






(一)鸢尾花聚类案例
背景
聚类分析是数据挖掘中常用的算法,本文将通过鸢尾花数据展示聚类算法在本平台中的使用方式。本案例,主要涉及归一化与kmeans聚类两个算法。
数据
鸢尾花数据集(IRIS)是一个经典的数据集。其中有150个样本,我们目标是分成三类,分别是山鸢、变色鸢尾、维基尼亚鸢。数据结构如下:
| 列名 | 含有 | 类型 |
|---|---|---|
| sepal_length | 花萼长度 | double |
| sepal_width | 花萼宽度 | double |
| petal_length | 花瓣长度 | double |
| petal_width | 花瓣宽度 | double |
| class | 花的类别 | String |
数据探索流程
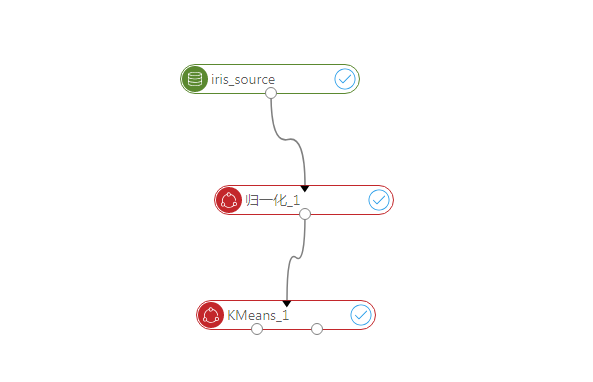
第一步,在数据源节点中拖动鸢尾花数据集,之后在组件中拖入归一化以及kmeans聚类节点。之后将节点用线连接
第二步,点击归一化节点,在右侧选择需要归一化的列,点击1处,之后再选择框中将double类型的数据选择上,点击2处的ok保存。归一化只能处理double类型。 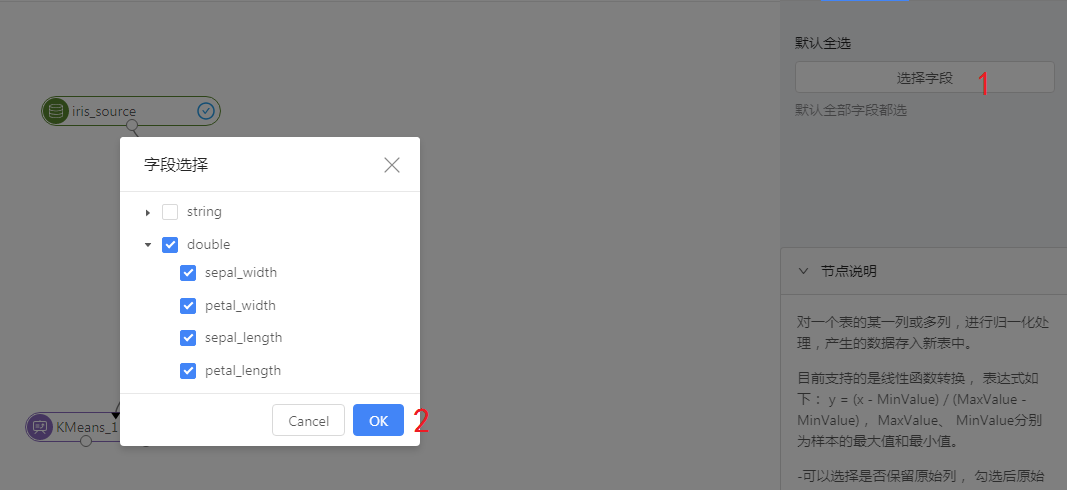
第三步, 在下图1处右键点击归一化节点,在右键菜单中选择2处的执行到此处按钮。开始执行程序。 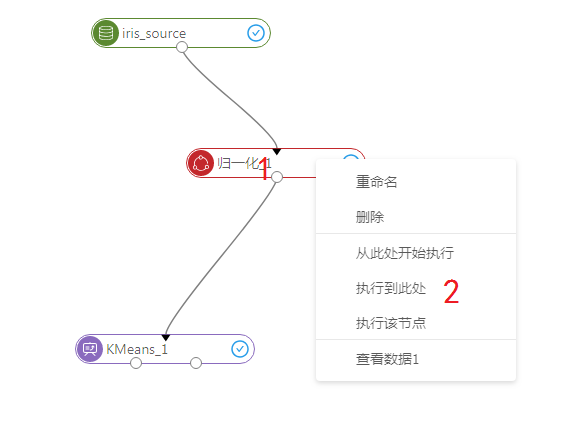
第4步 ,在步骤3执行成功后,点击kmeans节点。首先进行参数设置,类别个数代表聚类后的类别数,填入数字即可。其他参数根据需要设置或保持默认值

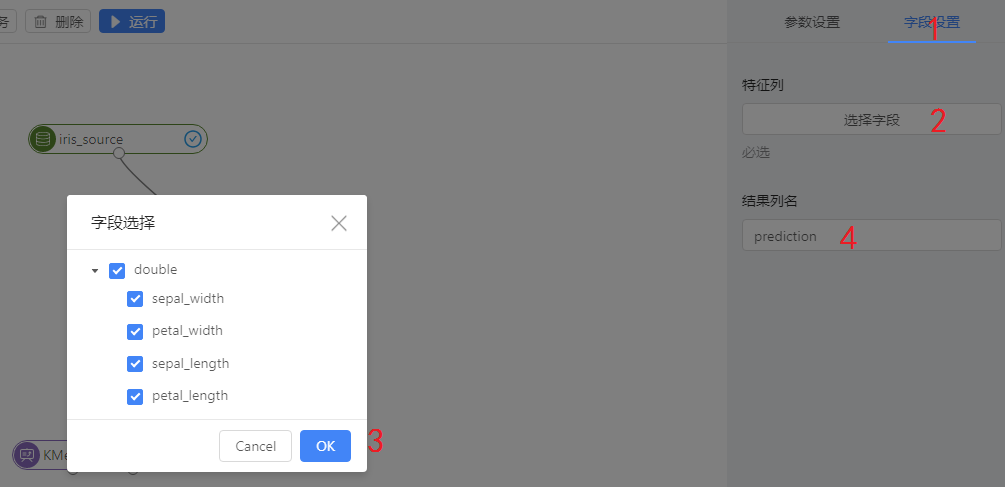
之后点击下图中的1进行字段设置,点击图中数字2选择字段,之后点击数字3保存字段。数字4处是输出的列名,可保持默认。
5 运行整个任务,成功后右键kmeans节点,点击查看数据1即可。结果展示如下 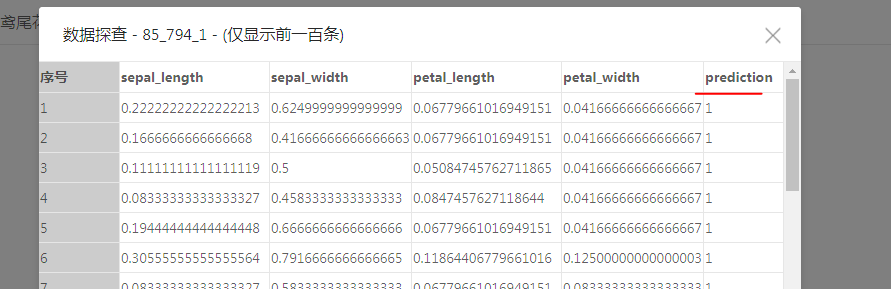
(二)新闻聚类示例
背景
新闻分类是文本挖掘领域较为常见的场景。目前很多媒体或是内容生产商对于新闻这种文本的分类常常采用人肉打标的方式,消耗了大量的人力资源。本文通过LDA算法挖掘文章的主题。
数据集结构
| 列名 | 含意 | 类型 |
|---|---|---|
| contenttitle | 文章标题 | String |
| content | 文章内容 | String |
| label | 文章类别 | String |
数据探索流程
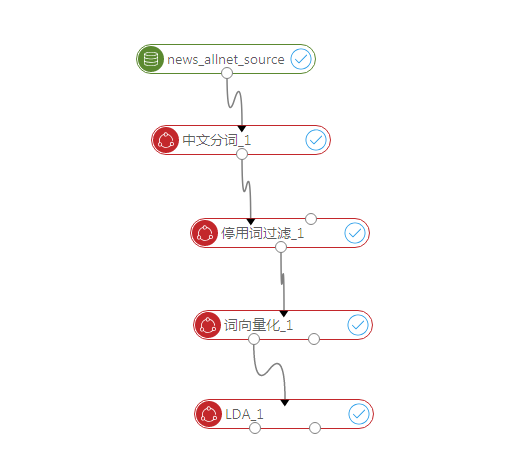
第一步 从数据源中拖拽新闻信息表,从组件中拖拽中文分词、停用词过滤、词向量化、Lda节点。按照上图进行连接。
第二步 点击中文分词节点,在右侧栏中选择列,按如下图中数字操作 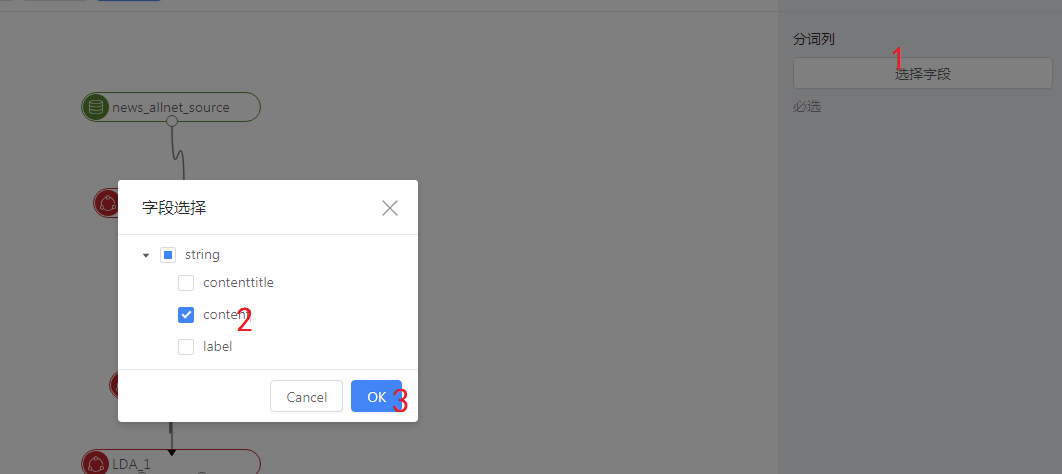
保存好之后,右键中文分词节点选择运行此节点,直到运行结束
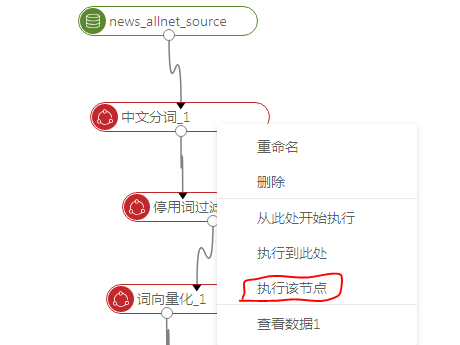
第三步 点击停用词过滤节点,在右侧栏选择列,按下图数字顺序操作 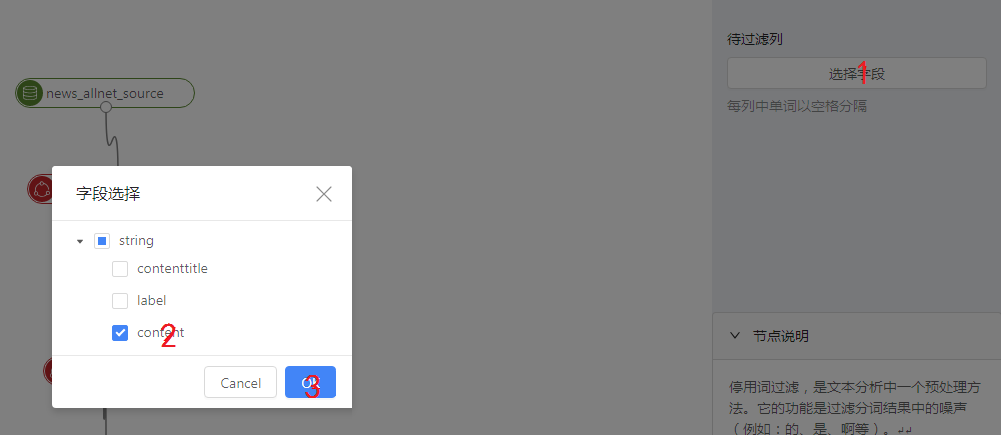
之后右键停用词过滤节点,点击运行该节点
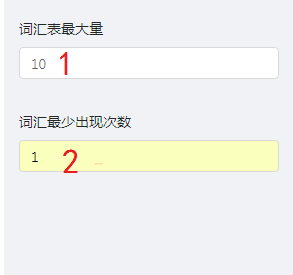
第四步 点击词向量化节点,在右侧栏填写参数,如下图
之后在字段设置中选择字段,安装下图数字填写 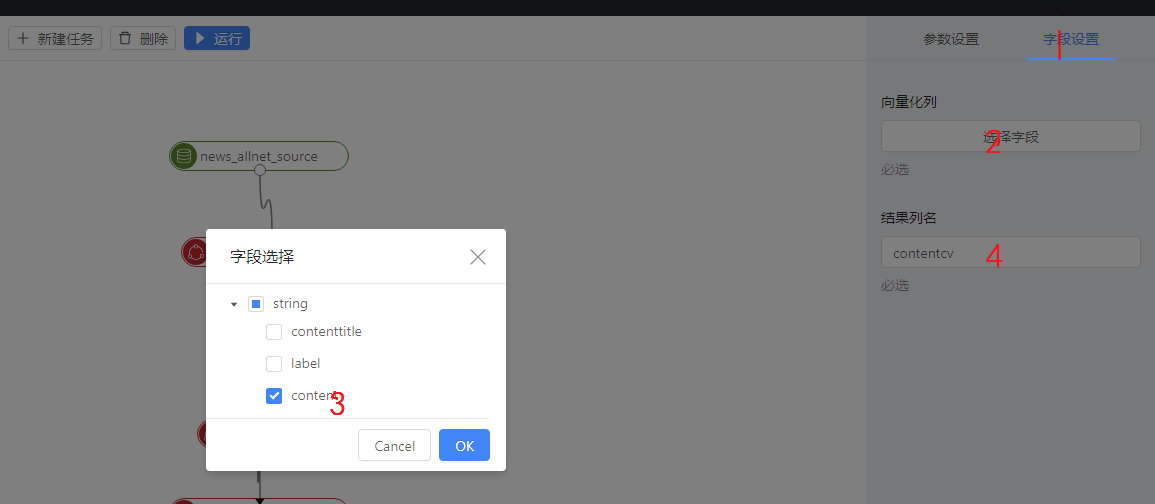
之后右键词向量化节点,点击运行该节点
第5步 点击LDA节点,在右侧参数输入栏填入聚类类别数,其他参数可根据需要填写,之后保存。
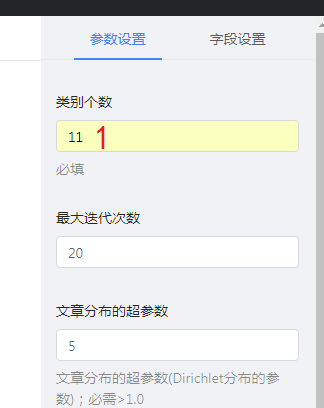
填完参数后,选择字段设置,进行字段设置,按照下图数字操作即可
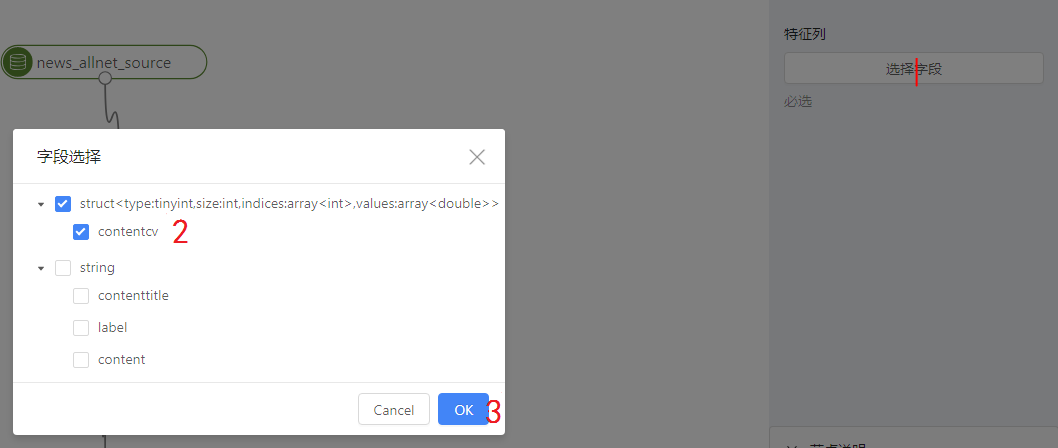
第6步,点击任务运行,运行整个任务。任务所有节点运行成功后,可右键LDA,点击查看数据1,查看聚类结果。















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









