







本文采用Selenium库爬取携程网的景区评论。
Selenium介绍
Selenium是一个Web的自动化测试工具,可以按指定的命令自动操作,如让浏览器加载页面、获取数据、页面截屏等。Selenium本身不自带浏览器,需要与第三方浏览器结合才能使用。Selenium的核心是Webdriver,这是一个编写指令集的接口,具有与浏览器自动化交互的特性,提供了相应的应用程序接口(Application Programming Interface)来操作浏览器。目前支持的主流浏览器内核有Firefox、Chrome、Edge等。
(一)安装Selenium
在命令窗口输入下述命令进行安装:
pip install selenium==4.3.0
(二)配置浏览器驱动
-
要安装对应版本驱动。
针对不同的浏览器,需要根据自己电脑的操作程序安装不同驱动。这里选择使用的是Chrome浏览器,通过访问网址 chrome://version/ ,得到版本是 122.0.6261.69(64 位),于是安装对应版本驱动。

注:关于selenium的具体配置可见往期推文:
-
禁止浏览器自动更新。
由于Selenium自动化操作浏览器时需要安装浏览器驱动
Webdriver,而Webdriver驱动需要与浏览器的对应版本一致。为避免Chrome浏览器更新后原本的程序或页面无法正常运行,可以手动关闭Chrome浏览器的自动更新。打开【cmd】->输入【services.msc】->点击两个【谷歌更新服务】->在弹出的属性页面中将【启动类型】设为【禁止】。注:可查看往期推文: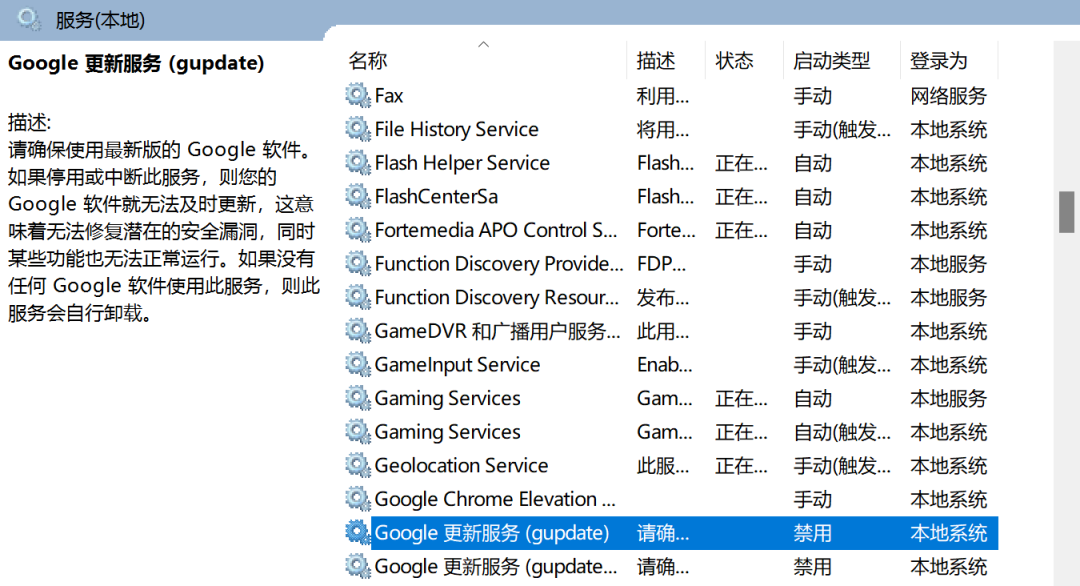
一、导入第三方库
在使用selenium.webdriver做自动化测试时,需要经常模拟鼠标和键盘的一些动作,ActionChains 类可以模拟鼠标操作,如移动、点击、悬停等。通过Webdriver模块中的By类可以为后面爬取景区时以指定方式定位标签元素。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time
import csv
from selenium.webdriver import ChromeOptions
二、实例化Chrome浏览器
使用Selenium库中的webdriver来实例化浏览器的驱动程序。可以使用option类来设置浏览器参数,如浏览器窗口大小、页面加载策略等。Headless模式是Chrome浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有Chrome浏览器支持的特性运行程序。
opt = ChromeOptions() #实例化配置对象
opt.add_argument("--headless") #配置对象添加开启无界面命令,在后台运行
opt.add_argument("window-size=1920x1080") #配置界面大小format(width,height)
opt.add_argument('--start-maximized') #最大化启动
driver = webdriver.Chrome(options=opt) #创建浏览器实例并使用配置对象opt
url = 'https://you.ctrip.com/sight/jingdezhen405/61145.html' #这里的url是所要爬取景点的网址
driver.get(url)
三、模拟下拉界面操作
在页面加载时,会根据页面大小来布局控件,因此设置延长页面的存在时间,并模拟手下拉的操作,让没有显示的界面加载出来。有时通过Selenium无法直接实现页面上的操作,如滚动条、时间控件等,此时需要借助JavaScript完成。JavaScript是一种脚本语言,在客户端,即浏览器运行。Webdriver提供了一种内置方式操作,可以调用js代码实现操作:driver.execute_script(js)。
-
JavaScript声明并对元素执行单击操作:
argument[0].click() -
execute_script()使用的JavaScript语句作为字符串值调用方法:driver.execute_script("arguments[0].click();",button) -
平时测试时可以用
time.sleep()来强制等待,生产环境下可用implicity_wait()来固定时间等待页面元素全部加载完成。
def to_the_buttom():
js = 'document.getElementsByClassName("search-body left_is_mini")[0].scrollTop=10000'
driver.execute_script(js)
def to_the_top():
js = "var q=document.documentElement.scrollTop=0" # 滚动到最上面
driver.execute_script(js)
def to_view():
driver.implicitly_wait(10)#隐式等待10s,条件成立则立即结束等待
to_the_buttom()
time.sleep(3)
button = driver.find_element(By.CSS_SELECTOR,'li.ant-pagination-next>span') #这里是通过CSS选择器定位翻页元素
driver.execute_script("arguments[0].scrollIntoView();", button)
四、翻页获取用户评论
接下来就是编写主函数,主要是嵌套两个循环,古窑民俗博览区用户评论共300页,每页有10条评论。通过访问页面获取标签元素,一页获取完点击下一页,并用创建的csv文件进行存储。在本次爬取中,我们使用追加模式a打开了一个名为“古窑民俗博览区评论.csv”的文件,并用write()方法在文件中添加用户评论“text”。with open()是python用来打开文件的,会在使用完毕后自动关闭文件。
-
with open(file='要打开的路径名称(或保存内容的地址)',mode='r/w/a',encoding='utf-8') as f:如果没有指定的路径,会自动新建文件,无需提前新建。mode有三种常用模式,默认是r,即只读模式;w即只写模式,会清除之前写的内容;这里用的是a,即追加模式,会在已经写的内容基础上追加新的内容。 -
以
utf-8编码方式写入csv文件时,会出现除英文外全是乱码的情况,因此这里指定编码方式为utf-8-sig,即带有签名的utf-8(UTF-8 with BOM),可以有效解决Excel在读取csv文件时的乱码问题。 -
通过
driver.find_element(By.xxx,value)定位元素。selenium有八种主要的元素定位方式,如:class name、xpath、css selector、id、name、tag name等,这里所使用的是前三种定位方式。 -
其中,
find_element_by_xpath()有多种方法,查找具体的元素时必须在前面以//开头,表示从当前节点寻找所有的后代元素。//*[@style]表示查找包含style的所有元素
with open("古窑民俗博览区评论.csv", "a", encoding='utf-8-sig',newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('景点','日期','用户评论'))
for y in range(1,301):
time.sleep(3)
for x in range(10):
try:
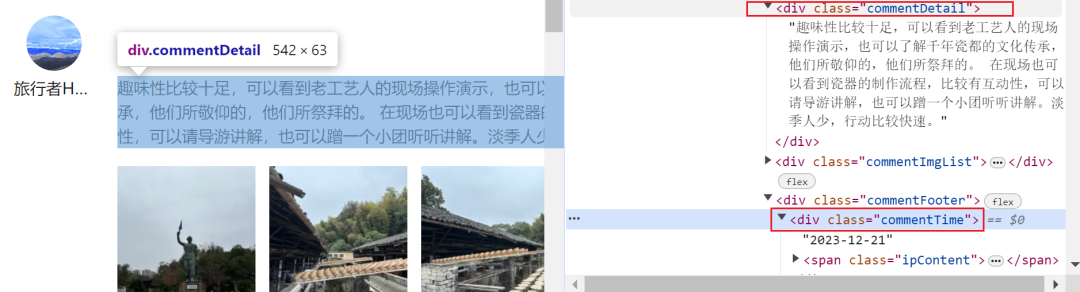
text = driver.find_elements(By.CLASS_NAME, "commentDetail")[x].text
text = text.strip()
text = text.replace('\n','')
date = driver.find_elements(By.CLASS_NAME,"commentTime")[x].text
date = date.strip()
date = date.replace('\n','')
csvwriter.writerow(('古窑民俗博览区',date,text))
f.flush()
print(text)
except:
pass
el = driver.find_element(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[7]/a')
ActionChains(driver).move_to_element(el).click().perform()
print(y)
全套代码
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time
import csv
from selenium.webdriver import ChromeOptions
opt = ChromeOptions()
opt.add_argument("--headless")
opt.add_argument("window-size=1920x1080")
opt.add_argument('--start-maximized')
driver = webdriver.Chrome(options=opt)
url = 'https://you.ctrip.com/sight/jingdezhen405/61145.html'
driver.get(url)
def to_the_buttom():
js = 'document.getElementsByClassName("search-body left_is_mini")[0].scrollTop=10000'
driver.execute_script(js)
def to_the_top():
js = "var q=document.documentElement.scrollTop=0" # 滚动到最上面
driver.execute_script(js)
def to_view():
driver.implicitly_wait(10)#隐式等待10s,条件成立则立即结束等待
to_the_buttom()
time.sleep(3)
button = driver.find_element(By.CSS_SELECTOR,'li.ant-pagination-next>span')
driver.execute_script("arguments[0].scrollIntoView();", button)
with open("古窑民俗博览区评论.csv", "a", encoding='utf-8-sig',newline='') as f:
csvwriter = csv.writer(f)
csvwriter.writerow(('景点','日期','用户评论'))
for y in range(1,301):
time.sleep(3)
for x in range(10):
try:
text = driver.find_elements(By.CLASS_NAME, "commentDetail")[x].text
text = text.strip()
text = text.replace('\n','')
date = driver.find_elements(By.CLASS_NAME,"commentTime")[x].text
date = date.strip()
date = date.replace('\n','')
csvwriter.writerow(('古窑民俗博览区',date,text))
f.flush()
print(text)
except:
pass
el = driver.find_element(By.XPATH, '//*[@id="commentModule"]/div[6]/ul/li[7]/a')
ActionChains(driver).move_to_element(el).click().perform()
print(y)
time.sleep(10)
driver.close()
运行结果
















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









