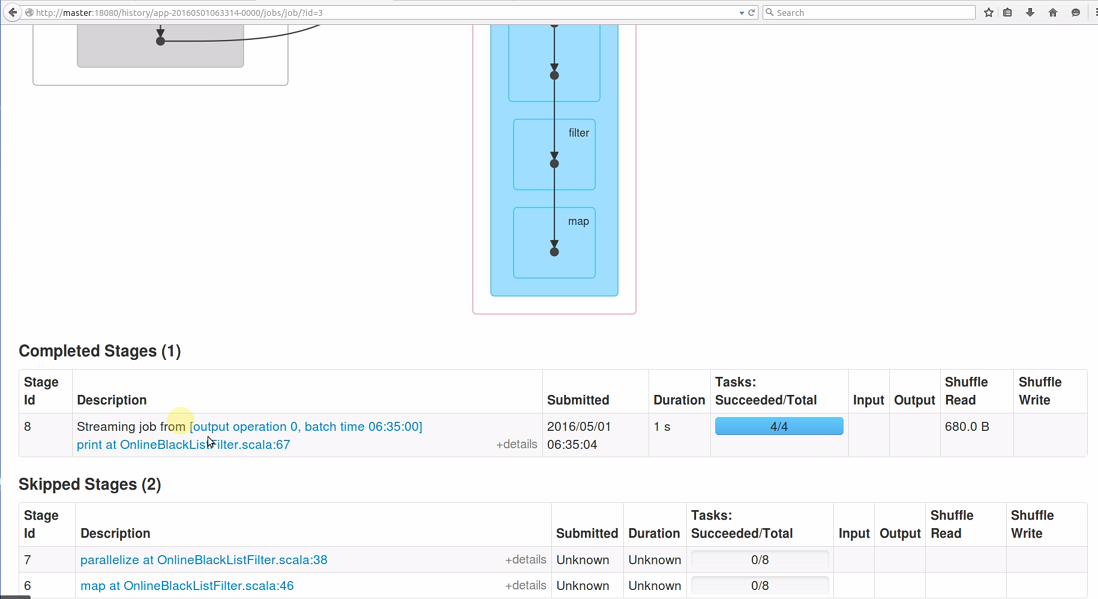
点击Stage 8 超链接进去,发现此Stage也是发生在4个节点上:

最后再看Job 4 的运行情况,发现此Job也是跳过了两个Stage,实际上只有一个Stage 11 在执行:


点击Stage 11 超链接进去,发现此Stage发生在3个节点上:

综合以上可以发现,执行一个Batch级别的Job,实际上会产生很多个Job在执行,这会告诉我们一件事情,就是SparkStreaming 绝不是网络和书籍上看到的那么简单!
二、瞬间理解Spark Streaming本质
SparkStreaming 本身是按照时间间隔把流进来的数据划分成Job,触发Job在Cluster上执行的一个流式处理引擎,它实际上是加上了时间维度的批处理。
例如说我们刚才的程序是5分钟产生一批数据,基于这一批数据会生成RDD,基于RDD就会触发Job,至于RDD的生成、Job的生成及触发,都是框架在做的事情。
下面请看一幅图:

为了便于理解,我把它拆分成下面的四张小图:

这张图表明:Spark Streaming 可以接收来自于 Kafka、Flume、HDFS/S3 和 Kinesis 等不同来源的实时数据,按照特定的逻辑进行实时计算处理后,处理结果又可以存储到 HDFS、数据库、仪表盘等各种介质上。

这张图说明:Spark Streaming接收这些实时输入数据流,并将它们按照批次划分,然后交给Spark引擎处理后,生成对应批次的数据流。

这张图说明:Spark Streaming 提供了表示连续数据流的、高度抽象的被称为离散流的 DStream。DStream 本质上就是 RDD的序列,DStream 中的每个 RDD 都包含来自一个时间间隔的数据。
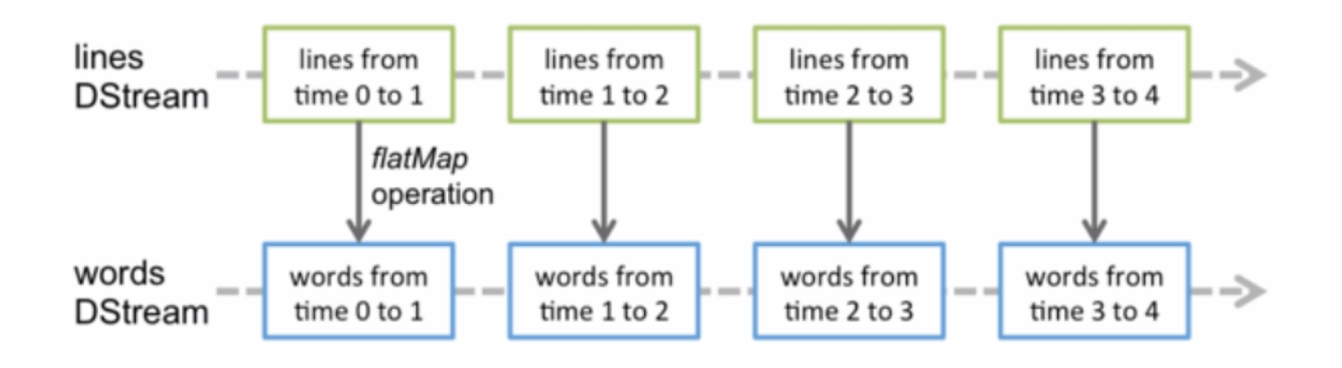
这张图说明:Spark Streaming 除了可以使用不同数据来源的输入流创建DStream外,也可以在已有的DStream的基础上使用一些操作来创建新的DStream。任何对DStream的操作都会转变为对底层RDD的操作。本图例子是对lines DStream进行了flatMap操作后,生成words DStream。
DStream 是一个没有边界的集合,没有大小的限制,DStream 代表了时空的概念。随着时间的推移,里面不断的产生 RDD,DStream 就是 RDD 的集合,只不过有时间的先后顺序。空间维度是 DStream 的处理层面,我们对 DStream 的处理其实就作用在 RDD 上,所以 DStream 就是时空的代表。时间如果固定的话,就会锁定空间的操作,这个操作其实就是 transform,也就是对本时间段内对应批次的数据的处理。
对 DStream 的操作会构建 DStream Graph,下面展示另一张图:

图中左侧为程序代码,构建了两个InputDStream,代表两个数据输入来源,它们进行了 join 操作把数据联合起来,产生了Join DStream,Join DStream又进行了 map 操作,产生了 Mapped DStream,Mapped DStream又分别进行了三次操作:
1、先进行了 map 操作,又进行了 foreach 操作,产生了 Foreach DStream;
2、直接进行了 foreach 操作,产生了 Foreach DStream;
3、先进行了 reduce 操作,产生了 Reduce DStream,又进行了 foreach 操作,产生了 Foreach DStream。
在本例中,每个 foreach 操作会触发作业,就会从后往前回溯,这就形成了 DStream 之间的依赖关系,也就构建了 DStream Graph,如右侧图中所示。
下面展示另一张图:

DStream Graph 是模板,对它进行操作加上时间维度就会实例化并生成 RDD Graph。
空间维度确定以后,随着时间的不断推进,就会把空间维度的 DStream Graph 实例化成 RDD Graph,然后触发具体Job的执行。
现在再去阅读 Spark Streaming 的官方文档,就好理解多了。

备注:
更多私密内容,请关注微信公众号:DT_Spark
更多干货请访问微博:http://weibo.com/ilovepains
每晚20:00大数据Spark技术永久免费公开课,YY频道:68917580















 3106
3106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









