






第一章: namedtuple的功能详解
为了便于理解nametuple,先来讲讲tuple的一些特性
1. 可拆包
mytuple1 = ('cannon', 26, 178)
name1, age, height = mytuple1
name2, *other = mytuple1
print(name1, age, height)
print(name2, other) # other会是list
运行结果
cannon 26 178
cannon [26, 178]
2.tuple的不可变性不是绝对的
mytuple2 = ('tuple', [1, 2])
mytuple2[1].append(3)
print(mytuple2) # 通常不建议在tuple中放 可变对象
运行结果
('tuple', [1, 2, 3]) # dict元素中加入了3
3. tuple比list好的地方:
因为immutable(不可变性) ,所以
1. 性能优化
2. 线程安全
3. 可以作为dict的key
4. 拆包特性第三点可以作为dict的key很重要,代码讲解一下:
mydict = {}
mydict[mytuple1] = 'value'
# mydict[mytuple2] = 'value' # tuple中有可变的元素,就不能作为dict的key了, 因为不能哈希
print(mydict)
运行结果:
{('cannon', 26, 178): 'value'}
#tuple作为了dict的key, 但如果tuple中有可变元素如list,就无法作为dict的key, 因为不能哈希
-
namedtuple讲解
- namedtuple是tuple的子类, 特别在数据处理中 用得很多
- namedtuple类似创建类一样 创建tuple, 速度快效率高
from collections import namedtuple
User = namedtuple('User', ['name', 'age', 'height'])
# User相当于数据库的表名, []中的是数据名
# 传入数据法一
user1 = User(name='cannon1', age=25, height=178)
print(user1.age, user1.name, user1.height)
# 传入数据法二
tuple = ('cannon2', 26, 180) # 用list代替tuple传入也可以
user2 = User(*tuple) # 类似函数参数 *args 或者用user2 = User._make(tuple)
print(user2.age, user2.name, user2.height)
# namedtuple转为OrderedDict
user_info_dict = user2._asdict()
print(user_info_dict)
# namedtuple依然可以拆包
name, *other = user2
print(name, other)
运行结果:
25 cannon1 178
26 cannon2 180
OrderedDict([('name', 'cannon2'), ('age', 26), ('height', 180)])
cannon2 [26, 180]
第二章:defaultdict的功能详解
以统计list中的元素个数为例子讲解default的用法
先以dict方法实现:
from collections import defaultdict # c语言实现的,性能高
# 统计数量
# dict方法
users = ['cannon1', 'cannon2', 'cannon1', 'cannon1']
user_dict1 = {}
for user in users:
if user not in user_dict1: # 这种逻辑过多的话,会影响代码可读性
user_dict1[user] = 1
else:
user_dict1[user] += 1
print(user_dict1)
# dict方法改良 setdefault, 效率比原方法高效, 应为少了一次查询
user_dict2 = {}
for user in users:
user_dict2.setdefault(user, 0) # 对应key设置默认的value
user_dict2[user] += 1
print(user_dict2)
运行结果:
{'cannon1': 3, 'cannon2': 1}
{'cannon1': 3, 'cannon2': 1}
defaultdict方法实现:
# defaultdict方法
default_dict = defaultdict(int) # 传入默认类型 list,float等等都以传, 但不可以传入参数
for user in users:
default_dict[user] += 1
print(default_dict)
运行结果:
defaultdict(<class 'int'>, {'cannon1': 3, 'cannon2': 1})
当传入默认类型的方法不适合或者想传入实际数值作为参数时, 我们可以利用函数作用传入类型:
# 假如默认类型是dict的话,可以这么做。
def gen_dict():
return {
'name': 'cannon3',
'age': 25
}
default_dict2 = defaultdict(gen_dict)
print(default_dict2['default']) # print未定义过的dict的key
运行结果:
{'name': 'cannon3', 'age': 25}
第三章:deque功能详解
deque是双端队列,我们以代码来讲解
from collections import deque
user_list = ['cannon1', 'cannon2']
user_name = user_list.pop()
print(user_name, user_list)
运行结果:
cannon2 ['cannon1']
list只有pop溢出尾部元素, 如果想溢出头部元素, 就需要deque了
deque是对list的扩充, 使用c编写的。 我们可以通过查看源码: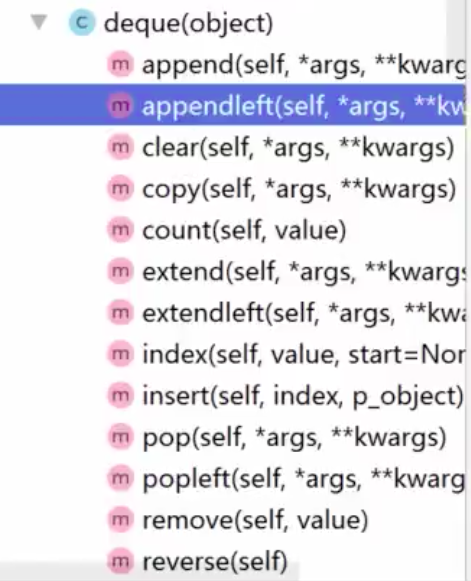
可以发现deque多了appendleft,extendleft,popleft 等可以作用于头部的方法。
一些简单用法举例
from collections import deque
# user_list = ['cannon1', 'cannon2']
# user_name = user_list.pop()
# print(user_name, user_list)
# appendleft
user_deque = deque(['cannon1', 'cannon2', 'cannon3'])
user_deque.appendleft(('cannon0')) # 头部加入cannon0
print(user_deque)
# 浅拷贝copy
user_deque2 = user_deque.copy()
# 深拷贝
import copy
user_deque3 = copy.deeepcopy(user_deque)
# extend 在原queue中扩容
user_deque11 = deque(['cannon11', 'cannon22', 'cannon33'])
user_deque11.extend(user_deque) # user_deque11会扩容
# reverse 原deque中 元素顺序颠倒
user_deque.reverse()
最后另外说明:
deque的应用: from queue import Queue 双端队列
deque对比list: deque是GIL线程安全的, list不是线程安全的第四章: Counter功能详解
Counter用来统计可迭代类型中的相同元素个数
统计列表中每种元素个数:
>>> from collections import Counter
>>> users = ['cannon1', 'cannon2', 'cannon3', 'cannon2', 'cannon2', 'cannon1']
>>> user_counter = Counter(users) # 传入可迭代对象, 完成统计功能
>>> print(user_counter)
Counter({'cannon2': 3, 'cannon1': 2, 'cannon3': 1})
统计字符串
# 统计字符串
>>> user_counter = Counter('asadjansjjsjjdjddwsssa')
>>> print(user_counter)
Counter({'s': 6, 'j': 6, 'a': 4, 'd': 4, 'n': 1, 'w': 1})
进行合并统计
# 进行合并的统计, 可以update可迭代对象, 也可以update Counter对象
>>> user_counter.update('sajdhwawhwwiwiwiwhhdh') # 合并统计字符串
>>> print(user_counter)
Counter({'w': 8, 's': 7, 'j': 7, 'a': 6, 'd': 6, 'h': 5, 'i': 3, 'n': 1})
>>> user_counter2 = Counter('bsd')
>>> user_counter2.update(user_counter) # 合并统计Counter对象
>>> print(user_counter2)
Counter({'s': 8, 'w': 8, 'd': 7, 'j': 7, 'a': 6, 'h': 5, 'i': 3, 'b': 1, 'n': 1})
统计数目最多的前几个
# 统计top n 的问题
>>> print(user_counter.most_common(2)) # 统计数量最多的两种
[('w', 8), ('s', 7)]
第五章:OrderedDict功能详解
OrderedDict继承了dict, 是有序的dict。
python2 dict是无序的
python3 dict是有序的OrderedDict除了是有序的以外, 还有很多dict没有的方法:
>>> from collections import OrderedDict
>>> user_dict = OrderedDict()
>>> user_dict['b'] = 'cannon2'
>>> user_dict['a'] = 'cannon1'
>>> user_dict['c'] = 'cannon3'
>>> user_dict['e'] = 'cannon3'
>>> user_dict['d'] = 'cannon3'
>>> print(user_dict) # 会按添加顺序排列
OrderedDict([('b', 'cannon2'), ('a', 'cannon1'), ('c', 'cannon3'), ('e', 'cannon3'), ('d', 'cannon3')])
# popitem
>>> print(user_dict.popitem()) # p移出尾端元素
('d', 'cannon3')
>>> print(user_dict)
OrderedDict([('b', 'cannon2'), ('a', 'cannon1'), ('c', 'cannon3'), ('e', 'cannon3')])
#pop
>>> print(user_dict.pop('a')) # 必须传入key
cannon1
>>> print(user_dict)
OrderedDict([('b', 'cannon2'), ('c', 'cannon3'), ('e', 'cannon3')])
# move_to_end
>>> user_dict.move_to_end('b') # b对应的元素移至末尾
>>> print(user_dict)
OrderedDict([('c', 'cannon3'), ('e', 'cannon3'), ('b', 'cannon2')])
第六章:ChainMap功能详解
ChainMap可以将迭代类型连接起来遍历
通过代码讲解:
>>> from collections import ChainMap
# ChainMap 列表
>>> a = [1, 2, 3]
>>> b = [3, 4, 5]
>>> newlist = ChainMap(a, b)
>>> print(newlist)
# ChainMap字典
>>> user_dict1 = {'a': 'cannon1', 'b': 'cannon2'}
>>> user_dict2 = {'c': 'cannon3', 'd': 'cannon4'}
>>> new_dict = ChainMap(user_dict1, user_dict2)
>>> print(new_dict['c']) # 用起来就像一个dict
cannon3
# 动态的加入新的字典
>>> new_dict = new_dict.new_child({'aa': 'aa', 'bb': 'bb'})
>>> for key, value in new_dict.items():
>>> print(key, value)
d cannon4
a cannon1
c cannon3
bb bb
aa aa
b cannon2
#maps属性, 得到所有数据
>>> print(new_dict.maps)
[{'aa': 'aa', 'bb': 'bb'}, {'a': 'cannon1', 'b': 'cannon2'}, {'c': 'cannon3', 'd': 'cannon4'}]
>>> new_dict.maps[0]['a'] = '0000000' # 说明ChainMap 只是方便遍历多个dict, 并没有产生新的对象
>>> print(new_dict)
ChainMap({'aa': 'aa', 'bb': 'bb', 'a': '0000000'}, {'a': 'cannon1', 'b': 'cannon2'}, {'c': 'cannon3', 'd': 'cannon4'})
ChainMap补充:
ChainMap 只是方便遍历多个dict, 并没有产生新的对象
ChainMap 中假设有 多个字典存在相同的key, 则遍历到一个key后,不会再去遍历同样的key了














 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









