






本期内容:
1,解密Spark Streaming Job架构和运行机制
2,解密Spark Streaming容错架构和运行机制
一,解密Spark Streaming Job架构和运行机制
我们从已经写过的在线单词统计实战案例的Spark Streaming程序入手,通过Spark Streaming的foreachRDD把处理后的数据写入外部的数据库中。
本案例代码如下:
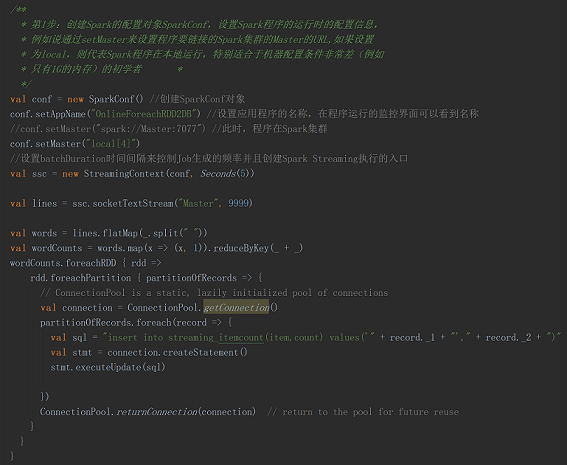
本案例中,每隔5秒钟读取一次 SocketServer 上的输入数据,在线处理后把计算结果存放到MySQL数据库中。
把程序提交到Spark集群运行,控制台打印出程序运行中的日志信息:

从控制台可以看到有SocketInputDStream、对SocketInputDStream进行flatMap又产生了FlatMappedDStream、对FlatMappedDStream进行map操作又产生了MappedDStream,对MappedDStream进行reduceByKey操作又产生了ShuffledDStream,对ShuffledDStream进行foreach操作又产生了ForeachDStream。接着又看到RecurringTimer、JobGenerator、JobScheduler启动,接着是StreamingContext、ReceiverTracker、DAGScheduler等启动,这些都是Spark Core的内容。
停止程序的执行,然后查看WEB控制台的信息:

可以看到随着时间的流逝不断的生成Job并且执行,那么Spark Streaming中的Job是怎么生成的?
从StreamingContext类的源码中可以看到,该类中有一个JobScheduler对象;

在StreamingContext调用start方法的内部,其实是会调用JobScheduler对象的start方法,进行消息循环。

在JobScheduler实例化的时候会创建JobGenerator对象。

在JobScheduler的start方法内部会构造ReceiverTacker,并且调用JobGenerator和ReceiverTracker对象的start方法。

1,JobGenerator启动后会不断的根据BatchDuration生成一个个的Job。
2,ReceiverTracker启动后首先在Spark Cluster中启动Receiver(其实是在Executor中先启动ReceiverSupervisor),在Receiver收到数据后会通过ReceiverSupervisor存储到Executor上并且把数据的Metadata信息发送给Driver中的ReceiverTracker,在ReceiverTracker内部会通过ReceivedBlockTracker来管理接收到的元数据信息。
每个BatchInterval会产生一个具体的Job,其实这里的Job不是Spark Core中所指的Job,它只是基于DStreamGraph而生成的RDD的DAG而已,从Java角度讲,相当于Runnable接口实例,此时要想运行Job需要提交给JobScheduler,在JobScheduler中通过线程池的方式找到一个单独的线程来提交Job到集群运行(其实是在线程中基于RDD的Action触发真正的作业的运行),为什么使用线程池呢?
1),作业不断生成,所以为了提升效率,我们需要线程池,这和在Executor中通过线程池执行Task有异曲同工之妙;
2),有可能设置了Job的FAIR公平调度的方式,这个时候也需要多线程的支持。
二,解密Spark Streaming容错架构和运行机制
Spark Streaming容错分为Driver级别的容错和Executor级别的容错:
1,Driver级别的容错,有几个层面:
1),RDD DAG生成的模板,就是DStream Graph;
2),ReceiverTracker接收到数据后处理了哪些,还有JobGenerator生成作业的进度等等。
其实这些只需要做一个CheckPoint就可以解决,每个Job生成之前做一次CheckPoint,生成之后再做一次CheckPoint,如果处理出错就从CheckPoint中恢复,
2,Executor级别的容错:
1),接收数据的安全性:
SparkStreaming 默认接收数据的方式为 MEMORY_AND_DISK_SER_2, 也就是默认情况下数据是存放在两台机器的内存中,如果一台机器挂了以后会立即切换到另外一台机器上,这种方式在大多数情况下是非常可靠的,而且基本上没有切换时间;
另一种接收数据的方式是WAL(Write Ahead Log)的方式,就是在数据到来的时候,先把数据通过WAL机制做一个日志记录(以后有问题的话就会恢复),然后再把数据存储到Executor中,存完以后再进行其它机器副本的复制。所以这种方式是先写日志再写其它的东西,如果数据丢失,就会通过WAL的机制恢复数据。生产环境下,这种方式不太常用,一般是和Kafka结合,Kafka支持数据的回放,如果处理出现问题的话可以重新读数据,Kafka另一个层面相当于数据的存储系统,这种方式是实际业务中最常见的。
2),任务执行的安全性:
就是指Job执行的安全性,Job执行完全靠RDD来容错,RDD是安全的。
备注:
更多私密内容,请关注微信公众号:DT_Spark
更多干货请访问微博:http://weibo.com/ilovepains
每晚20:00大数据Spark技术永久免费公开课,YY频道:68917580
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









