






1. 事件循环
- asyncio是python3.4以后引进的用于解决异步io编程的一整套解决方案
- tornado、gevent、twisted(scrapy、django channels)都使用了asyncio
-
讲解asyncio的简单使用:
import asyncio
import time
async def get_html(url):
print('start get url')
await asyncio.sleep(2) # 必须加await实现协程 这里asyncio.sleep(2)是一个子协程,time.sleep不能可await搭配.
print('end get url')
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop() # 开始事件循环
loop.run_until_complete(get_html('http://baidu.com')) # 阻塞式的, 类似多线程的join
print(time.time() - start_time)
运行结果:
start get url
end get url
2.0011332035064697
如果将上面代码中await asyncio.sleep(2)改为time.sleep(2) 代码运行不会报错,而且结果一样。但在协程中 不要运行同步代码,只要有同步代码,协程并发效果立马作废。
我们以同时多个任务为例:
asyncio.sleep(2)
import asyncio
import time
async def get_html(url):
print('start get url')
await asyncio.sleep(2) # 必须加await实现协程 这里asyncio.sleep(2)是一个子协程,time.sleep不能可await搭配.
print('end get url')
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop() # 开始时间循环
tasks = [get_html('http://baidu.com') for i in range(10)]
loop.run_until_complete(asyncio.wait(tasks)) # 多任务使用asyncio.await
print(time.time() - start_time)
运行结果依然是2s:
start get url
start get url
start get url
start get url
start get url
start get url
start get url
start get url
start get url
start get url
end get url
end get url
end get url
end get url
end get url
end get url
end get url
end get url
end get url
end get url
2.004601001739502
只将await asyncio.sleep(2) 改为time.sleep(2)运行结果如下:
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
start get url
end get url
20.024510860443115
明显的使用time.sleep导致并发效果作废。
所以类似的,在使用asyncio的时候,有很多库的使用必须找到并发的asyncio版本,不要使用同步版的。
-
如何获取返回值
asyncio.ensure_future或者loop.create_task获取future,再通过future获取返回值。类似多线程
我更改上一段代码为例讲解获取返回值以及使用回调函数:
import asyncio
import time
from functools import partial
# 偏函数 专门用来解决 当以函数名作为传入参数,但无法再传入传入函数的参数的问题。比如下面的add_done_callback
async def get_html(url):
print('start get url')
await asyncio.sleep(2) # 必须加await实现协程 这里asyncio.sleep(2)是一个子协程,time.sleep不能可await搭配.
# time.sleep(2) # 不会报错, 但在协程里不要使用同步的io操作
print('end get url')
return 'cannon'
# 回调函数必须有个future传入参数,否则会报错。 这与add_done_callback函数有关
def callback(url, future): # 回调函数, 如果有传入参数, 必须放在future前面。这点比较特殊
print(url)
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop() # 开始时间循环
get_future = asyncio.ensure_future(get_html('http://baidu.com')) # 类似多线程得到的future
# 或者get_future = loop.create_task(get_html('http://baidu.com'))
# get_future.add_done_callback(callback) # 执行完以后执行callback
get_future.add_done_callback(partial(callback, 'www.baidu.com')) # callback如果要传入参数, 使用partial实现
loop.run_until_complete(get_future)
print(get_future.result()) # future的result方法得到返回值, 类似多线程ThreadPoolExecutor
运行结果:
start get url
end get url
www.baidu.com # 回调callback
cannon # 获取的返回值
-
多任务wait和gather方法
在区分time.sleep与await asyncio.sleep 在协程中的区别时, 讲解使用了wait方法的多任务:
loop.run_until_complete(asyncio.wait(tasks))
而gather的基本用法只需要这么改:
loop.run_until_complete(asyncio.gather(*tasks))
或
task = asyncio.gather(*tasks)
loop.run_until_complete(asyncio.gather(task))
那么gather与wait的区别是什么呢?如何对它两进行选择呢?
gather更加high-level高层, gather除了多任务外,还可以对任务进行分组。优先使用gather
代码举例:
import asyncio
import time
from functools import partial
async def get_html(url):
print('start get url', url)
# 必须加await实现协程 这里asyncio.sleep(2)是一个子协程,time.sleep不能可await搭配.
await asyncio.sleep(2)
# time.sleep(2) # 不会报错, 但在协程里不要使用同步的io操作
print('end get url')
return 'cannon'
def callback(url, future):
print(url)
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop() # 开始时间循环
tasks1 = [get_html('http://baidu.com') for i in range(3)]
tasks2 = [get_html('http://google.com') for i in range(3)]
group1 = asyncio.gather(*tasks1) # gather可以进行分组
group2 = asyncio.gather(*tasks2)
loop.run_until_complete(asyncio.gather(group1, group2))
print(time.time() - start_time)
运行结果:
start get url http://baidu.com
start get url http://baidu.com
start get url http://baidu.com
start get url http://google.com
start get url http://google.com
start get url http://google.com
end get url
end get url
end get url
end get url
end get url
end get url
2.002768039703369
2. task取消和子协程调用原理
-
取消task
代码讲解:
import asyncio
async def get_html(sleep_times):
print('waiting')
await asyncio.sleep(sleep_times)
print('done after {}s'.format(sleep_times))
if __name__ == '__main__':
task1 = get_html(1)
task2 = get_html(2)
task3 = get_html(3)
tasks = [task1, task2, task3]
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(asyncio.wait(tasks))
except KeyboardInterrupt as e: # ctl + c 终止时,会进入
all_tasks = asyncio.Task.all_tasks() # 得到所有task
for task in all_tasks:
print('cancel task')
print(task.cancel()) # stop成功会返回True
loop.stop() # 源码中只是_stop置为True
loop.run_forever() # stop之后必须调用run_forever,否则会报错
finally:
loop.close() # 会做很多终止工作, 详情可看源码
运行过程中按ctl+c,得到结果:
waiting
waiting
waiting
done after 1s
done after 2s
^Ccancel task # ctl + c 进入
True
cancel task
False # task1已经执行完,所以无法取消
cancel task
False # task2已经执行完,所以无法取消
cancel task
True # task3取消完成
-
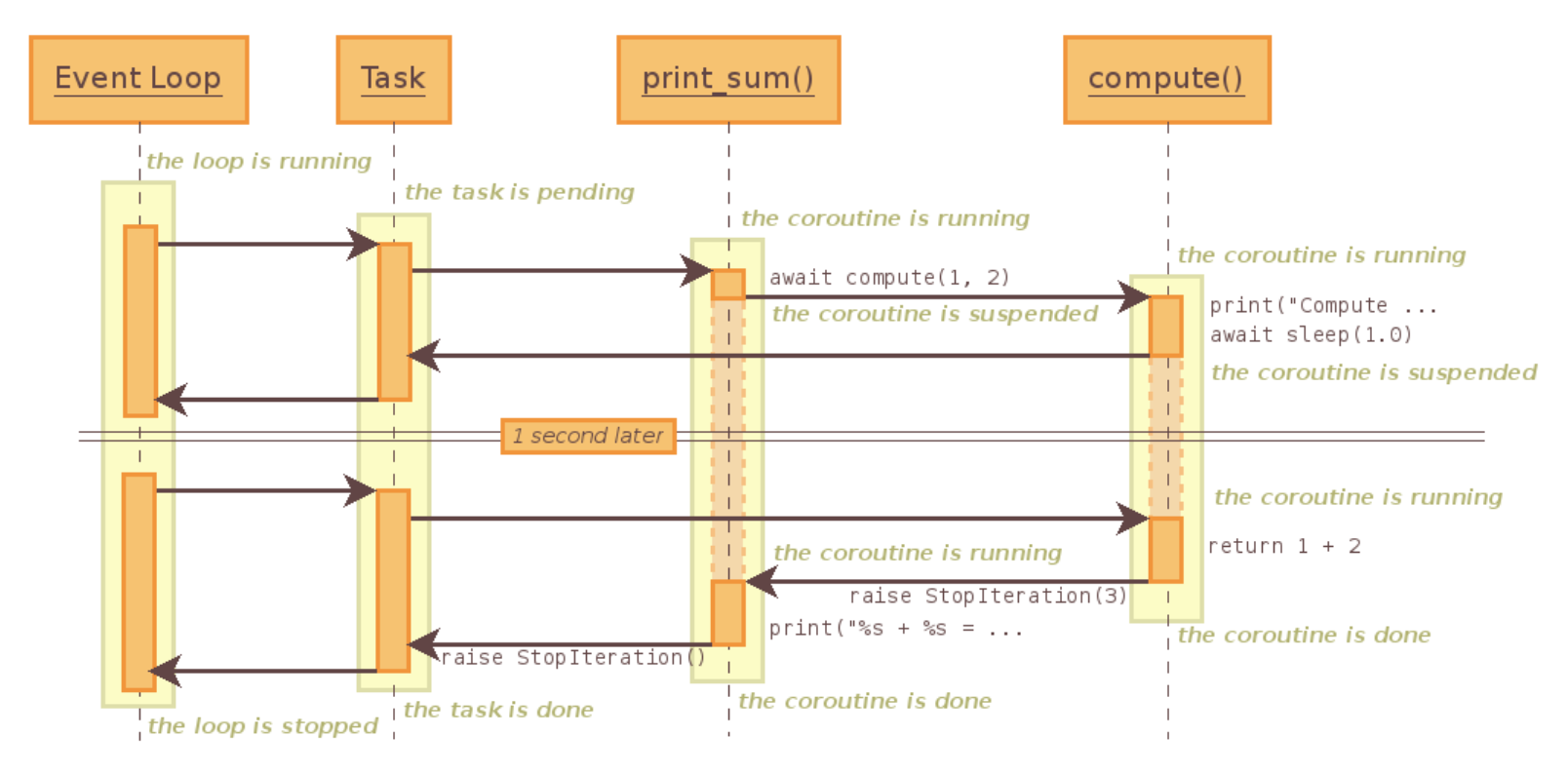
子协程调用原理
来看一段官网的代码:

在理解该代码后,我们再看协程的调用时序图:
3. call_soon,call_at,call_later,call_soon_threadsafe的使用
-
call_soon 立即执行函数
import asyncio
def callback(sleep_times):
print('sleep {} sucess'.format(sleep_times))
def stoploop(loop): # 停止loop
loop.stop()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.call_soon(callback, 2)
loop.call_soon(stoploop, loop) # 停止forever
loop.run_forever()
运行结果
sleep 2 sucess
-
call_later 按等待时间执行函数
import asyncio
def callback(sleep_times):
print('sleep {} sucess'.format(sleep_times))
def stoploop(loop): # 停止loop
loop.stop()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.call_later(1, callback, 2) # 过1秒执行
loop.call_later(2, callback, 1) # 过2秒执行
loop.call_later(3, callback, 3) # 过3秒执行
loop.call_later(4, stoploop, loop) # 过4秒执行, 并停止loop
loop.call_soon(callback, 4) # 最早执行, call_soon先于call_later
loop.run_forever()
运行结果:
sleep 4 sucess
sleep 2 sucess
sleep 1 sucess
sleep 3 sucess
-
call_at 在指定时间执行
import asyncio
def callback(loop):
print('loop time: {} '.format(loop.time()))
def stoploop(loop):
loop.stop()
if __name__ == '__main__':
loop = asyncio.get_event_loop()
now = loop.time() # loop的当前时间(内部时钟时间), 不可以用time.time
loop.call_at(now+2, callback, loop) # 效果和call_later一样, call_later内部其实调用了call_later
loop.call_at(now+1, callback, loop)
loop.call_at(now+3, callback, loop)
loop.call_later(4, stoploop, loop) # stop loop
loop.run_forever()
运行结果:
loop time: 51020.220300657
loop time: 51021.219093865
loop time: 51022.220433824
-
call_soon_threadsafe 线程安全的call_soon
call_soon_threadsafe用法和call_soon一致。但在涉及多线程时, 会使用它.
call_soon,call_later,call_at,call_soon_threadsafe都是比较底层的,在正常使用时很少用到。
4. ThreadPollExecutor 和 asycio完成阻塞io请求
什么时候使用多线程:在协程中集成阻塞io
ThreadPollExecutor 和 asycio结合的使用方法:
import asyncio
from concurrent.futures import ThreadPoolExecutor
import socket
from urllib.parse import urlparse
import time
def get_url(url):
# 通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = '/'
# 建立socket连接
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect((host, 80))
client.send(
"GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode('utf8'))
data = b""
while True:
d = client.recv(1024)
if d:
data += d
else:
break
data = data.decode('utf8')
html_data = data.split('\r\n\r\n')[1] # 把请求头信息去掉, 只要网页内容
print(html_data)
client.close()
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
executor = ThreadPoolExecutor(3) # 线程池 放3个线程
tasks = []
for url in range(20):
url = 'http://shop.projectsedu.com/goods/{}/'.format(url)
task = loop.run_in_executor(executor, get_url, url) # 阻塞的代码放到线程池
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print('last time:{}'.format(time.time()-start_time))
在协程中不要放阻塞的代码, 但如果非要使用阻塞的代码, 就可以放到线程池中运行。
5. asyncio模拟http请求 (协程完成http请求)
import asyncio
from urllib.parse import urlparse
import time
async def get_url(url):
# 通过socket请求html
url = urlparse(url)
host = url.netloc
path = url.path
if path == "":
path = '/'
# 建立socket连接
reader, writer = await asyncio.open_connection(host, 80) # 协程 与服务端建立连接
writer.write(
"GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode('utf8'))
all_lines = []
async for raw_line in reader: # __aiter__ __anext__魔法方法
line = raw_line.decode('utf8')
all_lines.append(line)
html = '\n'.join(all_lines)
return html
# client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# client.connect((host, 80))
# client.send(
# "GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode('utf8'))
# data = b""
# while True:
# d = client.recv(1024)
# if d:
# data += d
# else:
# break
# data = data.decode('utf8')
# html_data = data.split('\r\n\r\n')[1] # 把请求头信息去掉, 只要网页内容
# print(html_data)
# client.close()
async def main():
tasks = []
for url in range(20):
url = 'http://shop.projectsedu.com/goods/{}/'.format(url)
tasks.append(asyncio.ensure_future(get_url(url))) # tasks中放入的是future
for task in asyncio.as_completed(tasks): # 完成一个 print一个
result = await task
print(result)
if __name__ == '__main__':
start_time = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
print('last time:{}'.format(time.time()-start_time))
所以asyncio协程和之前讲解的select事件循环原理是一样的
6. asyncio同步和通信
以前讲解多线程锁的机制的代码, 我们现在改用协程来实现就不需要锁了:
import asyncio
total = 0
async def add():
global total
for _ in range(1000000):
total += 1
async def desc():
global total, lock
for _ in range(1000000):
total -= 1
if __name__ == '__main__':
tasks = [add(), desc()]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
print(total)
运行结果为: 0
这里不用锁,但在有些情况 我们还是需要类似锁的机制。我们代码举例:
parse_stuff和use_stuff有共同调用的代码get_stuff
parse_stuff去请求的时候 如果get_stuff也去请求, 会触发网站的反爬虫机制.
这就需要我们像上诉代码那样加lock
代码如下:
import asyncio
import aiohttp
from asyncio import Lock
cache = {'baidu': 'www.baidu.com'}
lock = Lock()
async def get_stuff(url):
async with lock: # 等价于 with await lock: 还有async for 。。。类似的用法
# 这里可以使用async with 是因为 Lock中有__await__ 和 __aenter__两个魔法方法
# 和线程一样, 这里也可以用 await lock.acquire() 并在结束时 lock.release
if url in cache:
return cache[url]
stuff = await aiohttp.request('GET', url)
cache[url] = stuff
return stuff
async def parse_stuff(url):
stuff = await get_stuff(url)
# do some parse
async def use_stuff(url):
stuff = await get_stuff(url)
# use stuff to do something interesting
if __name__ == '__main__':
tasks = [parse_stuff('baidu'), use_stuff('baidu')]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
补充点:queue
协程是单线程的,所以协程中完全可以使用全局变量实现queue来相互通信,但是如果想要 在queue中定义存放有限的最大数目。 我们需要使用 :
from asyncio import Queue
queue = Queue(maxsize=3) # queue的put和get需要用await
7. aiohttp实现高并发爬虫
# asyncio爬虫, 去重, 入库
import asyncio
import re
import aiohttp
import aiomysql
from pyquery import PyQuery
stopping = False
start_url = 'http://www.jobbole.com'
waitting_urls = []
seen_urls = set() # 实际使用爬虫去重时,数量过多,需要使用布隆过滤器
async def fetch(url, session):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url) as resp:
print('url status: {}'.format(resp.status))
if resp.status in [200, 201]:
data = await resp.text()
return data
except Exception as e:
print(e)
def extract_urls(html): # html中提取所有url
urls = []
pq = PyQuery(html)
for link in pq.items('a'):
url = link.attr('href')
if url and url.startwith('http') and url not in seen_urls:
urls.append(url)
waitting_urls.append(urls)
return urls
async def init_urls(url, session):
html = await fetch(url, session)
seen_urls.add(url)
extract_urls(html)
async def article_handler(url, session, pool): # 获取文章详情并解析入库
html = await fetch(url, session)
extract_urls(html)
pq = PyQuery(html)
title = pq('title').text() # 为了简单, 只获取title的内容
async with pool.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute('SELECT 42;')
insert_sql = "insert into article_test(title) values('{}')".format(
title)
await cur.execute(insert_sql) # 插入数据库
# print(cur.description)
# (r,) = await cur.fetchone()
# assert r == 42
async def consumer(pool):
async with aiohttp.ClientSession() as session:
while not stopping:
if len(waitting_urls) == 0: # 如果使用asyncio.Queue的话, 不需要我们来处理这些逻辑。
await asyncio.sleep(0.5)
continue
url = waitting_urls.pop()
print('start get url:{}'.format(url))
if re.match('http://.*?jobbole.com/\d+/', url):
if url not in seen_urls: # 是没有处理过的url,则处理
asyncio.ensure_future(article_handler(url, sssion, pool))
else:
if url not in seen_urls:
asyncio.ensure_future(init_urls(url))
async def main(loop):
# 等待mysql连接建立好
pool = await aiomysql.creat_pool(host='127.0.0.1', port=3306, user='root',
password='', db='aiomysql_test', loop=loop, charset='utf8', autocommit=True)
# charset autocommit必须设置, 这是坑, 不写数据库写入不了中文数据
async with aiohttp.ClientSession() as session:
html = await fetch(start_url, session)
seen_urls.add(start_url)
extract_urls(html)
asyncio.ensure_future(consumer(pool))
if __name__ == '__main__':
loop = asyncio.get_event_loop()
asyncio.ensure_future(main(loop))
loop.run_forever()














 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









