






 本文介绍了一种常见的Python爬虫中遇到的HTML页面中文乱码问题及其解决方案。问题源于Python终端与HTML页面编码不一致导致,通过正确识别并转换编码格式可以有效解决。
本文介绍了一种常见的Python爬虫中遇到的HTML页面中文乱码问题及其解决方案。问题源于Python终端与HTML页面编码不一致导致,通过正确识别并转换编码格式可以有效解决。
问题描述
response = utils.send_request('http://www.crha.cn/gzdt.html')
print(response.text)

<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>å·¥ä½å¨æâä¸å½ç 究åå»é¢å¦ä¼</title>
<meta name="Keywords" content="å·¥ä½å¨æ,ä¸å½ç 究åå»é¢å¦ä¼,ç 究åå»é¢å¦ä¼,ç 究åå»é¢,ç 究åå»é¢å»ºè®¾" />
<meta name="Description" content="ä¸å½ç 究åå»é¢å¦ä¼æ¯å¸®å©ç 究åå»é¢æ建â临åºé®é¢âå®éªç 究â临åºæ²»çâ循ç¯æ°æºå¶ï¼å½¢æå»è¯ç»åãå»å·¥ç»åãåºç¡ä¸ä¸´åºç»åãç 究ä¸è½¬åç¸éå¥çç§æåæ°æ¨¡å¼ï¼ä¿è¿ç 究åå»é¢æ为çé¾å±éçççè¯çåºå°ãé«æ°è¯ç©è®¾å¤çç ååºå°ãåè¿å»çææ¯çåæ°åºå°åå»å¦ç§æä¿¡æ¯ç交æµåºå°ã" />
<meta http-equiv="x-ua-compatible" content="ie=emulateie7" />
<link href="/Css/Style.css" rel="stylesheet" type="text/css" />
</head>
...
原因分析
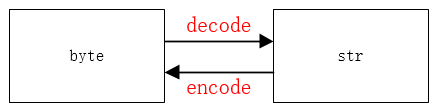
Python 终端的编码方式是 UTF-8 ,而 HTML 编码方式并不是 UTF-8 (可通过 response.encoding 查询页面编码格式),所以中文产生了乱码
解决方案
response = utils.send_request('http://www.crha.cn/gzdt.html')
print(response.encoding) # 1.查询页面的编码方式,此处为 ISO-8859-1
print(response.text.encode('ISO-8859-1').decode('utf-8')) # 2.解码再编码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>工作动态—中国研究型医院学会</title>
<meta name="Keywords" content="工作动态,中国研究型医院学会,研究型医院学会,研究型医院,研究型医院建设" />
<meta name="Description" content="中国研究型医院学会是帮助研究型医院构建“临床问题―实验研究―临床治疗”循环新机制,形成医药结合、医工结合、基础与临床结合、研究与转化相配套的科技创新模式,促进研究型医院成为疑难危重病症的诊疗基地、高新药物设备的研发基地、先进医疗技术的创新基地和医学科技信息的交流基地。" />
<meta http-equiv="x-ua-compatible" content="ie=emulateie7" />
<link href="/Css/Style.css" rel="stylesheet" type="text/css" />
</head>
...

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









