







 本文介绍了时间戳概念的频繁模式挖掘,重点解析了GSP和SPADE两种算法。GSP算法结合垂直列表数据库和哈希树,而SPADE算法通过先验性质和特定推导公式优化了计算效率,减少了I/O次数和内存消耗。作者翻译并简化了相关论文,提供了算法的理解和实现。
本文介绍了时间戳概念的频繁模式挖掘,重点解析了GSP和SPADE两种算法。GSP算法结合垂直列表数据库和哈希树,而SPADE算法通过先验性质和特定推导公式优化了计算效率,减少了I/O次数和内存消耗。作者翻译并简化了相关论文,提供了算法的理解和实现。
本文核心理论依托于MOHAMMED J. ZAKI于Machine Learning, 42, 31–60, 2001发表的文章,由于国内暂时没有相应文献对SPADE算法做详细讲解,本人翻译原文后以通俗易懂的形式展现给读者。英文水平捉急,若有个别地方理解有误望批评指正。
1.什么是时间戳概念的频繁模式挖掘?
所谓时间戳(time-stamp)就是加入了时间序列的概念,即每次发生的时间都有时间先后的顺序,在前面讲解的Apriori算法中并没有加入此概念,虽然Apriori加入了先验性质以减少每轮遍历的次数,但是由于加入了“时间发生先后”的概念,导致时间复杂度大大增加,无疑需要一种新颖的办法解决该问题。
2.GSP算法
GSP算法是加入了垂直列表数据库和哈希树概念的Apriori算法,并且依旧使用连接步、剪枝步完成计算。其处理思路如下:
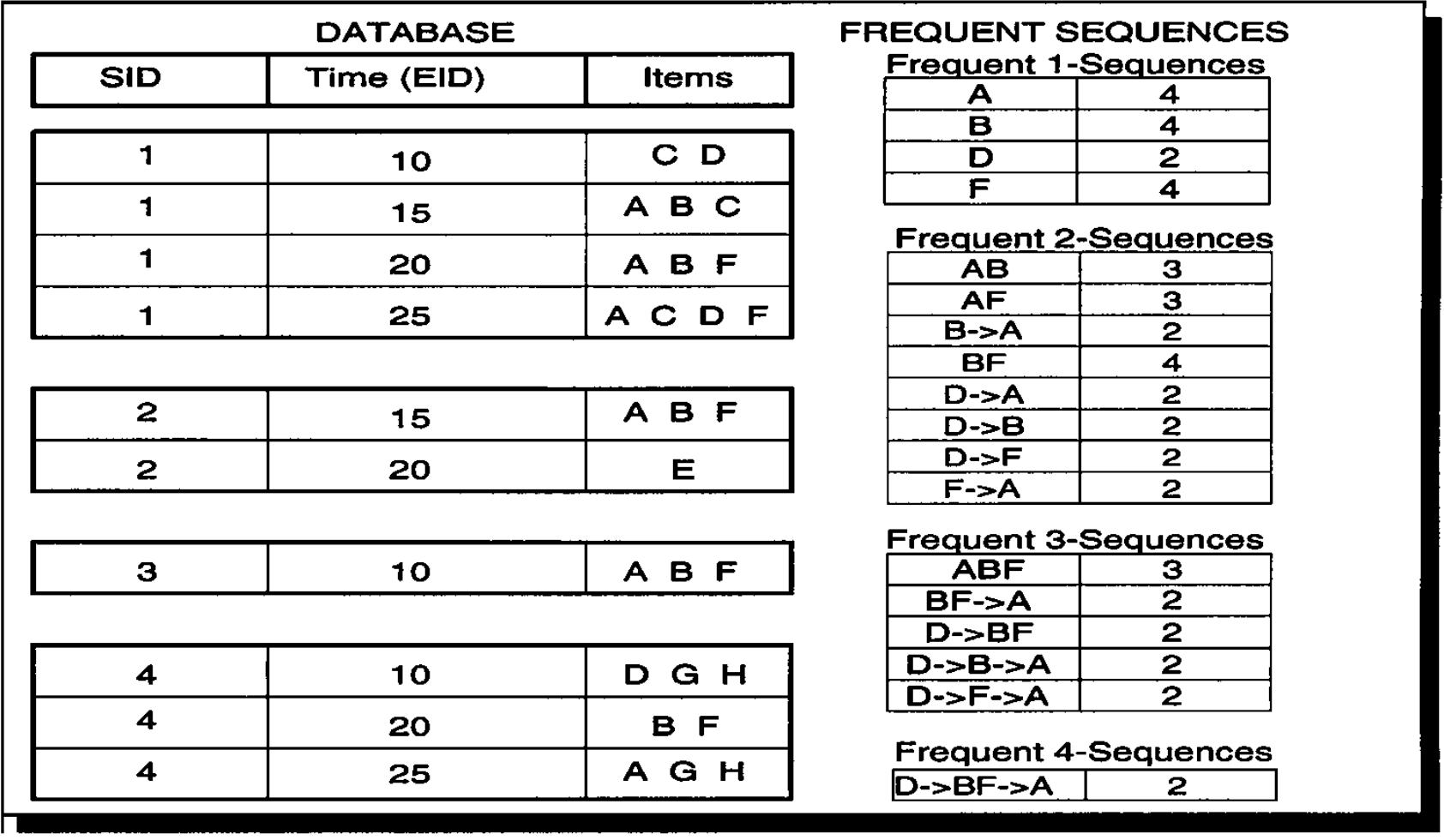
上图是我们的原始数据,其中SID表示事件号,EID表示时间戳(即什么时候发生了该动作),我们可以看到,在一个事件内可以在多个时间发生动作,在一个时间点内也可以发生多个动作,诸如x->y这样的行为表示先发生了x,之后发生了y,之间隔了多长时间无所谓,但是一定要在一个SID中。
如果假定支持度为2,那么1成员频繁序列有A、B、D、F四个成员,出现的次数如右图,以成员A为例,则表示A成员在SID=1~4这四个事件中都出现过,在计算2成员频繁序列中采用广度搜索的哈希树作为遍历手段,如下图所示:
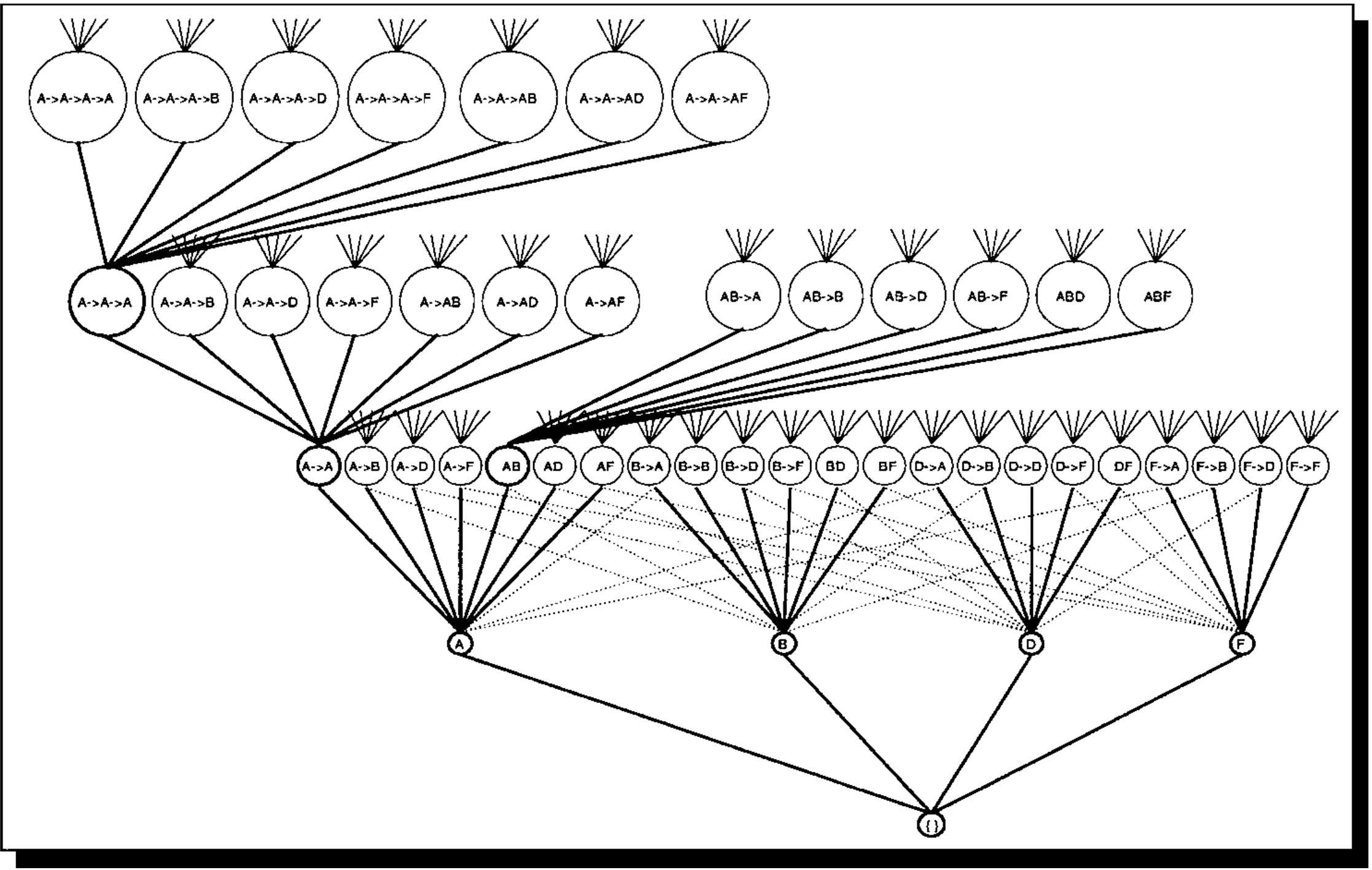
我们可以看到,再加入时间戳概念后,遍历的复杂度大大提高,因为不光要考虑诸如AB这样的“同时发生”的概念,概要考虑A->B这样的先后次序发生概念,在本data中寻找2成员频繁项集一共需要(3*2)*4=24次,然后每次需要在遍历全部的data来判断该项目是否频繁,那么一共需要计算24*10=240次,几百次对计算机来说不成问题。最终计算结果如下图:
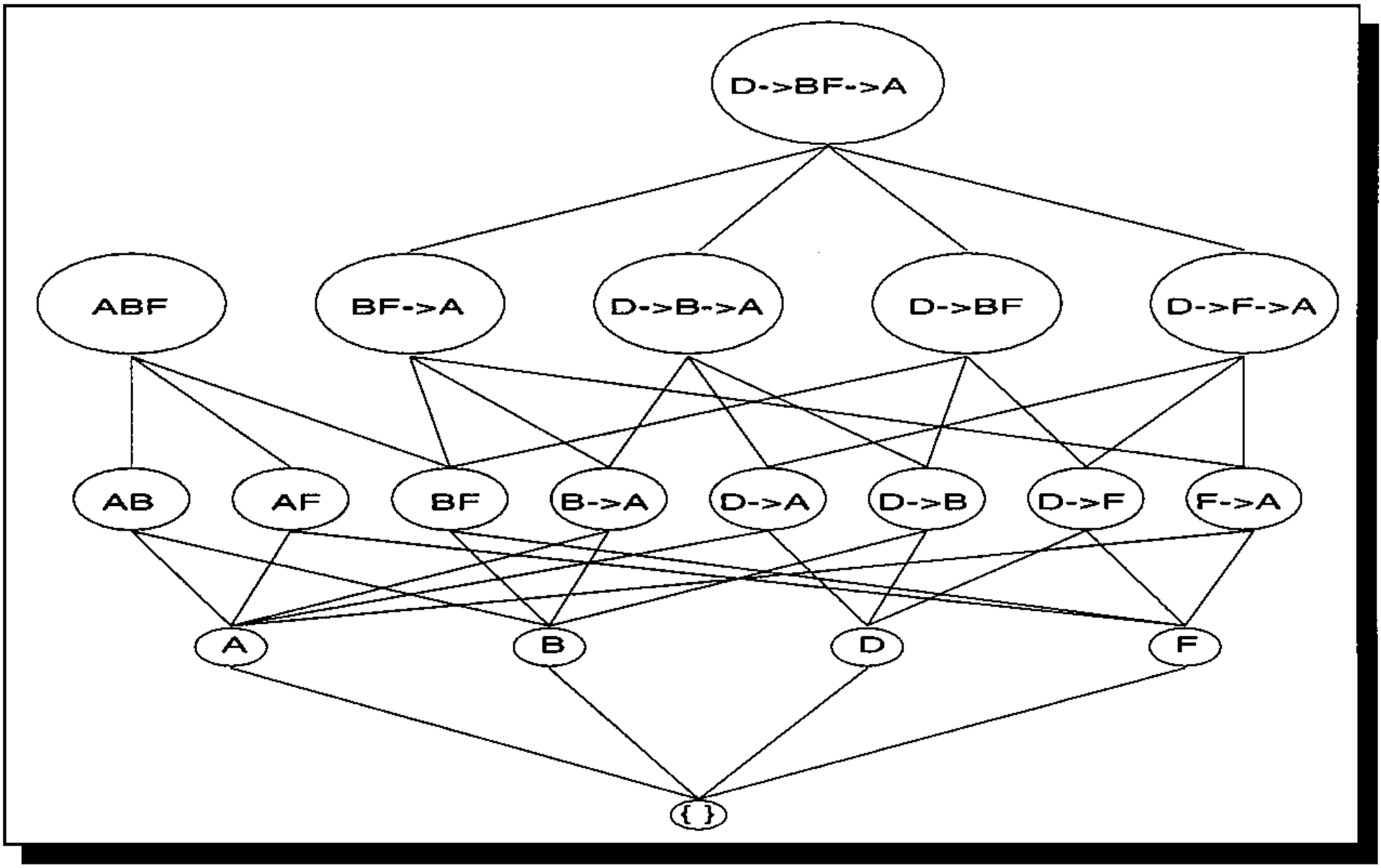
我可以看到,3成员频繁项集虽然看起来匹配的很轻松,但是依旧要遍历8次原始数据,一旦数据巨大,无疑这笔开销会异常恐怖,为了进一步提升效率,学者研发了SPADE算法。
2.SPADE算法
SPADE算法依旧使用传统的先验性质,即连接步+剪枝步的经典组合,思想跟GSP大致相同,其中寻找1成员和2成员频繁项集方法跟GSP完全形同,在之后的3成员及之后的频繁项计算中,采取了一种“作弊”的办法 (= -) ,该办法套用了三种屡试不爽的公式,如下:
1.如果诸如成员PA,PD这样的形式出现在2频繁项集中,则能推导出PBD这样的三成员元素。
2.如果出现诸如PB,P->A这样的形式出现在2频繁项集中,则能推导出PB->A这样的三成员元素。
3.如果出现诸如P->A,P->F这样的形式出现在2频繁项集中,则能推导出P->AF或P->A->F或P->F->A这样的三成员元素。

以上推推导出的三成员元素注意!仅仅是“有可能”是频繁的元素,至于是不是频繁的,还得去原始data中进一步遍历、判断。
比如在本例中AB,AF是两个频繁的2成员项,那么有可能注意是“有可能”存在且仅存在ABF这样的3成员频繁项,经过10次计算遍历了一遍data发现ABF确实是频繁的。
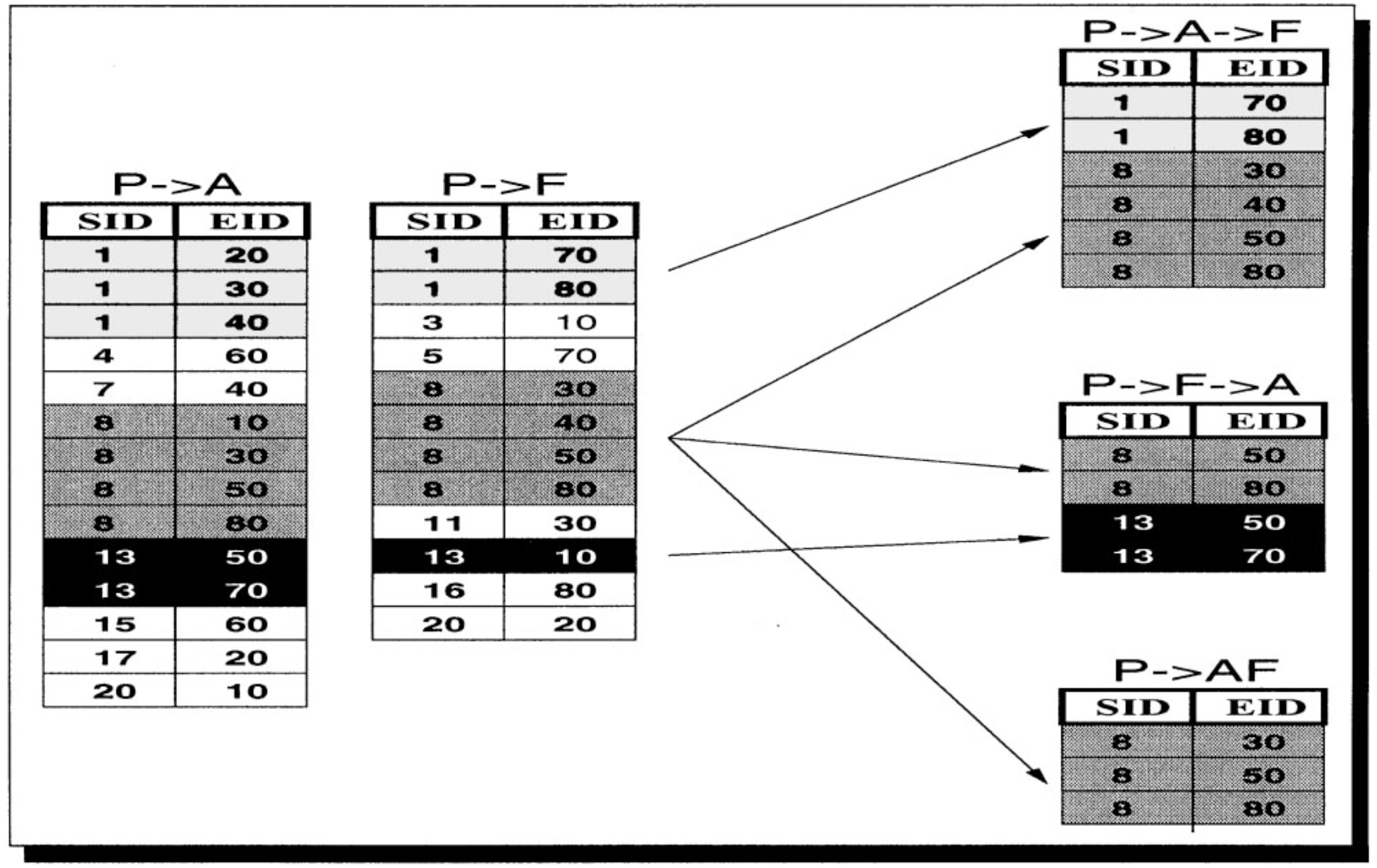
在本例中出现了一组奇葩,即D->F,F->
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









