







目录
ArithmeticProgression类实现等差数列生成器
前言
迭代器模式:扫描内存中放不下的数据集时,要找到一种惰性获取数据项的方式,即按需一次获取一个数据项,这就是迭代器模式。
python为了抽象出迭代器模式,加入了关键字yield,这个关键字用于构建生成器,其作用与迭代器一样。所有生成器都是迭代器,因为生成器完全实现了迭代器接口。根据《设计模式:可复用面向对象软件的基础》中的定义,迭代器用于从一个集合中取出元素,生成器则用于凭空生成元素,但在python社区中,大多时候把迭代器和生成器视作同一概念。
在python3中,即使是内置的range()函数也返回一个类似生成器的对象,而在以前都是返回完整的列表,如果一定要range()返回列表,则必须明确指明,list(range(100))。
python中所有的集合都是可迭代的,python语言内部,迭代器可以支持以下功能:
- for 循环
- 构建和扩展集合类型
- 逐行遍历文本文件
- 列表推导、字典推导和集合推导
- 元组拆包
- 调用函数时,使用*拆包实参
一、Sentence类第一版:单词序列
Sentence第一版实现
import re
import reprlib
RE_WORD = re.compile('\w+') # 匹配字母数字下划线,重复一次或多次
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text) # 1
def __getitem__(self, index):
return self.words[index] # 2
def __len__(self): # 3
return len(self.words)
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text) # 4
s = Sentence('"The time has come,", the Walrus said,')
for word in s:
print(word)- re.findall函数返回一个字符串列表,里面的元素是正则表达式的全部非重叠匹配
- self.words中保存的是findall函数返回的结果,因此直接返回指定索引位上的单词
- 为了完善序列协议,实现了__len__方法,但是如果只是为了方对象可迭代,只需要实现__getitem__即可
- reprlib.repr用于生成大型数组结构的简略字符串表示,默认情况下最多30个字符
测试结果如下:成功实现迭代
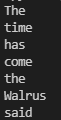
因为实现了__getitem__和__len__,因此这一版Sentence类是序列,可以按索引获取单词:

序列可以迭代的原因:iter函数
解释器需要迭代对象x时,会自动调用iter(x):
- 检查对象是否实现了__iter__方法,如果实现了就调用它,获取一个迭代器
- 如果没有实现__iter__方法,但是实现了__getitem__方法,python会创建一个迭代器,尝试按顺序从索引0开始获取元素
- 如果尝试失败,python抛出TypeError异常,提示 “××× object is not iterable”
任何python序列都可迭代的原因是,他们都实现了__getitem__方法(事实上标准序列也都实现了__iter__方法)。
在白鹅类型认为:只要实现了__iter__方法(哪怕函数体直接pass,只要有这个函数名就行),那么就认为对象是可迭代的。由于abc.Iterable类实现了__subclasshook__方法,因此不需要创建子类也不需要注册,就可以使用isinstance方法来判断对象是否可迭代,如下:

但是用isinstance()是不能判断第一版的Sentence类的对象的,因为没有实现__iter__方法。要检查对象x是否可迭代,最准确的方法还是调用iter(x),如果不可迭代会抛出TypeError异常,且iter函数会考虑__getitem__方法,而abc.Iterable则不考虑。
二、可迭代的对象与迭代器的对比
python从可迭代的对象中获取迭代器对象。
可迭代的对象:使用iter内置函数可以获取迭代器的对象。如果对象实现了能返回迭代器的__iter__方法,那么对象是可迭代的。序列都是可迭代的。实现了__getitem__方法,而且其参数是从零开始的索引,这种对象也可以迭代。
下面是一个简单的for循环,迭代一个字符串,这里字符串'ABC'是可迭代的对象,背后是有迭代器的,只不过我们看不到。

如果不用for语句,用while循环模拟,要像下边这样写:

- 用iter函数使用可迭代对象s构建迭代器it
- 不断在迭代器上调用next函数,获取下一个字符
- 如果没有字符了,迭代器会抛出StopIteration异常
- 使用对it的应用,即废弃迭代器对象
- 退出循环

标准迭代器接口有两个方法:
- __next__,返回下一个可用的元素,如果没有元素了,就抛出StopIteration异常。
- __iter__,返回self,以便在应该使用可迭代对象的时候使用迭代器,比如for循环中。
如下UML图中Iterable和Iterator分别是可迭代的对象与迭代器对象对应的抽象基类。Iterator继承自Iterable。
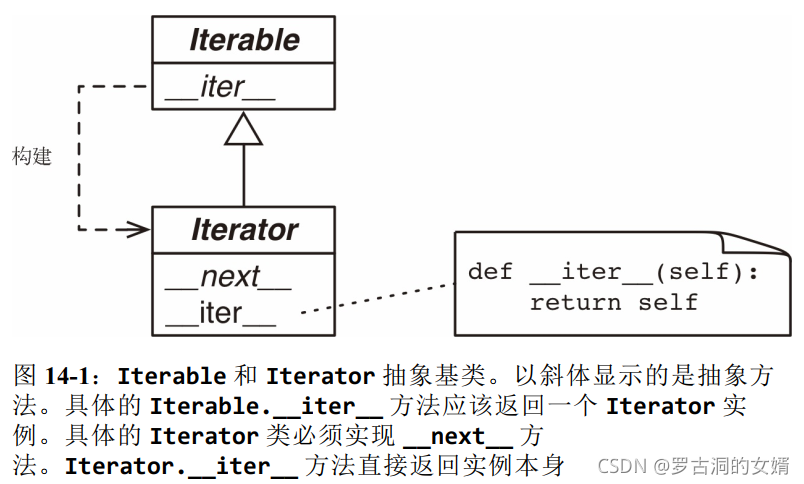
检查对象x是否位迭代器最好的方式是调用isinstance(x, abc.Iterator),得益于Iterator.__subclasshook__方法,即使对象x所属的类不是Iterator类的真实子类或虚拟子类,这样检查也是有效的。
下面例子是从控制台观察迭代器的构建过程,以及用next函数使用迭代器的过程:


- 创建一个Sentence实例s3,包含3个单词。
- 用iter函数从可迭代对象s3中获取迭代器对象it
- 调用next来操作迭代器对象,获取下一个单词
- 没有单词了,抛出StopIteration异常
- 到头后,迭代器没用了,可以看到用迭代器初始化的列表为空,迭代器已经不能取元素
- 如果想再次迭代,要重新构建迭代器
因为迭代器只需__next__和__iter__两个方法,所以出了调用next()方法,以及捕获StopIteration异常之外,没有办法检查是否还有遗留的元素。此外,也没有办法还原迭代器。如果想再次迭代,那就要调用iter函数,传入之前构建迭代器的可迭代对象,再次获取迭代器。
综上,迭代器定义如下,迭代器是这样的对象:
- 实现了无参数的__next__方法,返回序列中的下一个元素;
- 如果没有元素了,就抛出StopIteration异常
- 实现了__iter__方法,因为只要实现了__iter__方法,那么对象就是可迭代的,因此迭代器也可以迭代,也是可迭代对象
三、Sentence类第二版:典型的迭代器
第二版Sentence类实现典型的迭代器设计模式
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self): # 1
return SentenceIterator(self.words) # 2
class SentenceIterator:
def __init__(self, words):
self.words = words # 3
self.index = 0 # 4
def __next__(self):
try:
word = self.words[self.index] # 5
except IndexError:
raise StopIteration() # 6
self.index += 1 # 7
return word # 8
def __iter__(self): # 9
return self- 与第一版Sentence类相比,第二版这里多了个__iter__方法,且这一版没有实现__getitem__方法,为的是明确表示这个类可迭代,因为实现了__iter__方法。
- 根据可迭代协议,__iter__方法实例化并返回一个迭代器。
- SentenceIterator实例化迭代器对象时需要引用单词列表。
- self.index用于确定下一个要获取的单词,从这里也可以看出,迭代器内部是没有还原机制的,index只加不减。
- __next__方法内部获取self.index索引位上的单词。
- 如果索引位上已经没有单词,那么抛出StopIterator异常。
- 递增self.index的值。
- 返回当次迭代到的单词。
- 实现self.__iter__方法,返回迭代器对象自身的引用。
在这里示例中,其实没必要在迭代器SentenceIterator类中实现__iter__方法,不过这样做是对的,因为迭代器应该实现__next__和__iter__两个方法,这样做能让迭代器通过issubclass(SentenceInterator, abc,Iterator)测试。如果一开始我们就让SentenceIterator类继承abc.Iterator类,那么它会自动继承abc.Iterator.__iter__这个具体方法。
不要把可迭代对象变成自身的迭代器
- 可迭代对象:实现__iter__方法,该方法每次都实例化一个新的迭代器。
- 迭代器:要实现__next__方法,每次返回单个元素,此外还要实现__iter__方法,返回迭代器本身。
可迭代的对象不是迭代器,是通过生成迭代器来实现迭代。
除了__iter__方法之外,你可能还想在Sentence类中实现__next__方法,让Sentence实例既是可迭代的对象,也是自身的迭代器,但是这样做非常糟糕,是常见的反模式。在《设计模式》一书中写到了迭代器模式的用途:
- 访问一个聚合对象的内容而无需暴露它的内部表示
- 支持对聚合对象的多种遍历
- 为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)
为了"支持多种遍历",必须能从同一个可迭代的对象中获取多个独立的迭代器,而且各个迭代器要能维护自身的内部状态,因此迭代器模式的正确实现方式是:每次调用iter(my_iterable)都新键一个独立的迭代器。
综上,可迭代的对象一定不能是自身的迭代器,即可迭代的对象必须实现__iter__方法,但不能实现__next__方法。另一方面,迭代器应该一直可以迭代,迭代器的__iter__方法应该返回自身。
四、Sentence类第三版:生成器函数
Sentence第三版
实现相同功能,但却更pythonic的方式是:用生成器函数代替迭代器类SentenceIterator类。
import re
import reprlib
RE_WORD = re.compile('\w+')
class Sentence:
def __init__(self, text):
self.text = text
self.words = RE_WORD.findall(text)
def __repr__(self):
return 'Sentence(%s)' % reprlib.repr(self.text)
def __iter__(self):
for word in self.words: # 1
yield word # 2
return # 3
- for循环迭代self.words
- 产出当前的word
- 这个return不是必要的,这个函数可以直接落空,自动返回。不管有没有return语句,生成器函数都不会抛出StopIteration异常,而是在生成完全部值之后会直接退出。
用以上方法,不需要再定义一个迭代器类!
在第二版的的Sentence类中,可迭代对象的__iter__方法会调用SentenceIterator类的构造函数创建一个迭代器并将其返回,而在第三版中,则是每次调用__iter__方法都会自动创建一个生成器,这里的__iter__方法实际上是一个生成器函数。
生成器函数的工作原理
只要python函数的定义体中有yield关键字,该函数就是生成器函数。调用生成器函数时,会返回一个生成器对象,即生成器函数是生成器工厂。
下面是一个生成器函数示例:


- 该函数是生成器函数,因为函数体中包含关键字yield。
- 生成器函数定义体中通常有循环,但这不是必要条件,示例函数中定义体是三个yield语句。
- gen_123是一个函数对象,python中的函数都是一等对象。
- 但是调用gen_123()时,返回一个生成器对象。
- 生成器是迭代器,会生成传给yield关键字的表达式的值,这里虽然没有循环,但是有三个yield语句可以生成三个值,即1 2 3。
- 把生成器对象赋值给g
- 因为g是迭代器,因此调用next(g)可以获取yield生成的下一个元素。
- 生成器函数的定义体执行完毕后,生成器对象会抛出StopIteration异常。
生成器函数的内部工作机制为:
- 调用生成器函数会创建一个生成器对象,包裹生成器函数的定义体。
- 把生成器函数传给next()函数时,生成器函数会向前,执行函数定义体中的写一个yield语句,返回产出的值,并在函数定义体的当前位置暂停。
- 最终函数定义体执行完毕返回时,外层的生成器对象会抛出StopIteration异常。

下面例子使用for循环更清楚地说明生成器函数体的执行过程:

- 定义生成器函数的方式与普通函数一样,只不过要使用yield关键字。
- 在标号5处,for循环第一次隐式调用next函数时,会打印start,然后停在第一个yield语句处,生成值 ‘A’
- 在for循环第二次隐式调用next函数时,会打印'continue',然后停在第二个yield语句,生产值'B'。
- 第三笔调用next()函数时,会打印end,然后到达函数定义体的末尾,导致生成器对象抛出StopIterator异常。
- 迭代时,for机制的作用与 g = iter(gen_AB())一样,用于获取生成器对象(),然后每次迭代时调用next(g),即生成器对象只有一份,而next(g)要调用多次。
- 循环体打印 ---> 和next(g)返回的值,但是生成器函数体中的print函数输出结果之后才会看到这个输出。
- start是生成器函数体中print语句输出的结果。
- 生成器函数体中的yield ‘A’ 语句会生成值A,提供给for循环使用,而A会赋值给变量C,最终输出 ---> A,然后生成器停在这一句。
- for循环隐式第二次调用next(g), 生成器从上边生成A的那一句继续执行,于是再次执行到生成器函数定义体中的print语句。
- yield 'B' 生成值B,提供给for循环使用,生成器停在这一句。
- 第三次调用next(g),执行print语句,继续迭代,前进到了生成器函数定义体的末尾,生成器对象抛出StopIterator异常。for机制会捕获异常,因此循环到此终止没有报错。

五、Sentence类第四版:惰性实现
惰性:比如Iterator的接口,next(my_iterator)一次生成一个元素。前三版Sentence类设计都不具有惰性,因为__init__方法急迫地都见好了文本中的单词列表self.words,这样就得处理整个文本,非常占内存。
re.finditer函数是re.findall函数的惰性版本,返回的不是列表,而是一个生成器,按需生成re.MatchObject实例。如有有很多匹配,re.finditer函数能节省大量内存。


- 不再需要words列表。
- finditer函数构建一个生成器,包含self.text中匹配RE_WORD的单词,产出MatchObject实例match。
- match.group()方法从MatchObject实例中提取匹配正则表达式的具体文本。
六、Sentence类第五版:生成器表达式
简单的生成器函数可以替换成生成器表达式。
生成器表达式可以理解为列表推导式的惰性版本:不会迫切地构建列表,而是返回一个生成器,按需惰性生成元素。也就是说,列表推导是制造列表的工厂,生成器表达式是制造生成器的工厂。

![]()
- gen_AB是生成器函数。
- 列表推导迫切地迭代生成器函数gen_AB产生的生成器对象,来得到列表res1。
- 用for循环来迭代res1列表,所有序列都是可迭代对象。
- 把生成器表达式生成的生成器赋值给res2。这里生成器函数的函数体并没有真正执行,只有当需要取元素的时候才会执行。
- res2是一个生成器对象。
- 只有for循环迭代生成器res2时,gen_AB才会真正执行,for循环每个迭代时会隐式调用next(res2),前进到gen_AB函数中的下一个yield语句。

与上一个版本的区别是__iter__方法,这里__iter__不再是生成器函数了,没有用yield,而是使用生成器表达式构建的生成器,然后将其返回,最终效果一样:调用__iter__方法得到一个生成器对象。
生成器表达式是语法糖:完全可以替换成生成器函数,只不过有时候用生成器表达式更方便。
七、何时使用生成器表达式
- 如果生成器表达式要分成多行写,那么请使用生成器函数写。
- 此外,生成器函数可以使用多个语句实现更复杂的逻辑,也可以作为协程使用。
- 且生成器函数有名称,因此可以重用。
八、等差数列生成器
典型的迭代器模式作用很简单,就是遍历数据结构。
但即使不是从集合中获取元素,而是 获取序列中即时生成的下一个值时,也用得到这种基于方法的标准接口。例如,内置的range函数用于生成有穷整数等差数列,itertools.count函数用于生成无穷等差数列。
ArithmeticProgression类实现等差数列生成器

- __init__方法有两个参数,begin和step,end是可选的,如果end的值为None,那么生成无穷序列。
- 把self.begin赋值给result,赋值之前先强制类型转换,转换成前边self.being + self.step得到的类型(算术运算符会隐式进行强制类型转换),这是为了保证数列的首项与其它项的类型一样。
- 为了提高可读性,创建forever变量,如果self.end的值是None,那么forever的值是True,生成的是无穷序列。
- forever等于True即self.end等于None的时候,会一直循环下去,生成无穷序列,否则当result大于等于self.end的时候结束。循环退出则函数也随之退出。
- 生成当前的result值。
- 生成可能存在的下一个结果,并重新绑定到result上。这个值可能永远不会产出,因为while循环可能会终止。
ArithmeticProgression类的用法如下:

![]()
aritprog_gen生成器函数实现等差数列生成器
如果只是为了得到一个等差数列生成器,其实没必要定义一个类,直接定义一个生成器函数也成,生成器函数也可以有参数,如下所示:

使用itertools模块生成等差数列
python3.4的itertools模块提供了19个生成器函数。例如,itertools.count函数返回的生成器能生成多个数。如果不传入参数,itertools.count函数会生成从零开始的整数数列,也可以提供start和step值,可以生成等差数列生成器,如下所示:

但是itertools.count函数是不能指定end的,即不能停止,如果调用list(count),python会创建一个特别大的列表,超出可用内存。
itertools.takewhile函数可以生成一个使用另一个生成器的生成器,在指定的条件计算结果为False时停止。可以把takewhile和count函数一起 使用,如下,takewhile第二个参数是一个生成器,其生成的内容传入第一个参数(同时也是takewhile返回的生成器的生成值),第一个参数是一个返回布尔值的函数,当其返回值为False时,则停止产出元素。
![]()
下边例子是使用takewhile和count实现的等差数列生成器函数:

该例中arirprog不是生成器函数,因为定义体中没有yield关键字,但是它会返回一个生成器,因此它与生成器函数一样,都是生成器工厂函数。
九、标准库中的生成器函数
python标准库提供了很多生成器,有用于逐行迭代纯文本文件的对象,还有出色的os.walk函数。这个函数在遍历目录树的过程中产出文件名,因此递归搜索文件系统像for循环那样简单。
本节关注通用的生成器函数:参数为任意的可迭代对象,返回值是生成器,用于生成选中的、计算出的和重新排列的元素。按函数的高阶功能进行分组介绍。
第一组:用于过滤的生成器函数
从输入的可迭代对象中产出元素的子集,而不修改元素本身。如同itertools.takewhile函数一样,大多数用于过滤的生成器函数都接受一个断言参数,该参数是个布尔函数,有一个参数,会应用到输入中的每个元素上,用于判断是否将元素包含在输出中。
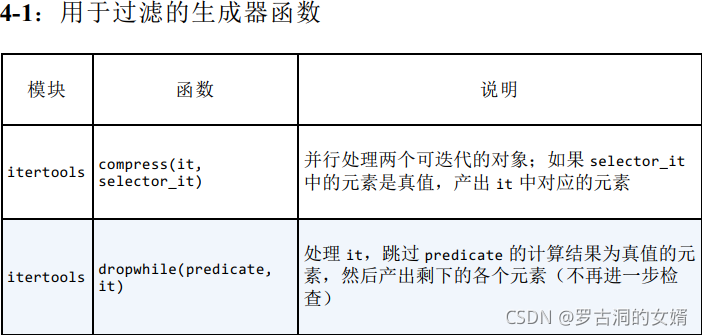

下面是控制台中演示各个用于过滤的生成器函数的用法:

注意dropwhile是一直跳过满足条件的元素,然后当遇到第一个不满足条件的元素以后就不再检查以后的元素,而是直接产出,因为上边例子中跳过了Aa,当遇到r时不满足条件了,因此从r开始全部产出。
第二组:用于映射的生成器函数
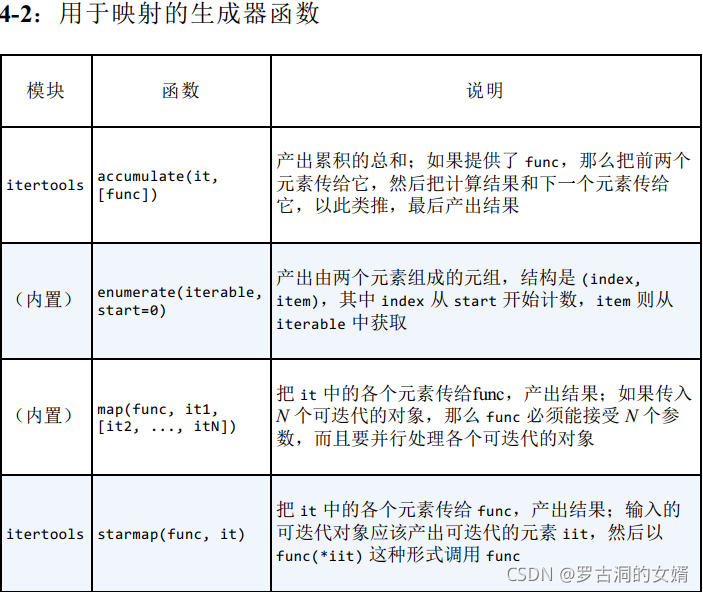
如果输入来自多个可迭代的对象,第一个可迭代的对象到头后就停止输出。


- 计算总和
- 计算最小值
- 计算最大值
- 计算乘积
- 从1!到10!,计算各个数的阶乘
注意在生成器函数accumulate产生的生成器中,第一个元素是直接产出的,因为要保证元素数目与原来的可迭代对象一致吧。
下面演示用于映射的其他生成器函数

- enumerate从1开始,为字符串中每个字母编号,编号与字母组成一个元组。
- 从0到10,计算各个整数的平方。
- 计算两个可迭代对象中对应位置上的两个元素之积,元素最少的那个可迭代对象到头后就停止。
- 作用等同于内置的zip函数,将两个可迭代对象中的元素打包。
- 把enumerate产出的可迭代对象用*拆包作为参数传给mul,然后产生新的元素,这里是将字母重复其对应的索引次。
- accumulate(sample)计算累加和,然后用enumerate从索引1开始超出索引元素对,再进行拆包送入到匿名函数中。
第三组:用于合并的生成器函数
用于合并多个可迭代对象。
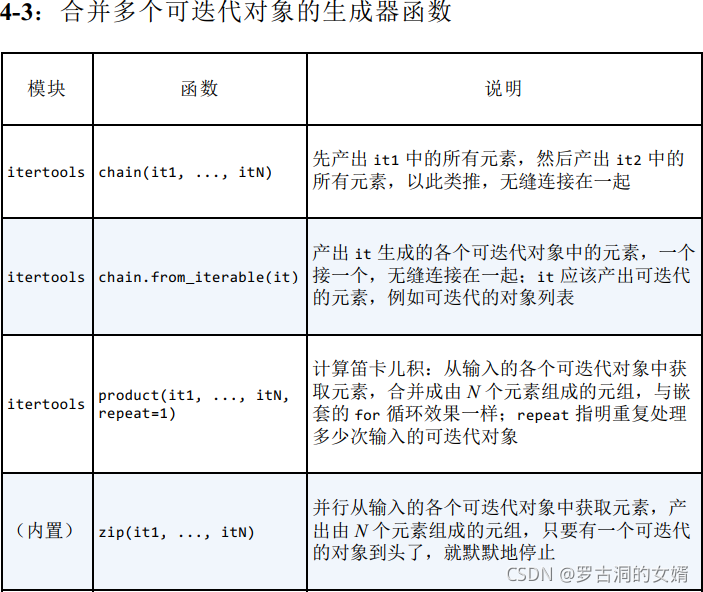

下面例子演示用于合并的生成器函数:

- chain没什么意思,参数是多个可迭代对象,chain函数返回的生成器就是把这些可迭代对象中的元素串起来生成。
- 如果只传入一个可迭代对象,那么chain函数没啥用。
- enumerate()函数返回的生成器生成的对象是元素和索引组成的组合,该组合也是可迭代对象(就是元组),chain.from_iterable把元组也拆开进行产出。
- zip把两个可迭代对象合并成一系列由两个元素组成的元组。
- zip可以处理任意数量个可迭代对象,但是只要有一个可迭代对象到头了,生成器就停止。
- itertools.zip_longest函数的作用与zip类似,不过输入的所有可迭代对象都可以处理到头,如果有些提前用完则会填充None。
- fillvalue关键字用于指定填充的值。
itertools.product生成器函数是计算笛卡尔积的惰性方式:

- 三个字符的字符串和两个整数的值域得到的笛卡尔积是六个元组,因为3 * 2 = 6。
- 两张牌(‘AK’)与四种花色得到的笛卡尔积是八个元组。
- 如果只传入一个可迭代对象,product函数产出的是一系列只有一个元素的元组,没啥用。
- repeat=N关键字参数告诉product函数重复N次处理输入的各个可迭代对象。
第四组:用于扩展输入的可迭代对象的生成器函数
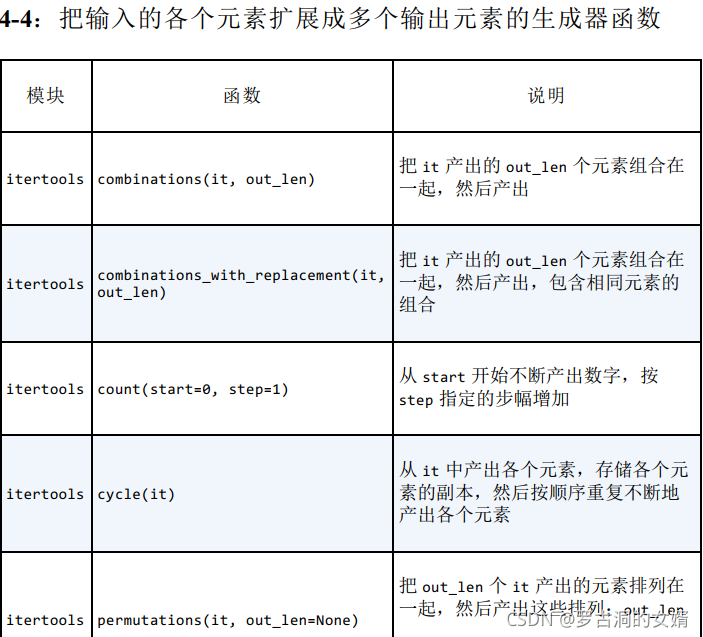

itertools模块中的count和repeat函数返回的生成器可以无中生有:即不接受可迭代对象作为参数。cycle生成器会备份输入的可迭代对象,然后重复产出对象中的元素。

- 使用count函数构建生成器ct,没有给count函数传入参数。
- 因为没有给count函数传入参数,因此默认从0开始产出。
- 使用生成器ct依次产出元素。
- 用islice对count作了限制,这个时候可以构建列表,但是不能直接用ct构建列表,因为ct是无穷的。
- 使用‘ABC’构建一个生成器cy,然后获取其第一个元素。
- 这里也是使用islice进行了限制,才能构建列表,否则cy也是无穷的。
- 构建一个repeat生成器,始终产出数字7。
- 传入times参数可以限制repeat生成器生成的元素数量,这里生成4次数字8。
- repeat函数的常见用途:为map函数提供固定参数,这里提供的是乘数5。
combinations、comb、permutations生成器函数,连同product函数,称为组合学生成器。

- combinations将‘ABC’中的元素每两个凑成一个元组,生成元组中元素的顺序无关紧要。但是生成元组中没有相同元素。
- combinations_with_replacement也将‘ABC’中每两个元素凑成一个元组,但是允许元组包含相同的元素。
- permutations将‘ABC’中每两个元素构成一个元组,且元素在元组中的顺序很重要。
- 用product得到‘ABC’与‘ABC’的笛卡尔积。
第五组:用于重新排列元素的生成器函数
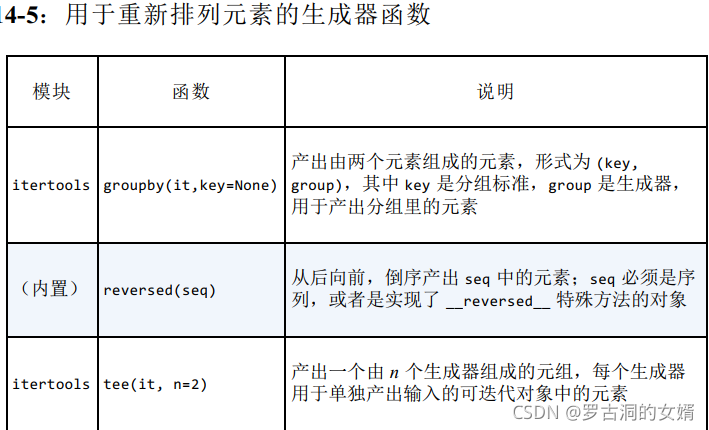
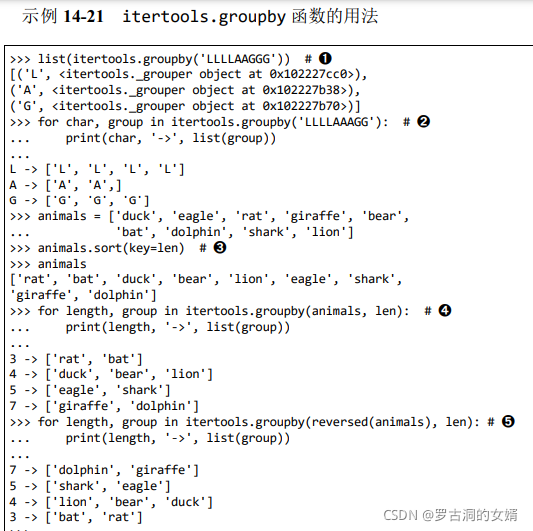
- groupby函数第一个参数是生成器,第二个参数是分类标准,且产出(key, group_generator)这种形式的元组,其中group_generator产生的都是key这个类别的元素。因为这里没有指定分类函数(即分类标准),因此使用相同的元素作为分类标准。注意这里所有相同的元素都在一起,因为itertools.groupby假定输入的可迭代对象要使用分组的标准排序。
- 用char、group将groupby产生的元组拆包,char即key,group即group_generator。
- 为了使用groupby函数,要排序输入,这里按照单词的长度排序。
- 用length、group拆包生成器生成的元素
- 使用reverse生成器从右向左迭代animals。

itertools.tee作用是产生多个生成器,都能生成传入的可迭代对象参数中的元素,默认情况下是产生两个生成器。
十、python3.3出现的新句法:yield from

在chain生成器函数中,it是外层循环迭代到的生成器,内存循环迭代it,用yield i 来产生it中的元素。用yield from 句法可以取代内层循环:

使用yield from 后加上可迭代对象,可以把可迭代对象中的元素一个个yield出来,对比yield来说代码更简洁,不用使用循环来yield元素。
但yield from并不只是一个语法糖,yield from 还会创建通道,把内层生成器直接与外层生成器的客户端联系起来。把生成器当成协程使用时,这个通道特别重要,不仅能为客户端代码生成值,还能使用客户端代码提供的值。
十一、可迭代的规约函数
规约函数都接受一个可迭代的对象,然后返回单个结果。下边列出的每个内置函数都可以使用functools.reduce函数实现,内置是因为它们便于解决常见的问题。此外,对all和any函数来说,相比reduce函数有优化,即这两个函数会短路,一旦确定结果就立即停止使用迭代器。
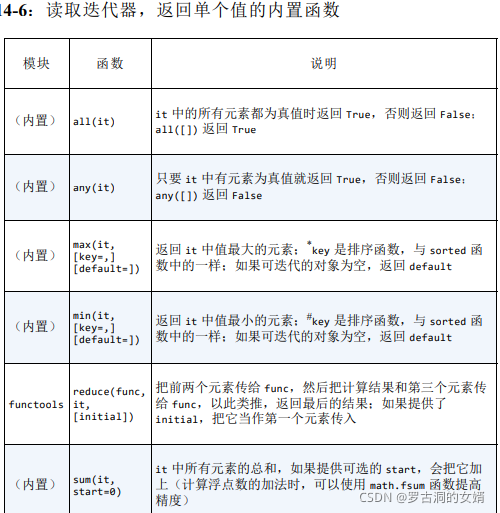
sorted:虽然sorted不是生成器函数,但是因为太重要还是放在这里对比。内置函数sorted可以接受任意的可迭代对象(当然,必须是最终会停止的可迭代对象,否则函数会一直收集元素永远无法返回结果),sorted会构建并返回真正的列表,毕竟要读取可迭代对象中的每一个元素才能够排序,而且排序的对象是列表。
十二、深入分析iter函数
在python中迭代对象x时会调用iter(x)。
iter函数还有一个鲜为人知的用法:传入两个参数,使用普通函数或任何可调用对象创建迭代器。第一个参数必须是可调用对象,用于不断调用(没有参数),产出各个值;第二个值是哨符,即标记值,当第一个参数,即可调用对象返回这个值时,触发迭代器抛出StopIteration异常,而不产出哨符。

十三、略
十四、把生成器当成协程
略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









